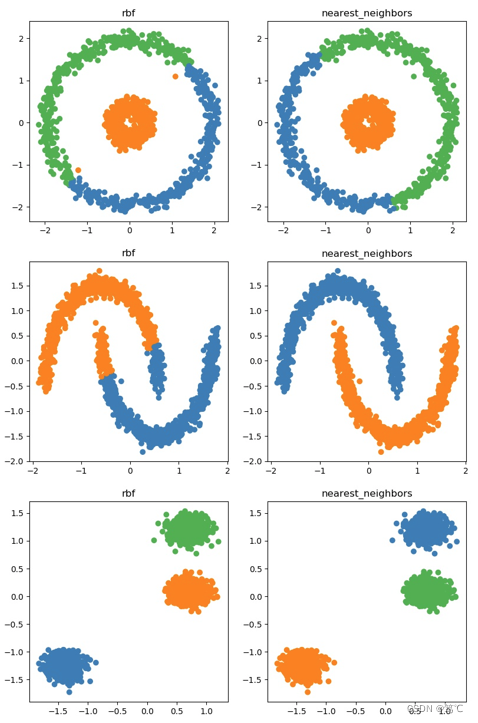
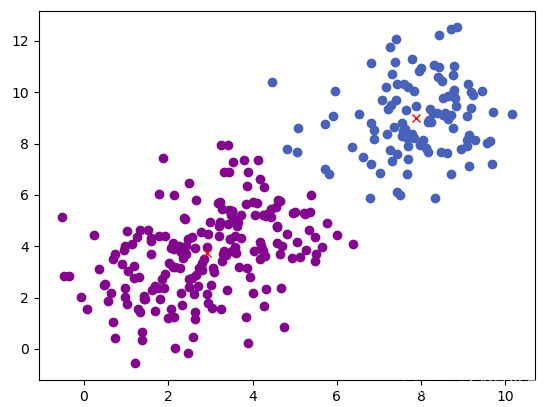
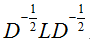k-means 可以说是思想最简单的聚类了,但是它在应对非凸数据时却显得手足无措,例如如下的数据分类:
各类之间虽然间隔较远,但是非凸,这时候就需要引入谱聚类了(以下为谱聚类效果)。
本文参考
[1]Ulrike von Luxburg. A Tutorial on Spectral Clustering[J]. CoRR,2007,abs/0711.0189(4).
[2]https://zhuanlan.zhihu.com/p/392736238
[3]https://blog.csdn.net/SL_World/article/details/104423536
[4]https://blog.csdn.net/Keeplingshi/article/details/51063190
[5]https://www.cnblogs.com/pinard/p/6221564.html
原理简述
无向图
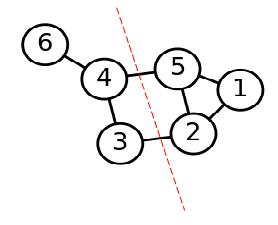
给定一个数据集 X = { x 1 , x 2 , … , x n } X=\left\{\boldsymbol{x}_1, \boldsymbol{x}_2, \ldots, \boldsymbol{x}_n\right\} X={x1,x2,…,xn},将每一个数据点看作无向图上的一个顶点,记为 G = ( V , E ) G=(V, E) G=(V,E).
