我们使用 Lua 脚本可以很轻松构建出百万并发的应用系统。
由于 Tomcat 并发处理能力弱,nginx 并发处理能力强,我们可以在 nginx 上结合 Lua 脚本来高效处理业务逻辑,不用经过 Tomcat,就能够通过 Lua 脚本来操作 Redis、Kafka、MySQL 等,比如:在秒杀活动中,我们把针对获取商品详情页的内容使用 Lua 脚本方式,通过 nginx 的 Lua 脚本接收到请求,在 nginx 上完成对应业务处理代码逻辑,避免访问后端应用服务器。
但不推荐在程序中大量使用 Lua 脚本,Lua 脚本很多就不方便管理,我们一般使用 Lua 脚本来实现高并发的业务流程

说了这么多,可能还有兄弟萌不明白什么是 Lua 脚本,下面我们简单说一下什么是 Lua 脚本?
Lua 是一个由 C 语言编写的小巧的脚本语言,其设计目的是为了通过灵活嵌入应用程序中,从而为应用程序提供灵活的扩展和定制功能。在所有的脚本引擎中,Lua 的速度是最快的,Lua 是作为嵌入式脚本的最佳选择。但 Lua 并没有提供强大的库,这是由它的定位决定的。所以 Lua 不适合作为开发独立应用程序的语言。
1.Lua 脚本高效访问数据库

- 首先需要安装 openresty,进入 lua 目录,编写 lua 脚本

- 通过修改 nginx 的配置文件,在 nginx 中实现 lua 脚本的调用
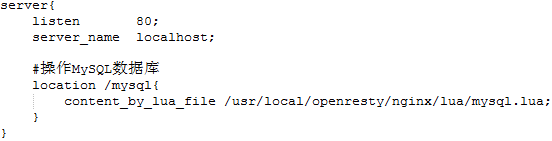
- 重启 nginx,访问:http://192.168.40.96/mysql?id=1
2.Lua 高效操作 Redis 集群
- 进入 lua 目录,编写 lua 脚本

- 在 nginx 中实现 lua 脚本的调用

- 重启 nginx,访问:192.168.211.141/redis?id=aaa&value=itheima&method=1
3.Lua 高效实现令牌校验
以前用户身份校验都是在 java 程序处实现,但如果用户发起大量无效请求,占用 Tomcat 资源,我们可以考虑直接在 nginx 处实现身份校验。

总结:在 nginx 上使用 Lua 脚本完成身份鉴权,这样可以减小后端压力 & 过滤掉无效请求
4.Redis 如何使用 Lua 脚本
从 Redis 2.6 版本开始,Redis 内置了 Lua 解释器,并提供了 eval 命令来解析 Lua 脚本,即允许开发者编写 Lua 脚本传到 Redis 中执行。
Lua 脚本功能为 Redis 开发和运维人员带来的 3 个好处:
- Lua 脚本在 Redis 中是原子执行的,执行过程中不会插入其它命令
- Lua 脚本可以帮助开发和运维人员创造出自己定制的命令,并可以将这些命令常驻在 Redis 内存中,实现复用的效果
- Lua 脚本可以将多条命令一次性打包,有效减少网络开销
接下来我们看看如何使用 Redis 来执行 Lua 脚本?
首先我们要看看 eval 的使用:
EVAL script numkeys key [key ...] arg [arg ...]//script:lua 脚本
//numkeys:key 的个数
//key:键名参数集,通过全局变量 KEYS 数组表示,起始下标为 1
//arg:键值参数集,通过全局变量 ARGV 数组表示,起始下标为 1
这样说,大家可能还是不太清楚是怎么一回事,我们看看一个例子:

通常情况下,我们不会直接在 redis-cli 中写 lua 脚本,这样非常不方便编辑,通过我们都是把 lua 脚本写到一个 lua 文件中,然后在 Redis 中执行这个 Lua 脚本,如:

然后我们通过下面命令执行,这种方式和前面介绍的不一样,参数 --eval script key1 key2,arg1 age2 这种模式,key 和 value 用一个逗号隔开就好了。

我们实战一下,如:通过 Lua 脚本获取指定的 key 的 List 中的所有数据?
新建 1.lua 脚本,如下:
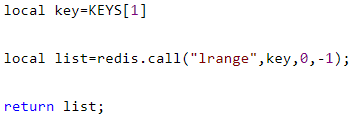
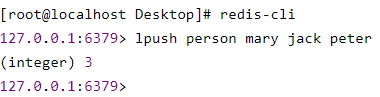
这里的 redis.call 就是用来执行 redis 中 list 的 lrange 命令,接下来通过 lpush 给 person 塞入 3 条数据,如下:
然后我们来执行这个 Lua 脚本,效果如下图: