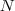时间序列学习(4):平稳性检验(单位根检验、ADF检验)
- 1、单位根检验
- 2、ADF检验
- 3、指数走势的检验
- 4、对数收益率序列检验
相关图可以大致判断序列是否平稳。但是,这毕竟不是严格的。
这篇笔记来就谈一谈平稳性的检验。
到目前为止,我们有了以下的时间序列模型:
- 白噪声;
- 随机游走;
- AR模型;
- MA模型;
- ARMA模型。
我们知道白噪声、MA模型一定是平稳的(这里的平稳都是弱平稳);随机游走一定是不平稳的;ARMA模型取决于其AR部分。
所以唯一需要做平稳性检验的就是AR模型。
1、单位根检验
先来看一阶AR模型,即AR(1)的情况,其模型如下:
r t = α 1 r t − 1 + w t r_t=\alpha_1r_{t-1}+w_t rt=α1rt−1+wt
如果 α 1 = 1 \alpha_1=1 α1=1,该模型就是随机游走,我们知道它是不平稳的。换个思路想象一下,当 α 1 = 1 \alpha_1=1 α1=1,那么前一时刻的收益率对当下时刻的影响是100%的,不会减弱;那么就算是很远的某个时刻,当下对它的影响还是不会消除,所以方差(表现在波动)是受前面所有时刻的影响,是和 t t t相关的,因此不平稳;
如果 α 1 > 1 \alpha_1\gt1 α1>1,那么当前时刻的波动不仅受前面时刻的影响,还被放大了,所以肯定不平稳;
只有当 α 1 < 1 \alpha_1\lt1 α1<1的时候,前面时刻的波动对当前时刻的影响会逐渐减小。可以计算此时的自协方差以及自相关系数是一个固定值。所以这种情况下,序列是平稳的。
对于高阶的AR模型也是一样的,一个AR (P)阶 模型如下:
r t = ∑ i = 1 P α i r t − i + w t r_t=\sum^P_{i=1}\alpha_ir_{t-i}+w_t rt=i=1∑Pαirt−i+wt
如果 α 1 , . . . , α 2 \alpha_1,...,\alpha_2 α1,...,α2都小于1,那么这个序列是平稳的;存在某一个 α i ≥ 1 \alpha_i\ge1 αi≥1,这个序列就不是平稳的。
要判断 α 1 , . . . , α 2 \alpha_1,...,\alpha_2 α1,...,α2是否都小于1,一般利用AR模型的特征方程,如下:
1 − α 1 x − α 2 x 2 − . . . − α p x p = 0 1-\alpha_1x-\alpha_2x^2-...-\alpha_px^p=0 1−α1x−α2x2−...−αpxp=0
这个方程有p个根。
检验AR序列是否平稳,就是检验是否存在某个根大于等于1。这个过程叫单位根检验。
2、ADF检验
单位根检验有诸多方法,其中较为经典是ADF检验。
ADF检验的全称是Augmented Dickey-Fuller test,它是Dickey-Fuller(DF)检验的扩展。DF检验只能应用于一阶AR模型的情况。当序列为高阶时,存在滞后相关性,于是可以使用更适用的ADF检验。
整个检验过程涉及到很多数学和统计学处理,在此不详述,下面直接看在Python中如何使用吧。
3、指数走势的检验
我们还是采用从第1篇笔记就采用的数据,即沪深300于2018年1月1日至2019年12月13日的走势。
其走势如下:
prices = get_price('000300.XSHG', start_date='2018-01-01', end_date='2019-12-13', frequency='daily', fields='close')
fig = plt.figure(figsize=(10, 6))
ax = fig.add_axes([0.2, 0.2, 1.2, 1.2])ax.plot(prices, color="blue", linewidth=1.5, linestyle="-", label=r'hs300')
plt.legend(loc='upper right', frameon=False)

采用statsmodels中的相关包对序列prices进行检验:
from statsmodels.stats.diagnostic import unitroot_adfunitroot_adf(prices.close)
或者采用下面的函数,一样的:
from statsmodels.tsa.stattools import adfulleradfuller(prices.close)
结果如下:
(-1.932446672214747,0.3169544458085871,9,465,{'1%': -3.4444914328761977,'5%': -2.8677756786103683,'10%': -2.570091378194011},4819.095453869604)
上述取值分别为:
- t-检验值;
- P-Value
- 滞后阶数(lags)
- 样本数
- 1%,5%,10%的边界值
- 最大信息准则(参数中autolag需不为None)
ADF检验基于统计中的假设检验方式,利用t-检验来观测显著性。这些细节不介绍了。
上述结果可以这样来看,如果
- t-检验值大于某个临界值,那么在这个临界值以内序列的不平稳性比较显著;
- 或者,p-Value大于某个临界值的百分位(即,1%,5%,10%),那么序列的不平稳性比较显著。
我们看到上面的结果,t-检验值明显大于10%的临界值,p-Value明显大于10%。
所以上面的指数走势序列是显著的不平稳的。我们在第2篇笔记说走势序列近似于随机游走,所以这个检验结果符合预期。
4、对数收益率序列检验
我们同样针对沪深300于2018年1月1日至2019年12月13日的日对数收益率序列进行检验。
import pandas as pd
import mathprices = get_price('000300.XSHG', start_date='2018-01-01', end_date='2019-12-13', frequency='daily', fields='close')returns = {'return':{}}
for i in range(len(prices)):current_price = prices.iloc[i,0]if i == 0:current_return = 0else:last_price = prices.iloc[i-1,0]current_return = math.log(current_price)-math.log(last_price)date = list(prices.index)[i]returns['return'][date] = current_return
return_df = pd.DataFrame(returns, columns=['return'], index=list(prices.index))fig = plt.figure(figsize=(10, 6))
ax = fig.add_axes([0.2, 0.2, 1.2, 1.2])
ax.plot(return_df, color="blue", linewidth=1.5, linestyle="-", label=r'hs300-daily-log-returns')
plt.legend(loc='upper right', frameon=False)

检验结果如下:
unitroot_adf(return_df.loc[:,'return'])
(-6.9332827227876,1.070439257686785e-09,8,466,{'1%': -3.4444609168389615,'5%': -2.8677622536920317,'10%': -2.5700842229549266},-2646.8267439593874)
这个结果里,t-检验值远小于1%的临界值,P-Value也远小于1%。所以,序列没有显著的不平稳性。因而我们可以认为该序列是平稳的。
这里要注意的一点是:当我们采用ADF进行检验的时候,我们实际上已经假设用AR模型对序列进行建模了。