相似矩阵与边权
空间两个点的距离越近,则它们越相似,距离越远,则它们越不相似,即相似度与距离成反比,这里我们提出相似矩阵的概念来衡量各个点的相似程度,其中 w i j w_{ij} wij表明节点 i i i和节点 j j j的相似程度, w i j = w j i w_{ij}=w_{ji} wij=wji:
W = [ w 11 w 12 … w 1 n w 21 w 22 … w 2 n ⋮ ⋮ … ⋮ w n 1 w n 2 … w n n ] W=\left[\begin{array}{cccc} w_{11} & w_{12} & \ldots & w_{1 n} \\ w_{21} & w_{22} & \ldots & w_{2 n} \\ \vdots & \vdots & \ldots & \vdots \\ w_{n 1} & w_{n 2} & \ldots & w_{n n} \end{array}\right] W=⎣ ⎡w11w21⋮wn1w12w22⋮wn2…………w1nw2n⋮wnn⎦ ⎤
向量空间中衡量两个点之间相似度的方法有很多,这里采用最常用的全连接法并使用高斯核函数进行衡量,即:
w i j = exp ( − ∥ x i − x j ∥ 2 2 σ 2 ) w_{i j}=\exp \left(-\frac{\left\|x_i-x_j\right\|^2}{2 \sigma^2}\right) wij=exp(−2σ2∥xi−xj∥2)
度与度矩阵
对角线元素 d i d_i di是和节点 i i i相关的相似度之和,即:
d i = ∑ j = 1 n w i j d_i=\sum_{j=1}^n w_{ij} di=j=1∑nwij
D = [ d 1 0 … 0 0 d 2 … 0 ⋮ ⋮ ⋱ ⋮ 0 0 … d n ] D=\left[\begin{array}{cccccc} d_1 & 0 & \ldots & 0 \\ 0 & d_2 & \ldots & 0 \\ \vdots & \vdots & \ddots & \vdots \\ 0 & 0 & \ldots & d_n \end{array}\right] D=⎣ ⎡d10⋮00d2⋮0……⋱…00⋮dn⎦ ⎤
子图的大小
- 定义一:子集内顶点的个数,记为 ∣ A ∣ |A| ∣A∣
- 定义二:子集内所有顶点的度之和,记为 vol ( A ) : = ∑ v i ∈ A d i \operatorname{vol}(A):=\sum_{v_i \in A} d_i vol(A):=∑vi∈Adi
图拉普拉斯矩阵
即:
L = D − W L=D-W L=D−W
对于任意的向量 f ∈ R n \boldsymbol{f} \in R^n f∈Rn满足:
f T L f = f T ( D − W ) f = f T D f − f T W f = ∑ i = 1 n d i f i 2 − ∑ i , j = 1 n w i j f i f j = 1 2 ( ∑ i = 1 n d i f i 2 − 2 ∑ i , j = 1 n w i j f i f j + ∑ j = 1 n d j f j 2 ) = 1 2 ( ∑ i , j = 1 n w i j f i 2 − 2 ∑ i , j = 1 n w i j f i f j + ∑ i , j = 1 n w i j f j 2 ) = 1 2 ∑ i , j = 1 n w i j ( f i 2 − 2 f i f j + f j 2 ) = 1 2 ∑ i , j = 1 n w i j ( f i − f j ) 2 \begin{aligned} \boldsymbol{f}^T L \boldsymbol{f} &=\boldsymbol{f}^T(D-W) \boldsymbol{f} =\boldsymbol{f}^T D \boldsymbol{f}-\boldsymbol{f}^T W \boldsymbol{f} \\ &=\sum_{i=1}^n d_i f_i^2-\sum_{i, j=1}^n w_{i j} f_i f_j \\ &=\frac{1}{2}\left(\sum_{i=1}^n d_i f_i^2-2 \sum_{i, j=1}^n w_{i j} f_i f_j+\sum_{j=1}^n d_j f_j^2\right) \\ &=\frac{1}{2}\left(\sum_{i, j=1}^n w_{i j} f_i^2-2 \sum_{i, j=1}^n w_{i j} f_i f_j+\sum_{i, j=1}^n w_{i j} f_j^2\right) \\ &=\frac{1}{2} \sum_{i, j=1}^n w_{i j}\left(f_i^2-2 f_i f_j+f_j^2\right) \\ &=\frac{1}{2} \sum_{i, j=1}^n w_{i j}\left(f_i-f_j\right)^2 \end{aligned} fTLf=fT(D−W)f=fTDf−fTWf=i=1∑ndifi2−i,j=1∑nwijfifj=21(i=1∑ndifi2−2i,j=1∑nwijfifj+j=1∑ndjfj2)=21(i,j=1∑nwijfi2−2i,j=1∑nwijfifj+i,j=1∑nwijfj2)=21i,j=1∑nwij(fi2−2fifj+fj2)=21i,j=1∑nwij(fi−fj)2
切图
把点集分类在谱聚类算法中的本质就是将无向图切割成几个互不相交的顶点集合,每个顶点集合为: A 1 , A 2 , … , A k A_1,A_2,\dots,A_k A1,A2,…,Ak,它们满足 A i ∩ A j = ∅ A_i \cap A_j=\emptyset Ai∩Aj=∅, A 1 ∪ A 2 ∪ … ∪ A k = V A_1 \cup A_2 \cup \ldots \cup A_k=V A1∪A2∪…∪Ak=V.
