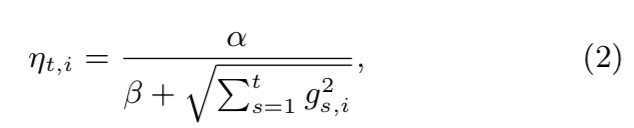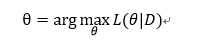契机
最近工作方向为缩减模型规模,切入点为L1正则化,选择该切入点的理由如下,
众所周知,L1正则化能令权重矩阵更稀疏。在推荐系统中特征多为embedding,权重矩阵稀疏意味着一些embedding_weight为0,模型部署时这些embedding不会导出,从而达到缩减模型规模的目的,这样做有3个好处:
- 性能更好:小模型部署快,这点对于实时训练很重要,因为较多时间会花在模型部署上,部署快意味着更快的模型迭代,
- 内存更小:这点毋庸置疑,
- 效果更好:在适当参数配置下,L1正则化干掉的特征一般不重要,这样模型被这些特征干扰的概率降低,效果会更好。
但是,随着随机梯度下降(SGD)的应用,L1正则化后的模型稀疏程度下降,理由正如冯扬大神所述。FTRL正是在这个环境下诞生的,其核心目的在于解决模型稀疏化问题。
备注:下文所有的稀疏性都为权重稀疏性。

发展历程
L1正则化
直接上权重更新公式:
W ( t + 1 ) = W ( t ) − η ( t ) G ( t ) − η ( t ) λ s g n ( W ( t ) ) W^{(t+1)}=W^{(t)}-\eta^{(t)}G^{(t)}-\eta^{(t)}\lambda sgn(W^{(t)}) W(t+1)=W(t)−η(t)G(t)−η(t)λsgn(W(t))
其中 W ( t ) W^{(t)} W(t)代表训练第 t t t步时的权重, η ( t ) \eta ^{(t)} η(t)代表学习率, G ( t ) G^{(t)} G(t)代表梯度, λ \lambda λ代表L1正则化参数, s g n ( ⋅ ) sgn(\cdot) sgn(⋅)为符号函数,这里 s g n ( W ( t ) ) sgn(W_{(t)}) sgn(W(t))为 ∣ W ( t ) ∣ |W_{(t)}| ∣W(t)∣的导数。
简单截断法
既然L1正则化后的权重依然不为0,则直接在让权重在比较小时截断为0,这样在一定程度上直接解决稀疏化问题,具体公式如下,
W ( t + 1 ) = T 0 ( W ( t ) − η ( t ) G ( t ) , θ ) W^{(t+1)}=T_0(W^{(t)}-\eta ^{(t)}G^{(t)},\theta) W(t+1)=T0(W(t)−η(t)G(t),θ)
其中 T 0 ( v i , θ ) T_0(v_i,\theta) T0(vi,θ)为截断函数,具体形式如下,
T 0 ( v i , θ ) = { 0 i f ∣ v i ∣ ≤ θ v i o t h e r w i s e T_0(v_i,\theta)=\left\{\begin{matrix} 0 \ \ \ \ if \ \left | v_i \right | \leq \theta\\ v_i \ \ \ \ otherwise \end{matrix}\right. T0(vi,θ)={0 if ∣vi∣≤θvi otherwise
实际操作时,如果 t / k t/k t/k不为整数时按正常SGD进行迭代,否则则采用上述公式进行权重更新。具体示意图如下所示,

TG
简单截断法太过暴力,参数控制不好效果会有损,之后便诞生了Truncated Gradient算法(简称为TG),具体公式如下,
W ( t + 1 ) = T 1 ( W ( t ) − η ( t ) G ( t ) , η ( t ) λ ( t ) , θ ) W^{(t+1)}=T_1(W^{(t)}-\eta^{(t)}G^{(t)},\eta^{(t)}\lambda^{(t)},\theta) W(t+1)=T1(W(t)−η(t)G(t),η(t)λ(t),θ)
其中 λ ( t ) \lambda^{(t)} λ(t)为另一个限制阈值, T 1 ( v i , α , θ ) T_1(v_i,\alpha,\theta) T1(vi,α,θ)为TG算法的截断函数,具体形式如下,
T 1 ( v i , α , θ ) = { m a x ( 0 , v i − α ) i f v i ∈ [ 0 , θ ] m i n ( 0 , v i + α ) i f v i ∈ [ − θ , 0 ] v i o t h e r w i s e T_1(v_i,\alpha,\theta)=\left\{\begin{matrix} max(0,v_i -\alpha) \ \ \ \ \ \ \ \ \ if \ v_i \in \left [ 0,\theta \right ]\\ min(0,v_i +\alpha) \ \ \ \ \ \ if \ v_i \in \left [ -\theta,0 \right ]\\ v_i \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ otherwise \end{matrix}\right. T1(vi,α,θ)=⎩⎨⎧max(0,vi−α) if vi∈[0,θ]min(0,vi+α) if vi∈[−θ,0]vi otherwise
