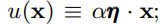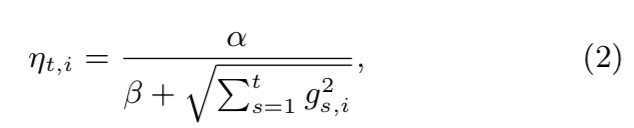前言
学习神经网络的时候我们总是听到激活函数这个词,而且很多资料都会提到常用的激活函数,比如Sigmoid函数、tanh函数、Relu函数。在经过一段时间学习后,决定记录个人学习笔记。
一、激活函数
1.激活函数定义?
在神经网络中,输入经过权值加权计算并求和之后,需要经过一个函数的作用,这个函数就是激活函数(Activation Function)。
2.激活函数的目的?
首先我们需要知道,如果在神经网络中不引入激活函数,那么在该网络中,每一层的输出都是上一层输入的线性函数,无论最终的神经网络有多少层,输出都是输入的线性组合;其一般也只能应用于线性分类问题中,例如非常典型的多层感知机。若想在非线性的问题中继续发挥神经网络的优势,则此时就需要通过添加激活函数来对每一层的输出做处理,引入非线性因素,使得神经网络可以逼近任意的非线性函数,进而使得添加了激活函数的神经网络可以在非线性领域继续发挥重要作用!
更进一步的,激活函数在神经网络中的应用,除了引入非线性表达能力,其在提高模型鲁棒性、缓解梯度消失问题、将特征输入映射到新的特征空间以及加速模型收敛等方面都有不同程度的改善作用!
二、目前常见的几种激活函数
常见的激活函数主要包括如下几种:Sigmoid、tanh、ReLU、ReLU6及变体P-R-Leaky、ELU、SELU、Swish、Mish、Maxout、hard-sigmoid、hard-swish。
下面将分别其分为饱和激活函数和非饱和激活函数进行介绍与分析。
1.饱和激活函数
(以Tanh,Sigmoid和hard-Sigmoid函数为主)
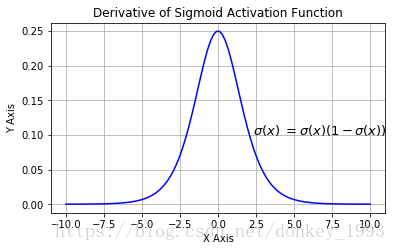
Sigmoid
Sigmoid函数的数学表达式如下:
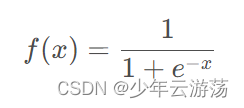
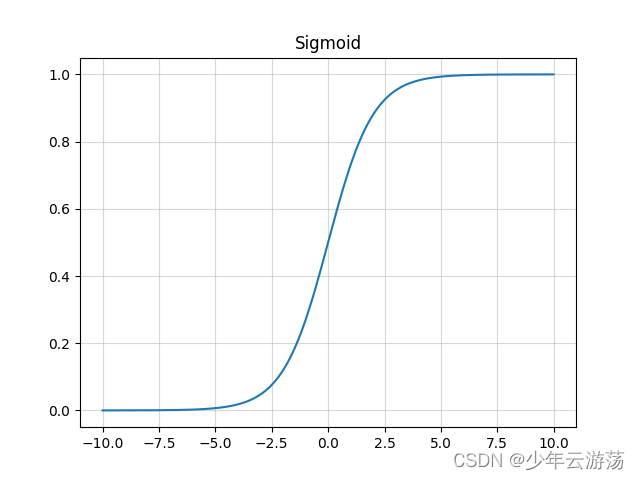
如图所示,即为sigmoid函数,可以看到,它的值域在0~1之间;此类激活函数的优缺点如下:
优点:
1、将很大范围内的输入特征值压缩到0~1之间,使得在深层网络中可以保持数据幅度不会出现较大的变化,而Relu函数则不会对数据的幅度作出约束;
2、在物理意义上最为接近生物神经元;
3、根据其输出范围,该函数适用于将预测概率作为输出的模型;
缺点:
1、当输入非常大或非常小的时候,输出基本为常数,即变化非常小,进而导致梯度接近于0;
2、输出不是0均值,进而导致后一层神经元将得到上一层输出的非0均值的信号作为输入。随着网络的加深,会改变原始数据的分布趋势;
3、梯度可能会过早消失,进而导致收敛速度较慢,例如与Tanh函数相比,其就比sigmoid函数收敛更快,是因为其梯度消失问题较sigmoid函数要轻一些;
4、幂运算相对耗时。
Tanh
