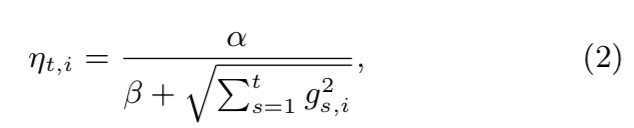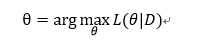日萌社
日萌社
人工智能AI:Keras PyTorch MXNet TensorFlow PaddlePaddle 深度学习实战(不定时更新)
5.8 排序模型进阶-FM&FTRL
学习目标
- 目标
- 无
- 应用
- 无
5.8.1 问题
在实际项目的时候,经常会遇到训练数据非常大导致一些算法实际上不能操作的问题。比如在推荐行业中,因为请求数据量特别大,一个星期的数据往往有上百G,这种级别的数据在训练的时候,直接套用一些算法框架是没办法训练的,基本上在特征工程的阶段就一筹莫展。
5.8.2 FM的隐向量
FM和FFM模型是最近几年提出的模型,凭借其在数据量比较打并且特征稀疏的情况下,忍让能够得到优秀的性能和效果,屡次在各大公司举办的CTR预估比赛中获得不错的战绩。我们回到之前所说的特征交叉,下面这个问题。
5.8.2.1 FM的原理及推导
因子分解机(Factorization Machine,简称FM),又称分解机。是由德国康斯坦茨大学的Steffen Rendle(现任职于Google)于2010年最早提出的,旨在解决大规模稀疏数据下的特征组合问题。在系统介绍FM之前,先了解一下在实际场景中,稀疏数据是怎样产生的。
假设一个广告分类的问题,根据用户和广告位相关的特征,预测用户是否点击了广告。元数据如下:
| Clicked? | Country | Day | Ad_type |
|---|---|---|---|
| 1 | USA | 26/11/15 | Movie |
| 0 | China | 1/7/14 | Game |
| 1 | China | 19/2/15 | Game |
“Clicked?”是label,Country、Day、Ad_type是特征。由于三种特征都是categorical类型的,需要经过独热编码(One-Hot Encoding)转换成数值型特征。
| Clicked? | Country=USA | Country=China | Day=26/11/15 | Day=1/7/14 | Day=19/2/15 | Ad_type=Movie | Ad_type=Game |
|---|---|---|---|---|---|---|---|
| 1 | 1 | 0 | 1 | 0 | 0 | 1 | 0 |
| 0 | 0 | 1 | 0 | 1 | 0 | 0 | 1 |
| 1 | 0 | 1 | 0 | 0 | 1 | 0 | 1 |
由上表可以看出,经过One-Hot编码之后,大部分样本数据特征是比较稀疏的。上面的样例中,每个样本有7维特征,但平均仅有3维特征具有非零值。实际上,这种情况并不是此例独有的,在真实应用场景中这种情况普遍存在。例如,CTR/CVR预测时,用户的性别、职业、教育水平、品类偏好、商品的品类等,经过One-Hot编码转换后都会导致样本数据的稀疏性。
- 数据稀疏性是实际问题中不可避免的挑战。
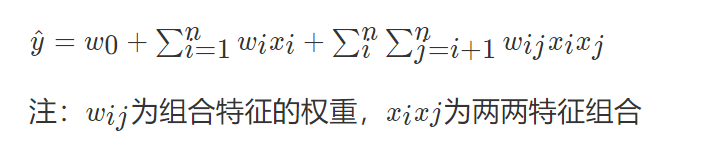
理解:
- 1、即xi,xj(都是one-hot特征)同时为1时可能是一个很有用的特征,这种组合特征是xi和xj的线性组合所无法表示的。这样一来乘积xi,xi就成一个新的特征。为了不错过任何一个这种可能有用的组合特征,我们穷举所有的i,j组合,把xi,xj。1 ≤i ≤n,i
-
2、而在这里交叉项的每一个参数wij的学习过程需要大量的xi、xj同时非零的训练样本数据。由于样本数据本来就很稀疏,能够满足“xi和xj都非零”的样本数就会更少。
-
训练参数:由于二次项系数w_{ij}wij的引入,由于组合特征数量过大,在数据稀疏性普遍存在的实际应用场景中,二次项参数的训练是很困难的
FM的公式(Factorization Machine)
有没有什么办法可以减少参数?矩阵分解提供了一种解决思路!!