实际操作时,类似简单截断法,每 k k k步截断一次,当 t / k t/k t/k不为整数时 λ ( t ) = 0 \lambda^{(t)}=0 λ(t)=0,否则 λ ( t ) = k λ \lambda^{(t)}=k\lambda λ(t)=kλ,可以看出 λ \lambda λ和 θ \theta θ同时控制权重稀疏性,越大稀疏性越好。具体示意图如下所示,

- TG -> 简单截断法

- TG -> L1正则化

L1-FOBOS
更进一步,FOBOS核心思想是既考虑上一次迭代结果,也寻求本阶段最优,具体公式如下,
W ( t + 1 2 ) = W ( t ) − η ( t ) G ( t ) ( 1 ) W ( t ) = a r g m i n W { 1 2 ∥ W − W ( t + 1 2 ) ∥ 2 + η ( t + 1 2 ) Ψ ( W ) } ( 2 ) \begin{matrix} W^{(t+\frac{1}{2})}=W^{(t)}-\eta^{(t)}G^{(t)} \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ (1)\\ W^{(t)}=argmin_W\left \{ \frac{1}{2}\left \| W-W^{(t+\frac{1}{2})} \right \|^2+\eta^{(t+\frac{1}{2})}\Psi (W) \right \}\ \ \ \ \ (2) \end{matrix} W(t+21)=W(t)−η(t)G(t) (1)W(t)=argminW{21∥∥∥W−W(t+21)∥∥∥2+η(t+21)Ψ(W)} (2)
上述公式中第(1)步为标准的随机梯度下降,第(2)步是在当前基础上对结果进行微调。经过一套复杂推导公式(此处省略一万个公式),得到如下结果,
w i ( t + 1 ) = s g n ( w i ( t ) − η ( t ) g i ( t ) ) m a x { 0 , ∣ w i ( t ) − η ( t ) g i ( t ) ∣ − η ( t + 1 2 ) λ } w_i^{(t+1)}=sgn(w_i^{(t)}-\eta^{(t)}g_i^{(t)})max\left \{ 0,\left | w_i^{(t)}-\eta^{(t)}g_i^{(t)} \right | -\eta^{(t+\frac{1}{2})}\lambda\right \} wi(t+1)=sgn(wi(t)−η(t)gi(t))max{0,∣∣∣wi(t)−η(t)gi(t)∣∣∣−η(t+21)λ}
公式的另一种展现形式为:
w i ( t + 1 ) = { 0 i f ∣ w i ( t ) − η ( t ) g i ( t ) ∣ ≤ η ( t + 1 2 ) λ ( w i ( t ) − η ( t ) g i ( t ) ) − η ( t + 1 2 ) λ s g n ( w i ( t ) − η ( t ) g i ( t ) ) o t h e r w i s e w_i^{(t+1)}=\left\{\begin{matrix} 0 \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ if \ \left | w_i^{(t)}-\eta^{(t)}g_i^{(t)} \right | \leq \eta^{(t+\frac{1}{2})}\lambda \\ \left ( w_i^{(t)}-\eta^{(t)}g_i^{(t)} \right )-\eta^{(t+\frac{1}{2})}\lambda sgn\left ( w_i^{(t)}-\eta^{(t)}g_i^{(t)} \right ) \ \ \ \ otherwise \end{matrix}\right. wi(t+1)=⎩⎨⎧0 if ∣∣∣wi(t)−η(t)gi(t)∣∣∣≤η(t+21)λ(wi(t)−η(t)gi(t))−η(t+21)λsgn(wi(t)−η(t)gi(t)) otherwise
可以看出当一条样本产生的梯度,不足以令对应维度上权重产生足够大的变化,本维度不重要,权重被置为0,从而解决稀疏化问题。
L1-RDA
上述方法都是在随机梯度下降基础上进行改进的,而RDA另辟蹊径,具体公式如下,
W ( t + 1 ) = a r g m i n W { 1 t ∑ r = 1 t ⟨ G ( r ) , W ⟩ + λ ∣ ∣ W ∣ ∣ 1 + γ 2 t ∣ ∣ W ∣ ∣ 2 2 } W^{(t+1)}=argmin_W\left \{ \frac{1}{t}\sum_{r=1}^t\left \langle G^{(r)},W \right \rangle +\lambda ||W||_1+ \frac{\gamma}{2\sqrt{t}}||W||^2_2\right \} W(t+1)=argminW{t1r=1∑t⟨G(r),W⟩+λ∣∣W∣∣1+2tγ∣∣W∣∣22}
