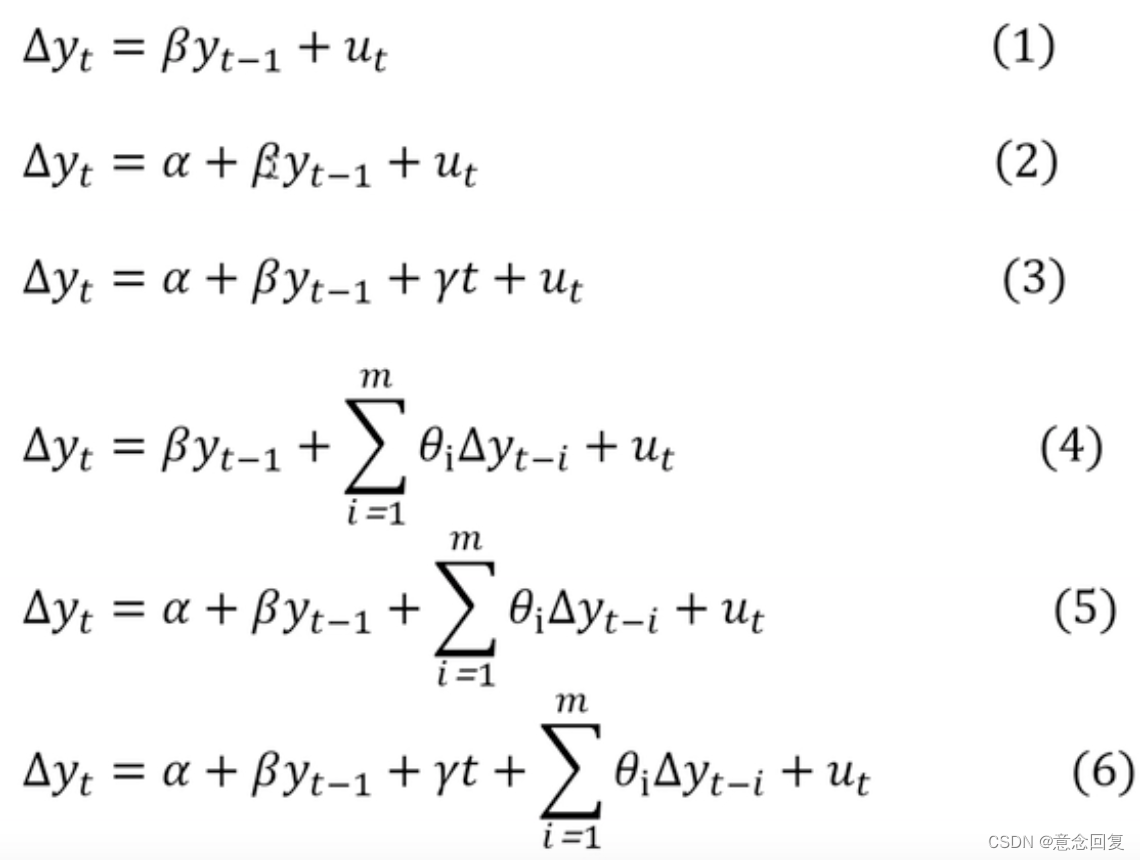转自:https://pengfoo.com/post/machine-learning/2017-01-24
Abstract
在ARMA/ARIMA这样的自回归模型中,模型对时间序列数据的平稳是有要求的,因此,需要对数据或者数据的n阶差分进行平稳检验,而一种常见的方法就是ADF检验,即单位根检验。
平稳随机过程
在数学中,平稳随机过程(Stationary random process)或者严平稳随机过程(Strictly-sense stationary random process),又称狭义平稳过程,是在固定时间和位置的概率分布与所有时间和位置的概率分布相同的随机过程:即随机过程的统计特性不随时间的推移而变化。这样,数学期望和方差这些参数也不随时间和位置变化。
平稳在理论上有严平稳和宽平稳两种,在实际应用上宽平稳使用较多。宽平稳的数学定义为:
对于时间序列 ytyt,若对任意的t,k,mt,k,m,满足:
则称时间序列 ytyt 是宽平稳的。
平稳是自回归模型ARMA的必要条件,因此对于时间序列,首先要保证应用自回归的n阶差分序列是平稳的。
肉眼检验
我们以某次天池比赛的数据集为例,如图,是店铺从2015-09到2016-10的销售额:
该数据显然是不平稳的,我们来看看一阶差分:
_series = pd.Series(data=data['cnt']) # 获取data过程省略
diff1 = dta = _series.diff(1)[1:] # dta[0] is nan
diff1.plot()
plt.savefig('./diff_1.jpg')

看起来似乎均值稳定在0左右,而且也具有一定周期性。
继续来看看二阶差分能否更平稳一些:
看起来二阶差分和一阶差分都比较稳定,肉眼难辨高下。
只用肉眼是分不清是否真的平稳的,因此,我们有必要引入数学方法对平稳进行形式化的检验。
单位根检验
单位根检验是指检验序列中是否存在单位根,因为存在单位根就是非平稳时间序列了。单位根就是指单位根过程,可以证明,序列中存在单位根过程就不平稳,会使回归分析中存在伪回归。
而迪基-福勒检验(Dickey-Fuller test)和扩展迪基-福勒检验(Augmented Dickey-Fuller test可以测试一个自回归模型是否存在单位根(unit root)。迪基-福勒检验模式是D. A迪基和W. A福勒建立的。
关于检验的详细内容,见[6],碍于公式实在太难打了,这里不再赘述。
ADF Test in Python
在python中对时间序列的建模通常使用statsmodel库,该库在我心中的科学计算库排名中长期处于垫底状态,因为早期文档实在匮乏,不过近来似有好转倾向。
在statsmodels.tsa.stattools.adfuller中可进行adf校验,一般传入一个1d 的 array like的data就行,包括list, numpy array 和 pandas series都可以作为输入,其他参数可以保留默认.
其返回值是一个tuple,格式如下:
对上面一阶差分的数据进行adf检验,可以得到如下结果:
print sm.tsa.stattools.adfuller(dta)
(-9.1916312162314355, 2.1156279593784273e-15, 12, 338, {'5%': -2.8701292813761641, '1%': -3.449846029628477, '10%': -2.5713460670144603}, 4542.1540700410897)
如何确定该序列能否平稳呢?主要看:
- 1%、%5、%10不同程度拒绝原假设的统计值和ADF Test result的比较,ADF Test result同时小于1%、5%、10%即说明非常好地拒绝该假设,本数据中,adf结果为-9, 小于三个level的统计值。
- P-value是否非常接近0.本数据中,P-value 为 2e-15,接近0.
ADF检验的原假设是存在单位根,只要这个统计值是小于1%水平下的数字就可以极显著的拒绝原假设,认为数据平稳。注意,ADF值一般是负的,也有正的,但是它只有小于1%水平下的才能认为是及其显著的拒绝原假设。
对于ADF结果在1% 以上 5%以下的结果,也不能说不平稳,关键看检验要求是什么样子的。
但是对于本例,可以很自豪地说,数据是平稳的了。
就做了这么一点微小的工作,谢谢大家。
Reference
[1] 单位根检验--百度文库
[2] Time Series Analysis in Python with statsmodels
[3] 平稳时间序列预测法
[4] statsmodels 文档
[5] 平稳随机过程--百度百科
[6] 迪基-福勒检验-Wikipedia
[7] 如何看 单位根检验---ADF检验结果