再来观察二次项系数矩阵w_{ij},它应该是NXN大小的矩阵。同时它是稀疏的,因为绝大部分的组合特征都是无用的,所以其系数应该为0。



5.8.3 在线优化算法-Online-learning
In computer science, online machine learning is a method of machine learning in which data becomes available in a sequential order and is used to update our best predictor for future data at each step, as opposed to batch learning techniques which generate the best predictor by learning on the entire training data set at once.
在工业界,不单参与训练的数据量大,模型特征量的规模也大。比如点击率预估,往往特征规模会在亿级别,训练数据很容易过TB,对资源的压力很大。最优化求解问题可能是我们在工作中遇到的最多的一类问题了:从已有的数据中提炼出最适合的模型参数,从而对未知的数据进行预测。当我们面对高维高数据量的场景时,常见的批量处理的方式已经显得力不从心,需要有在线处理的方法来解决此类问题。
准确地说,Online Learning并不是一种模型,而是一种模型的训练方法,Online Learning能够根据线上反馈数据,实时快速地进行模型调整,使得模型及时反映线上的变化,提高线上预测的准确率。Online Learning的流程包括:将模型的预测结果展现给用户,然后收集用户的反馈数据,再用来训练模型,形成闭环的系统。如下图所示:
比较出名的在线最优化的方法有:
- TG(Truncated Gradient)
- FOBOS(Forward-Backward Splitting)
- RDA(Regularized Dual Averaging)
- FTRL(Follow the Regularized Leader)
SGD算法是常用的online learning算法,它能学习出不错的模型,但学出的模型不是稀疏的。为此,学术界和工业界都在研究这样一种online learning算法,它能学习出有效的且稀疏的模型
5.8.4 Follow The Regularized Leader(FTRL)
- 一种获得稀疏模型并且防止过拟合的优化方法
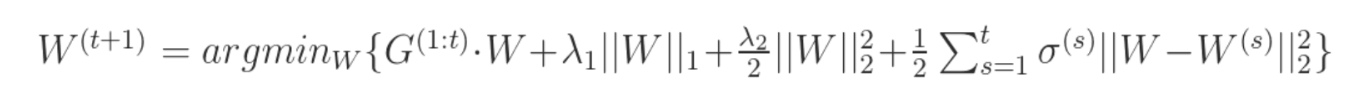
正则化(Regularization)
正则化,即在成本函数中加入一个正则化项(惩罚项),惩罚模型的复杂度,防止网络过拟合
L1与L2正则化
逻辑回归的参数W数量根据特征的数量而定,那么正则化如下
- 逻辑回归的损失函数中增加L2正则化

正则化项的理解
在损失函数中增加一项,那么其实梯度下降是要减少损失函数的大小,对于L2或者L1来讲都是要去减少这个正则项的大小,那么也就是会减少W权重的大小。这是我们一个直观上的感受。
- 接下来我们通过方向传播来理解这个其中的L2,对于损失函数我们要反向传播求参数梯度:

FTRL算法的设计思想其实并不复杂,就是每次找到让之前所有目标函数(损失函数加正则项)之和最小的参数。该算法在处理诸如逻辑回归之类的带非光滑正则化项(如L1正则项)的凸优化问题上表现出色,在计算精度和特征的稀疏性上做到了很好的trade-off,而且在工程实现上做了大量优化,性能优异。
- 正则项:众所周知,目标函数添加L1正则项可增加模型解的稀疏性,添加L2正则项有利于防止模型过拟合。也可以将两者结合使用,即混合正则,FTRL就是这样设计的。
- 稀疏性:模型解的稀疏性在机器学习中是很重要的,尤其是在工程应用领域。稀疏的模型解会大大减少预测时的内存和时间复杂度。常用的稀疏性方法包括:
5.8.3 案例:美国普查数据-FTRL使用效果对比
TensorFlow FTRL 读取训练
- 算法参数
- lambda1:L1正则系数,参考值:10 ~ 15
- lambda2:L2正则系数,参考值:10 ~ 15
- alpha:FTRL参数,参考值:0.1
- beta:FTRL参数,参考值:1.0
- batchSize: mini-batch的大小,参考值:10000
-
性能评测
- 设置参数:
- lambda1 = 15,lambda2 = 15, alpha = 0.1, beta = 1.0
- 设置参数:
-
使用FTRL算法训练模型
classifiry = tf.estimator.LinearClassifier(feature_columns=feature_cl,optimizer=tf.train.FtrlOptimizer(learning_rate=0.01,l1_regularization_strength=10,l2_regularization_strength=15,))
但是会发现,加上正则化之后效果并不一定得到显著提升,这也是在于FTRL更适合大量的稀疏特征和大量数据场景。(下面都只是在epoch=3,batch=32的条件下得出的,可以让训练一直进行,在Tensorboard中查看效果)
| 普查数据模型 | baseline | Feature intersection | FTRL |
|---|---|---|---|
| accuracy | 0.8323813 | 0.8401818 | 0.9046435 |