Tanh函数的数学表达式如下:
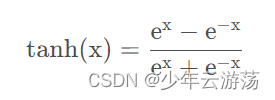
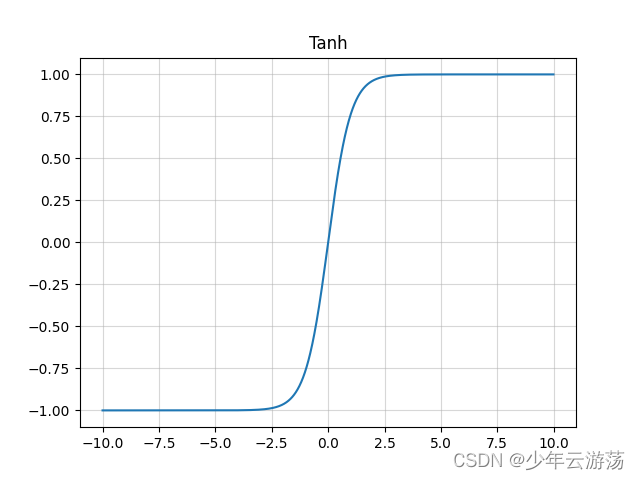
如图所示,即为Tanh函数;在下图中与Sigmoid函数对比,可见这两种激活函数均为饱和激活函数,该函数的输出范围在-1~1之间,其优缺点总结如下:
优点:
1、解决了上述的Sigmoid函数输出不是0均值的问题;
2、Tanh函数的导数取值范围在01之间,优于sigmoid函数的00.25,一定程度上缓解了梯度消失的问题;
3、Tanh函数在原点附近与y=x函数形式相近,当输入的激活值较低时,可以直接进行矩阵运算,训练相对容易;
缺点:
1、与Sigmoid函数类似,梯度消失问题仍然存在;
2、观察其两种形式的表达式,即2*sigmoid(2x)-1与(exp(x)-exp(x))/(exp(x)+exp(-x)),可见,幂运算的问题仍然存在;
2. 非饱和激活函数
(以ReLU、ReLU6及变体P-R-Leaky、ELU、Swish、Mish、Maxout、hard-sigmoid、hard-swish为主)
Relu
Relu函数的数学表达式如下:
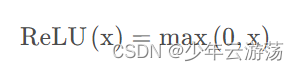
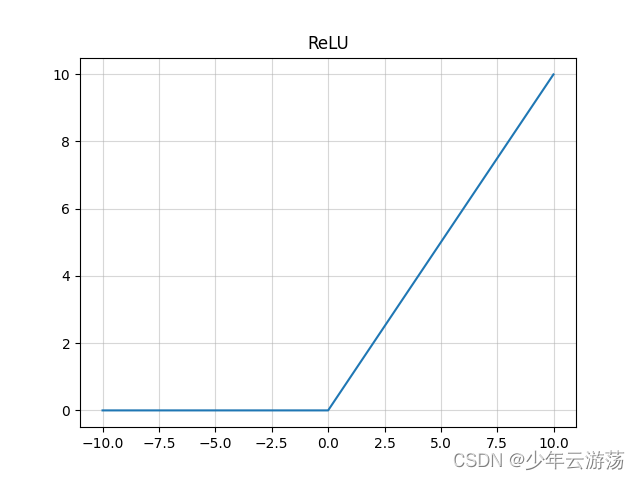
上图即为Relu函数的曲线图,可见在输入为负值时,输出均为0值,在输入大于0的区间,输出y=x,可见该函数并非全区间可导的函数;其优缺点总结如下:
优点:
1、相较于sigmoid函数以及Tanh函数来看,在输入为正时,Relu函数不存在饱和问题,即解决了gradient vanishing问题,使得深层网络可训练;
2、计算速度非常快,只需要判断输入是否大于0值;
3、收敛速度远快于sigmoid以及Tanh函数;
4、Relu输出会使一部分神经元为0值,在带来网络稀疏性的同时,也减少了参数之间的关联性,一定程度上缓解了过拟合的问题;
缺点:
1、Relu函数的输出也不是以0为均值的函数;
2、存在Dead Relu Problem,即某些神经元可能永远不会被激活,进而导致相应参数一直得不到更新,产生该问题主要原因包括参数初始化问题以及学习率设置过大问题;
3、当输入为正值,导数为1,在“链式反应”中,不会出现梯度消失,但梯度下降的强度则完全取决于权值的乘积,如此可能会导致梯度爆炸问题;
ReLU6
Relu函数的数学表达式如下:
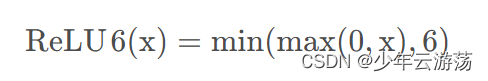
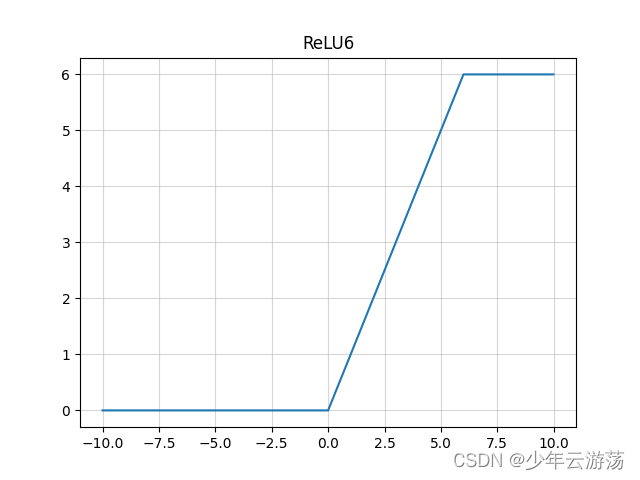
上图即为Relu6函数的示意图,在x大于等于6时,y的值会被限定;其优缺点类似于relu。
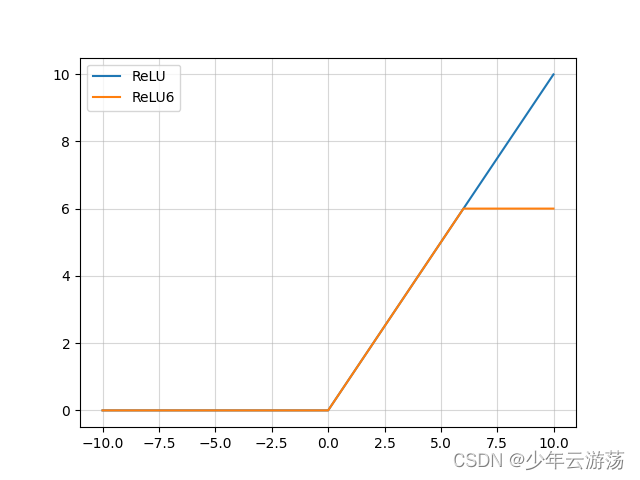
ReLU6就是普通的ReLU但是限制最大输出为6,用在MobilenetV1网络当中。目的是为了适应float16/int8 的低精度需要。上图是relu6和relu之间的关系。