其中 ⟨ G ( r ) , W ⟩ \left \langle G^{(r)},W \right \rangle ⟨G(r),W⟩为梯度 G ( r ) G^{(r)} G(r)对 W W W的积分平均值, λ ∣ ∣ W ∣ ∣ 1 \lambda ||W||_1 λ∣∣W∣∣1为L1正则化项, { γ 2 t ∣ t ≥ 1 } \left \{ \frac{\gamma}{2\sqrt{t}}|t \geq 1\right \} {2tγ∣t≥1}为一个非负非递减序列。经过一套复杂推导公式(此处省略一万个公式),得到如下结果,
w i ( t + 1 ) = { 0 i f ∣ g i ˉ ( t ) ∣ < λ − t γ ( g i ˉ ( t ) − λ s g n ( g i ˉ ( t ) ) ) o t h e r w i s e w_i^{(t+1)}=\left\{\begin{matrix} 0 \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ if \ \left | \bar{g_i}^{(t)} \right |< \lambda \\ -\frac{\sqrt{t}}{\gamma}\left ( \bar{g_i}^{(t)}-\lambda sgn(\bar{g_i}^{(t)}) \right ) \ \ \ \ \ \ \ \ \ \ otherwise \end{matrix}\right. wi(t+1)={0 if ∣∣giˉ(t)∣∣<λ−γt(giˉ(t)−λsgn(giˉ(t))) otherwise
其中 g i ˉ ( t ) = 1 t ∑ r = 1 t g i ( t ) \bar{g_i}^{(t)}=\frac{1}{t}\sum_{r=1}^t g_i^{(t)} giˉ(t)=t1∑r=1tgi(t),可以看出当某个维度产生的累加梯度平均值的绝对值小于 λ \lambda λ,本维度不重要,权重被置为0,从而解决稀疏化问题。
L1-RDA vs L1-FOBOS
这里对两种方法的公式做进一步的变形,从而很好地比较这两种方法的不同:
L1-FOBOS: W ( t + 1 ) = a r g m i n W { G ( t ) ⋅ W + λ ∥ W ∥ 1 + 1 2 η ( t ) ∥ W − W ( t ) ∥ 2 2 } W^{(t+1)}=argmin_W\left \{ G^{(t)}\cdot W + \lambda \left \| W \right \|_1+\frac{1}{2\eta^{(t)}} \left \| W-W^{(t)} \right \|^2_2 \right \} W(t+1)=argminW{G(t)⋅W+λ∥W∥1+2η(t)1∥∥∥W−W(t)∥∥∥22}
L1-RDA: W ( t + 1 ) = a r g m i n W { G ( 1 : t ) ⋅ W + t λ ∥ W ∥ 1 + 1 2 η ( t ) ∥ W − 0 ∥ 2 2 } W^{(t+1)}=argmin_W\left \{ G^{(1:t)}\cdot W + t\lambda \left \| W \right \|_1+\frac{1}{2\eta^{(t)}} \left \| W-0 \right \|_2^2 \right \} W(t+1)=argminW{G(1:t)⋅W+tλ∥W∥1+2η(t)1∥W−0∥22}
其中 G ( 1 : t ) = ∑ r = 1 t G ( r ) G^{(1:t)}=\sum^t_{r=1}G^{(r)} G(1:t)=∑r=1tG(r),可以看出L1-FOBOS和L1-RDA的区别为:
- 对于上述两个公式前两项,前者计算当前梯度和L1正则化项,后者采用累加梯度和L1正则化项,
- 对于上述两个公式第三项,前者限制 W W W不能离当前迭代的 W ( t ) W^{(t)} W(t)太远,后者则只要求不能离0太远。
FTRL
FTRL是综合L1-RDA和L1-FOBOS后提出的算法,公式如下,这里引入L2正则化是为了令结果变得更平滑。
W ( t + 1 ) = a r g m i n W { G ( 1 : t ) ⋅ W + λ 1 ∥ W ∥ 1 + λ 2 1 2 ∥ W ∥ 2 2 + 1 2 ∑ r = 1 t σ ( r ) ∥ W − W ( r ) ∥ 2 2 } W^{(t+1)}=argmin_W\left \{ G^{(1:t)}\cdot W + \lambda_1 \left \| W \right \|_1 + \lambda_2 \frac{1}{2} \left \| W \right \|^2_2+\frac{1}{2}\sum_{r=1}^t\sigma^{(r)}\left \| W-W^{(r)} \right \|^2_2\right \} W(t+1)=argminW{G(1:t)⋅W+λ1∥W∥1+λ221∥W∥22+21r=1∑tσ(r)∥∥∥W−W(r)∥∥∥22}
