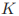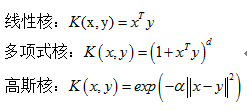假设给定如下数据(上面左图),显然我们没法用一条直线将′∘′ ′ ∘ ′ 和′×′ ′ × ′ 分开,如果用一个椭圆,将会得到很好的效果。我们希望将这个非线性分类问题变换为线性问题,通过变换后的线性问题的方法求解原来的非线性问题。上图中,我们可以将左图的椭圆变换成右图中的直线,将非线性分类问题变换为线性分类问题。 假设原空间为X∈R2,x=(x(1),x(2))∈X X ∈ R 2 , x = ( x ( 1 ) , x ( 2 ) ) ∈ X ,新空间为Z∈R2,z=(z(1),z(2))∈Z Z ∈ R 2 , z = ( z ( 1 ) , z ( 2 ) ) ∈ Z ,定义从原空间到新空间的变换为:
z=ϕ(x)=((x(1))2,(x(2))2) z = ϕ ( x ) = ( ( x ( 1 ) ) 2 , ( x ( 2 ) ) 2 )
经过变换
z=ϕ(x) z = ϕ ( x ) ,原空间
X∈R2 X ∈ R 2 变换为
Z∈Z2 Z ∈ Z 2 ,原空间的点相应的变换为新空间中的点,所以原空间的椭圆
w1(x(1))2+w2(x(2))2+b=0 w 1 ( x ( 1 ) ) 2 + w 2 ( x ( 2 ) ) 2 + b = 0
变换成新空间中的直线
w1z(1)+w2z(2)+b=0 w 1 z ( 1 ) + w 2 z ( 2 ) + b = 0
在变换后的新空间里,直线
w1z(1)+w2z(2)+b=0 w 1 z ( 1 ) + w 2 z ( 2 ) + b = 0 可以将变换后的正类和负类样本点正确分开。于是,原空间的非线性可分问题就变成了新空间中的线性可分问题。
总结一下,用线性分类方法求解非线性分类问题分为两步:首先使用一个变换将原空间的数据映射到新空间; 然后再新空间里用线性分类学习方法从训练数据中学习分类模型。
核技巧就属于这样的方法,应用到SVM上面的基本想法就是通过一个非线性变换
ϕ(x) ϕ ( x ) 将输入空间(欧式空间或离散集合)对应于一个特征空间(希尔伯特空间),使得输入空间的超曲面模型对应于特征空间中的超平面模型。幸运的是,
如果原始空间是有限维,即属性数有限,那么一定存在一个高维特征空间使样本线性可分。于是在特征空间中分离超平面所对应的模型可表示为:
f(x)=w⋅ϕ(x)+b f ( x ) = w ⋅ ϕ ( x ) + b
优化目标函数可表示为(约束条件这里就不写了):
minα12∑i=1m∑j=1mαiαjy(i)y(j)(ϕ(x(i))⋅ϕ(x(j)))−∑i=1mαi(1) (1) min α 1 2 ∑ i = 1 m ∑ j = 1 m α i α j y ( i ) y ( j ) ( ϕ ( x ( i ) ) ⋅ ϕ ( x ( j ) ) ) − ∑ i = 1 m α i
求解上面的优化函数涉及到计算
ϕ(x(i))⋅ϕ(x(j)) ϕ ( x ( i ) ) ⋅ ϕ ( x ( j ) ) ,这是样本
x(i) x ( i ) 和
x(j) x ( j ) 映射到特征空间的内积,由于特征空间维度可能很高,甚至是无穷维,因此直接计算
ϕ(x(i))⋅ϕ(x(j)) ϕ ( x ( i ) ) ⋅ ϕ ( x ( j ) ) 通常是困难的,避开这个障碍的一个方法是引入核函数:
K(x(i),x(j))=ϕ(x(i))⋅ϕ(x(j))(2) (2) K ( x ( i ) , x ( j ) ) = ϕ ( x ( i ) ) ⋅ ϕ ( x ( j ) )
即我们只定义核函数
K(x,z) K ( x , z ) ,而不显式地定义映射函数