| auc | 0.87850624 | 0.89078486 | 0.5774169 |
5.8.4 离线数据训练FTRL模型
- 目的:通过离线TFRecords样本数据,训练FTRL模型
- 步骤:
- 1、构建TFRecords的输入数据
- 2、使用模型进行特征列指定
- 3、模型训练以及预估
1、构建TFRecords的输入数据
- feature: 121列值,1channel_id, 100 vector, 10user_weights, 10 article_weights
- (1)给每个值指定一个类型
- (2)后面给了三种读取处理方式,以及训练时的特征形状
- 解析example:tf.parse_single_example(example_proto, features)
- features = { "label": tf.FixedLenFeature([], tf.int64), "feature": tf.FixedLenFeature([], tf.string) }
- 针对每一个样本指定,string类型需要解析
- tf.decode_raw(parsed_features['feature'], tf.float64)
FEATURE_COLUMNS = ['channel_id', 'vector', 'user_weights', 'article_weights']@staticmethod
def read_ctr_records():# 定义转换函数,输入时序列化的def parse_tfrecords_function(example_proto):features = {"label": tf.FixedLenFeature([], tf.int64),"feature": tf.FixedLenFeature([], tf.string)}parsed_features = tf.parse_single_example(example_proto, features)feature = tf.decode_raw(parsed_features['feature'], tf.float64)feature = tf.reshape(tf.cast(feature, tf.float32), [1, 121])# 特征顺序 1 channel_id, 100 article_vector, 10 user_weights, 10 article_weights# 1 channel_id类别型特征, 100维文章向量求平均值当连续特征,10维用户权重求平均值当连续特征channel_id = tf.cast(tf.slice(feature, [0, 0], [1, 1]), tf.int32)vector = tf.reduce_sum(tf.slice(feature, [0, 1], [1, 100]), axis=1)user_weights = tf.reduce_sum(tf.slice(feature, [0, 101], [1, 10]), axis=1)article_weights = tf.reduce_sum(tf.slice(feature, [0, 111], [1, 10]), axis=1)label = tf.cast(parsed_features['label'], tf.float32)# 构造字典 名称-tensortensor_list = [channel_id, vector, user_weights, article_weights]feature_dict = dict(zip(FEATURE_COLUMNS, tensor_list))return feature_dict, labeldataset = tf.data.TFRecordDataset(["./train_ctr_20190605.tfrecords"])dataset = dataset.map(parse_tfrecords_function)dataset = dataset.batch(64)dataset = dataset.repeat(10)return dataset
2、使用模型进行特征列指定
def train_eval(self):"""训练模型:return:"""# 离散分类article_id = tf.feature_column.categorical_column_with_identity('channel_id', num_buckets=25)# 连续类型vector = tf.feature_column.numeric_column('vector')user_weigths = tf.feature_column.numeric_column('user_weigths')article_weights = tf.feature_column.numeric_column('article_weights')feature_columns = [article_id, vector, user_weigths, article_weights]
3、模型训练以及预估
classifiry = tf.estimator.LinearClassifier(feature_columns=feature_columns,optimizer=tf.train.FtrlOptimizer(learning_rate=0.1,l1_regularization_strength=10,l2_regularization_strength=10))