优点:
1.ReLU6具有ReLU函数的优点;
2.该激活函数可以在移动端设备使用float16/int8低精度的时候也能良好工作。如果对 ReLU 的激活范围不加限制,激活值非常大,则低精度的float16/int8无法很好地精确描述如此大范围的数值,带来精度损失。
缺点:
1.与ReLU缺点类似。
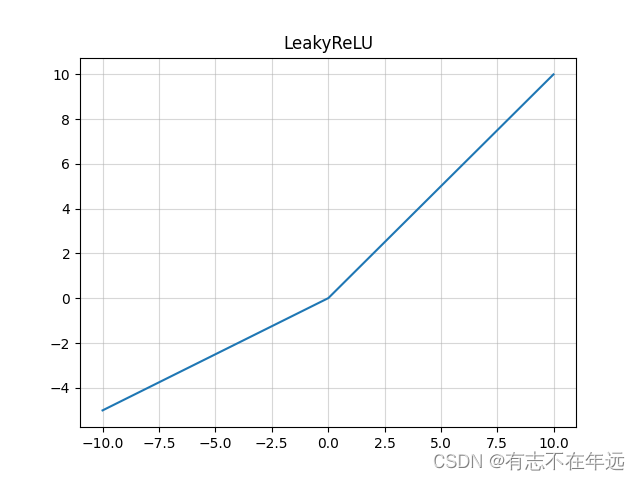
LeakyReLU
LeakyReLU函数的数学表达式如下:
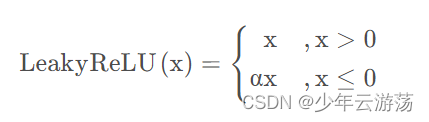

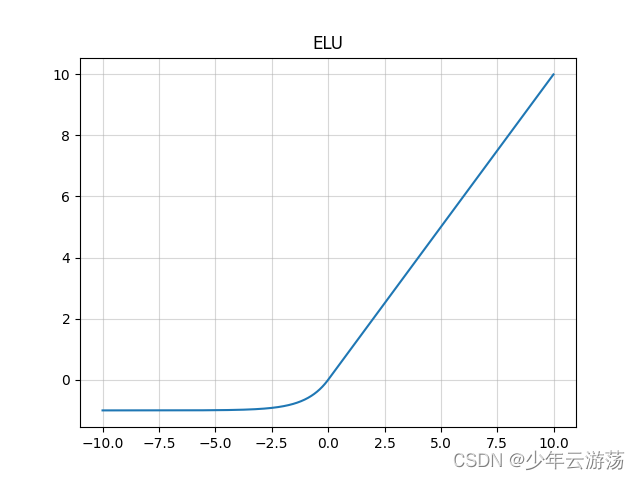
图中所示即为ELU函数,其也是Relu函数的一种变体,x大于0时,y=x,x小于等于0时,y=α(exp(x)-1),可看作介于Relu与Leaky Relu之间的函数;其优缺点总结如下:
优点:
1、ELU具有Relu的大多数优点,不存在Dead Relu问题,输出的均值也接近为0值;
2、该函数通过减少偏置偏移的影响,使正常梯度更接近于单位自然梯度,从而使均值向0加速学习;
3、该函数在负数域存在饱和区域,从而对噪声具有一定的鲁棒性;
缺点:
1、计算强度较高,含有幂运算;
2、在实践中同样没有较Relu更突出的效果,故应用不多。
Swish
Swish函数的数学表达式如下:
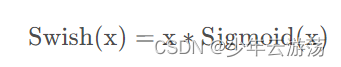
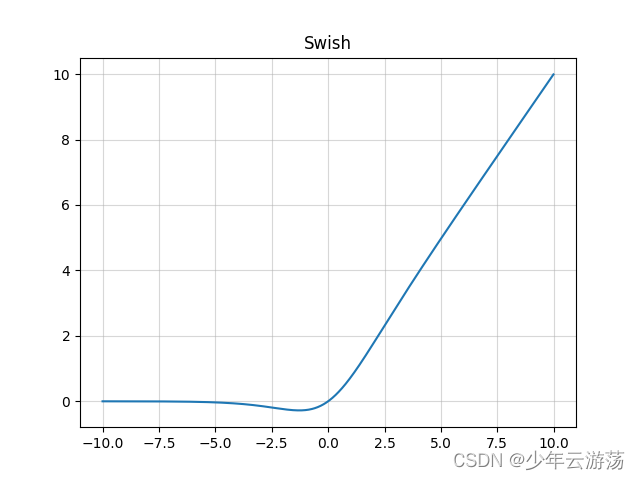
上图所示即为Swish函数,Swish是Sigmoid和ReLU的改进版,类似于ReLU和Sigmoid的结合,β是个常数或可训练的参数。Swish 具备无上界有下界、平滑、非单调的特性。Swish 在深层模型上的效果优于 ReLU。其优缺点总结如下:
优点:
1.Swish具有一定ReLU函数的优点;
2.Swish具有一定Sigmoid函数的优点;
3.Swish函数可以看做是介于线性函数与ReLU函数之间的平滑函数。
缺点:
1.运算复杂,速度较慢。
Mish
Mish函数的数学表达式如下:
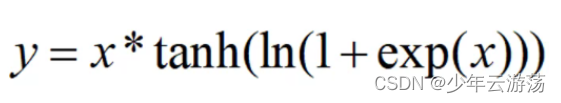
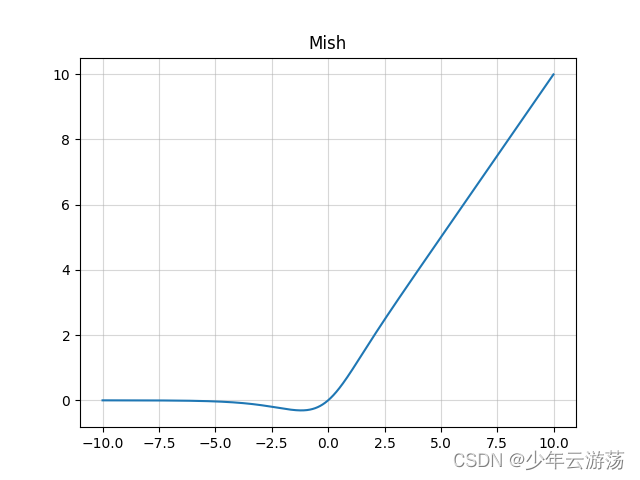
图中所示即为Mish函数,Mish与Swish激活函数类似,Mish具备无上界有下界、平滑、非单调的特性。Mish在深层模型上的效果优于 ReLU。无上边界可以避免由于激活值过大而导致的函数饱和。
优点:
1.正值以上无边界(即正值可以达到任何高度)避免了由于封顶而导致的饱和。理论上对负值的轻微允许允许更好的梯度流,而不是像ReLU中那样的硬零边界。
2.平滑的激活函数允许更好的信息深入神经网络,从而得到更好的准确性和泛化。
缺点:
1.计算量肯定比relu大,占用的内存也多了不少;