ϕ(x) ϕ ( x ) ,这样我们就不用去计算高维甚至无穷维特征空间中的内积。对于给定的核函数,可以取不同的特征空间,即便是在同一特征空间里也可以取不同的映射。于是(1)可以重写为:
minα12∑i=1m∑j=1mαiαjy(i)y(j)K(x(i),x(j))−∑i=1mαi(3) (3) min α 1 2 ∑ i = 1 m ∑ j = 1 m α i α j y ( i ) y ( j ) K ( x ( i ) , x ( j ) ) − ∑ i = 1 m α i
用SMO算法解得
α∗i α i ∗ ,然后确定分离超平面和分类决策函数。算法步骤和原来SVM一模一样,几乎不需要改动,只需要将
ϕ(x(i))⋅ϕ(x(j)) ϕ ( x ( i ) ) ⋅ ϕ ( x ( j ) ) 替换成
K(x(i),x(j)) K ( x ( i ) , x ( j ) ) 即可。
2. 核函数
显然,如果映射ϕ(x) ϕ ( x ) 的具体形式已知,我们可以很轻松写出核函数K(x,z) K ( x , z ) 。但现实任务中我们通常不知道ϕ(x) ϕ ( x ) 是什么形式,那么合适的核函数是否一定存在呢?什么样的函数才能做核函数呢? 先上结论,一个函数能作为核函数的充要条件是——正定核函数。即核函数K(x,z) K ( x , z ) 对应的Gram矩阵
K=[K(x(i),x(j))]m×n K = [ K ( x ( i ) , x ( j ) ) ] m × n
是半正定矩阵,那么
K(x,z) K ( x , z ) 是正定核。鉴于在实际问题中往往是应用已有的核函数,自己设计核函数是“高玩”做的事,我这里就暂且先跳过证明这一步。下面来介绍一下常用的核函数,然后再来讨论一下核函数怎么选取的问题。
对非线性SVM算法流程做一个小结: 输入:线性可分数据集T={(x(1),y(1)),(x(2),y(2)),…,(x(m),y(m))} T = { ( x ( 1 ) , y ( 1 ) ) , ( x ( 2 ) , y ( 2 ) ) , … , ( x ( m ) , y ( m ) ) } ,y(i)∈{−1,+1} y ( i ) ∈ { − 1 , + 1 } 输出:分离超平面和分类决策函数 (1)选取适当的核函数K(x,z) K ( x , z ) 和惩罚系数C C 构造约束最优化问题:
w∗b∗=∑i=1mα∗iy(i)x(i)=1p∑j=1p(y(j)−∑i=1mα∗iy(i)K(x(i),x(j)) w ∗ = ∑ i = 1 m α i ∗ y ( i ) x ( i ) b ∗ = 1 p ∑ j = 1 p ( y ( j ) − ∑ i = 1 m α i ∗ y ( i ) K ( x ( i ) , x ( j ) )
(4)求得分离超平面:
∑i=1mα∗iy(i)K(x(i),x(j)))+b∗=0 ∑ i = 1 m α i ∗ y ( i ) K ( x ( i ) , x ( j ) ) ) + b ∗ = 0
分类决策函数:
f(x)=sign(∑i=1mα∗iy(i)K(x(i),x(j))+b∗) f ( x ) = s i g n ( ∑ i = 1 m α i ∗ y ( i ) K ( x ( i ) , x ( j ) ) + b ∗ )
参考论文-DENSITY ESTIMATION FOR STATISTICS AND DATA ANALYSIS
给定数据集,来估计概率密度函数 Histograms The naive estimator
也是分成段的平行x轴直线连接起来 The kernel estimator
其中kernel可以是高斯核,结果图: 可以见到,高斯核…