classifiry.train(LrWithFtrl.read_ctr_records, steps=10000)
result = classifiry.evaluate(LrWithFtrl.read_ctr_records)
print(result)
最终效果与之前spark LR模型的效果对比
| 样本模型对比 | baseline | FTRL(3个epoch) |
|---|---|---|
| accuracy | 0.9051438053097345 | 0.9046435 |
| auc | 0.719274521004087 | 0.585196 |
完整代码:
import tensorflow as tfFEATURE_COLUMNS = ['channel_id', 'vector', 'user_weigths', 'article_weights']class LrWithFtrl(object):"""LR以FTRL方式优化"""def __init__(self):pass@staticmethoddef read_ctr_records():# 定义转换函数,输入时序列化的def parse_tfrecords_function(example_proto):features = {"label": tf.FixedLenFeature([], tf.int64),"feature": tf.FixedLenFeature([], tf.string)}parsed_features = tf.parse_single_example(example_proto, features)feature = tf.decode_raw(parsed_features['feature'], tf.float64)feature = tf.reshape(tf.cast(feature, tf.float32), [1, 121])channel_id = tf.cast(tf.slice(feature, [0, 0], [1, 1]), tf.int32)vector = tf.slice(feature, [0, 1], [1, 100])user_weights = tf.slice(feature, [0, 101], [1, 10])article_weights = tf.slice(feature, [0, 111], [1, 10])label = tf.cast(parsed_features['label'], tf.float32)# 构造字典 名称-tensorFEATURE_COLUMNS = ['channel_id', 'vector', 'user_weights', 'article_weights']tensor_list = [channel_id, vector, user_weights, article_weights]feature_dict = dict(zip(FEATURE_COLUMNS, tensor_list))return feature_dict, labeldataset = tf.data.TFRecordDataset(["./ctr_train_20190706.tfrecords"])dataset = dataset.map(parse_tfrecords_function)dataset = dataset.batch(64)dataset = dataset.repeat()return datasetdef train_eval(self):"""训练模型:return:"""# 离散分类article_id = tf.feature_column.categorical_column_with_identity('channel_id', num_buckets=25)# 连续类型vector = tf.feature_column.numeric_column('vector', shape=[1, 100])user_weigths = tf.feature_column.numeric_column('user_weigths', shape=[1, 10])article_weights = tf.feature_column.numeric_column('article_weights', shape=[1, 10])feature_columns = [article_id, vector, user_weigths, article_weights]classifiry = tf.estimator.LinearClassifier(feature_columns=feature_columns,optimizer=tf.train.FtrlOptimizer(learning_rate=0.1,l1_regularization_strength=10,l2_regularization_strength=10))classifiry.train(LrWithFtrl.read_ctr_records)result = classifiry.evaluate(LrWithFtrl.read_ctr_records)print(result)if __name__ == '__main__':lwf = LrWithFtrl()lwf.train_eval()