Maxout
Maxout函数的数学表达式如下:
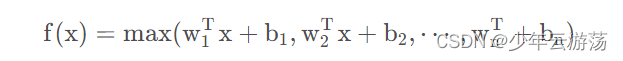
maxout激活函数其本质是对所有out作max操作,又被称为大一统的激活函数,因为maxout网络能够近似任意连续函数,且当w2,b2,…,wn,bn为0时,退化为ReLU。Maxout能够缓解梯度消失,同时又规避了ReLU神经元死亡的缺点,但增加了参数和计算量。
此外maxout激活函数并不是一个固定的函数,不像Sigmod、Relu、Tanh等函数,是一个固定的函数方程。它是一个可学习的激活函数,因为我们 W 参数是学习变化的。Maxout单元不但是净输入到输出的非线性映射,而是整体学习输入到输出之间的非线性映射关系,可以看做任意凸函数的分段线性近似,并且在有限的点上是不可微的。
优点:
1.Maxout的拟合能力非常强,可以拟合任意的凸函数。
2.Maxout具有ReLU的所有优点,线性、不饱和性。
3.同时没有ReLU的一些缺点。如:神经元的死亡。
缺点:
1.激活函数公式中可以看出,每个神经元中有两组(w,b)参数,那么参数量就增加了一倍,这就导致了整体参数的数量激增。
hard-sigmoid
hard-sigmoid函数的数学表达式如下:
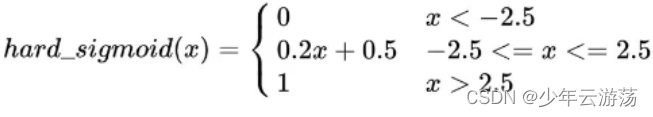
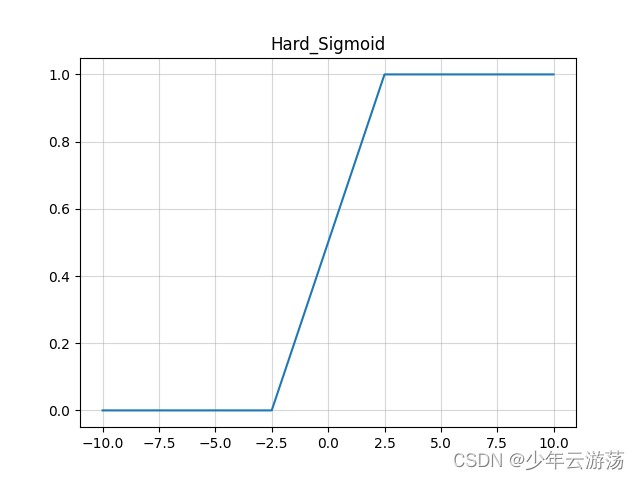
Hard sigmoid 是一种对于 sigmoid 的近似,主要优势是计算速度快,无需幂计算,所以当对对于速度要求高的情况下,hard sigmoid 是一种选择。在具体的实现形式上有多种方式,比如 pytorch 和 tensorflow 中的实现方式就有差别,但是总之都是对于 sigmoid 的一种近似。总的来说计算速度比sigmoid快,因为没有指数运算。
优点:
1.输出为(0,1),可以表示为概率单调、连续。
缺点:
1.梯度软饱和。
2.输出不为0均值,不利于优化。
3.包含指数计算,速度慢。
Hard-swish
Hard-sigmoid函数的数学表达式如下:
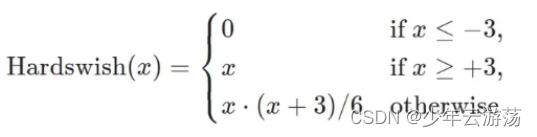
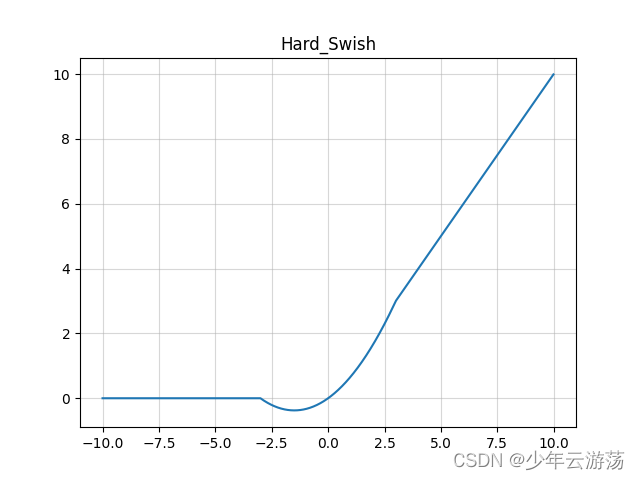
最早MobileNetV3 作者使用hard-Swish和hard-Sigmoid替换了ReLU6和SE-block中的Sigmoid层,但是只是在网络的后半段才将ReLU6替换为h-Swish,因为作者发现Swish函数只有在更深的网络层使用才能体现其优势。
解决的问题
1.用分段线性函数代替Swish,提高了计算效率。
2.在MobileNetV3网络的深层用Hard-Swish代替了ReLU6,保证模型低计算量的同时,提高了模型精度。
三、激活函数代码
import matplotlib.pyplot as plt
import numpy as npclass ActivateFunc():def __init__(self, x, b=1, lamb=2, alpha=1, a=2):super(ActivateFunc, self).__init__()self.x = xself.b = bself.lamb = lambself.alpha = alphaself.a = adef __init__(self, x, b=1, lamb=2, alpha=1, a=2):super(ActivateFunc, self).__init__()self.x = xself.b = bself.lamb = lambself.alpha = alphaself.a = adef Sigmoid(self):y = np.exp(self.x) / (np.exp(self.x) + 1)y_grad = y*(1-y)return [y, y_grad]def Tanh(self):y = np.tanh(self.x)y_grad = 1 - y * yreturn [y, y_grad]def Swish(self): #b是一个常数,指定by = self.x * (np.exp(self.b*self.x) / (np.exp(self.b*self.x) + 1))y_grad = np.exp(self.b*self.x)/(1+np.exp(self.b*self.x)) + self.x * (self.b*np.exp(self.b*self.x) / ((1+np.exp(self.b*self.x))*(1+np.exp(self.b*self.x))))return [y, y_grad]def ELU(self): # alpha是个常数,指定alphay = np.where(self.x > 0, self.x, self.alpha * (np.exp(self.x) - 1))y_grad = np.where(self.x > 0, 1, self.alpha * np.exp(self.x))return [y, y_grad]def SELU(self): # lamb大于1,指定lamb和alphay = np.where(self.x > 0, self.lamb * self.x, self.lamb * self.alpha * (np.exp(self.x) - 1))y_grad = np.where(self.x > 0, self.lamb*1, self.lamb * self.alpha * np.exp(self.x))return [y, y_grad]def ReLU(self):y = np.where(self.x < 0, 0, self.x)y_grad = np.where(self.x < 0, 0, 1)return [y, y_grad]def PReLU(self): # a大于1,指定ay = np.where(self.x < 0, self.x / self.a, self.x)y_grad = np.where(self.x < 0, 1 / self.a, 1)return [y, y_grad]def LeakyReLU(self): # a大于1,指定ay = np.where(self.x < 0, self.x / self.a, self.x)y_grad = np.where(self.x < 0, 1 / self.a, 1)return [y, y_grad]def Mish(self):f = 1 + np.exp(x)y = self.x * ((f*f-1) / (f*f+1))y_grad = (f*f-1) / (f*f+1) + self.x*(4*f*(f-1)) / ((f*f+1)*(f*f+1))return [y, y_grad]def ReLU6(self):y = np.where(np.where(self.x < 0, 0, self.x) > 6, 6, np.where(self.x < 0, 0, self.x))y_grad = np.where(self.x > 6, 0, np.where(self.x < 0, 0, 1))return [y, y_grad]def Hard_Swish(self):f = self.x + 3relu6 = np.where(np.where(f < 0, 0, f) > 6, 6, np.where(f < 0, 0, f))relu6_grad = np.where(f > 6, 0, np.where(f < 0, 0, 1))y = self.x * relu6 / 6y_grad = relu6 / 6 + self.x * relu6_grad / 6return [y, y_grad]def Hard_Sigmoid(self):f = (2 * self.x + 5) / 10y = np.where(np.where(f > 1, 1, f) < 0, 0, np.where(f > 1, 1, f))y_grad = np.where(f > 0, np.where(f >= 1, 0, 1 / 5), 0)return [y, y_grad]def PlotActiFunc(x, y, title):plt.grid(which='minor', alpha=0.2)plt.grid(which='major', alpha=0.5)plt.plot(x, y)plt.title(title)plt.show()def PlotMultiFunc(x, y):plt.grid(which='minor', alpha=0.2)plt.grid(which='major', alpha=0.5)plt.plot(x, y)if __name__ == '__main__':x = np.arange(-10, 10, 0.01)activateFunc = ActivateFunc(x)activateFunc.b = 1PlotActiFunc(x, activateFunc.Sigmoid()[0], title='Sigmoid')PlotActiFunc(x, activateFunc.Tanh()[0], title='Tanh')PlotActiFunc(x, activateFunc.ReLU()[0], title='ReLU')PlotActiFunc(x, activateFunc.LeakyReLU()[0], title='LeakyReLU')PlotActiFunc(x, activateFunc.ReLU6()[0], title='ReLU6')PlotActiFunc(x, activateFunc.Swish()[0], title='Swish')PlotActiFunc(x, activateFunc.Mish()[0], title='Mish')PlotActiFunc(x, activateFunc.ELU()[0], title='ELU')PlotActiFunc(x, activateFunc.Hard_Swish()[0], title='Hard_Swish')PlotActiFunc(x, activateFunc.Hard_Sigmoid()[0], title='Hard_Sigmoid')plt.figure(1)PlotMultiFunc(x, activateFunc.Swish()[0])PlotMultiFunc(x, activateFunc.Mish()[0])plt.legend(['Swish', 'Mish'])plt.figure(2)PlotMultiFunc(x, activateFunc.Swish()[0])PlotMultiFunc(x, activateFunc.Hard_Swish()[0])plt.legend(['Swish', 'Hard-Swish'])plt.figure(3)PlotMultiFunc(x, activateFunc.Sigmoid()[0])PlotMultiFunc(x, activateFunc.Hard_Sigmoid()[0])plt.legend(['Sigmoid', 'Hard-Sigmoid'])plt.figure(4)PlotMultiFunc(x, activateFunc.ReLU()[0])PlotMultiFunc(x, activateFunc.ReLU6()[0])plt.legend(['ReLU', 'ReLU6'])plt.show()参考:最全面:python绘制Sigmoid、Tanh、Swish、ELU、SELU、ReLU、ReLU6、Leaky ReLU、Mish、hard-Sigmoid、hard-Swish等激活函数(有源码)
常用激活函数:Sigmoid、Tanh、Relu、Leaky Relu、ELU优缺点总结