经过一套复杂推导公式(此处省略一万个公式),得到如下结果,
w i ( t + 1 ) = { 0 i f ∣ z i ( t ) ∣ < λ 1 − ( λ 2 + ∑ r = 1 t σ ( r ) ) − 1 ( z i ( t ) − λ 1 s g n ( z i ( t ) ) ) o t h e r w i s e w_i^{(t+1)}=\left\{\begin{matrix} 0 \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ if \ \left | z_i^{(t)}\right |<\lambda_1 \\ -\left ( \lambda_2+\sum_{r=1}^t\sigma^{(r)} \right )^{-1}\left ( z_i^{(t)}-\lambda_1 sgn(z_i^{(t)}) \right ) \ \ \ \ \ otherwise \end{matrix}\right. wi(t+1)=⎩⎨⎧0 if ∣∣∣zi(t)∣∣∣<λ1−(λ2+∑r=1tσ(r))−1(zi(t)−λ1sgn(zi(t))) otherwise
其中 z i ( t ) = g i ( 1 : t ) − ∑ r = 1 t σ ( r ) w i ( r ) z_i^{(t)}=g_i^{(1:t)}-\sum_{r=1}^t\sigma^{(r)}w_i^{(r)} zi(t)=gi(1:t)−∑r=1tσ(r)wi(r),且FTRL中学习率为如下公式,
η i ( t ) = α β + ∑ r = 1 t ( g i ( r ) ) 2 \eta_i^{(t)}= \frac{\alpha}{\beta+\sqrt{\sum_{r=1}^t}\left ( g_i^{(r)} \right )^2} ηi(t)=β+∑r=1t(gi(r))2α
可以看出,FTRL确实综合了L1-RDA和L1-FOBOS的优点,在实时训练中使用该算法会模型的稀疏性很好,因为它考虑累积权重和累积梯度。
group lasso
在NLP和搜推广领域,输入特征多为embedding,模型对这类特征进行稀疏性处理时,需要在vector-wise层面考虑一组(group)权重参数的置0处理,传统FTRL算法只能在bit-wise层面对权重参数进行处理,因而不能满足需求,因而group lasso优化器应运而生,具体公式如下所示,
W ( t + 1 ) = a r g m i n W { G ( 1 : t ) ⋅ W + 1 2 ∑ r = 1 t σ ( r ) ∥ W − W ( r ) ∥ 2 2 + Ψ ( W ) } W^{(t+1)}=argmin_W\left \{ G^{(1:t)}\cdot W +\frac{1}{2}\sum_{r=1}^t\sigma^{(r)}\left \| W-W^{(r)} \right \|^2_2 + \Psi(W) \right \} W(t+1)=argminW{G(1:t)⋅W+21r=1∑tσ(r)∥∥∥W−W(r)∥∥∥22+Ψ(W)}
其中 Ψ ( W ) \Psi(W) Ψ(W)如下所示,
Ψ ( W ) = ∑ g = 1 G ( λ 1 ∥ W g ∥ 1 + λ 21 d W g ∥ A t 1 2 W g ∥ 2 ) + λ 2 ∥ W ∥ 2 2 \Psi(W)=\sum_{g=1}^G\left ( \lambda_1\left \| W^g \right \|_1+\lambda_{21}\sqrt{d_{W^g}}\left \| A_t^{\frac{1}{2}}W^g \right \|_2 \right )+\lambda_2\left \| W \right \|_2^2 Ψ(W)=g=1∑G(λ1∥Wg∥1+λ21dWg∥∥∥At21Wg∥∥∥2)+λ2∥W∥22
其中 G G G为embedding的个数, W g W^g Wg为某个embedding对应的一组权重参数, d W g d_{W^g} dWg为 W g W^g Wg的维度, λ 1 \lambda_1 λ1为L1正则化系数, λ 21 \lambda_{21} λ21为L21正则化系数, λ 2 \lambda_{2} λ2为L2正则化系数, A t A_t At与当前学习率的非线性表示,具体内容可以参见这里,从上面公式看出,group lasso算法对embedding对应权重参数组的稀疏性处理地较好。
在真正的工程实践中,发现group lasso与FTRL有两点不同:
- group lasso保存的模型要比FTRL大很多,因为group lasso规定 W g W^g Wg全为0时embedding才不会被导出,条件比FTRL更严苛,
- 同样L1和L2正则化参数和学习率下,group lasso效果要比FTRL好很多,因为group lasso更适合针对embedding做正则化。
参考文献
- 冯扬_在线最优化求解
- group lasso论文
- 次梯度