对于图的两个顶点集合 A A A和 B B B,两顶点集合之间所有边权重之和使用如下公式表示:
W ( A , B ) : = ∑ v i ∈ A , v j ∈ B w i j W(A, B):=\sum_{\boldsymbol{v}_i \in A, \boldsymbol{v}_j \in B} w_{i j} W(A,B):=vi∈A,vj∈B∑wij
对于 k k k个子图的切分,定义定义切图(我们优化的目标函数)为:
cut ( A 1 , A 2 , … , A k ) : = 1 2 ∑ i = 1 k W ( A i , A ˉ i ) \operatorname{cut}\left(A_1, A_2, \ldots, A_k\right):=\frac{1}{2} \sum_{i=1}^k W\left(A_i, \bar{A}_i\right) cut(A1,A2,…,Ak):=21i=1∑kW(Ai,Aˉi)
其中 A ˉ i \bar{A}_i Aˉi为 A i A_i Ai的补集,因此想法非常简单,你子集和补集之间联系越低,就越应该被分成两类,就是被切一刀,找到最容易动刀子的几个地方将顶点集合切割成 k k k份就实现了分类。
但是,最小化切割可能会导致出现下图这样某些类顶点数量过少的情况,因此我们需要将顶点数量等信息加入考虑:
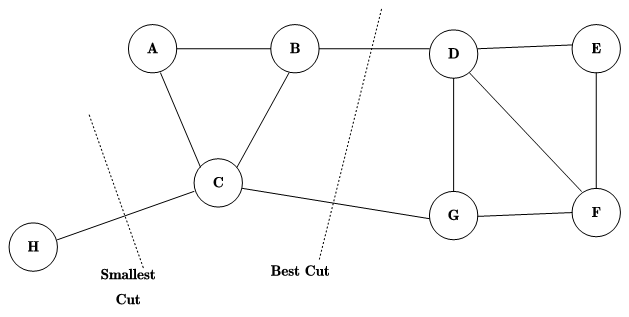
RatioCut切图与Ncut切图
RatioCut切图为了避免第五节的最小切图,对每个切图,不光考虑最小化 cut ( A 1 , A 2 , … , A k ) \operatorname{cut}\left(A_1, A_2, \ldots, A_k\right) cut(A1,A2,…,Ak),它还同时考虑最大化每个子图点的个数,即:
RatioCut ( A 1 , A 2 , … A k ) = 1 2 ∑ i = 1 k W ( A i , A ˉ i ) ∣ A i ∣ \operatorname{RatioCut}\left(A_1, A_2, \ldots A_k\right)=\frac{1}{2} \sum_{i=1}^k \frac{W\left(A_i, \bar{A}_i\right)}{\left|A_i\right|} RatioCut(A1,A2,…Ak)=21i=1∑k∣Ai∣W(Ai,Aˉi)
而Ncut切图和RatioCut切图很类似,但是把Ratiocut的分母 ∣ A i ∣ \left|A_i\right| ∣Ai∣换为 vol ( A i ) \operatorname{vol}\left(A_i\right) vol(Ai):
NCut ( A 1 , A 2 , … A k ) = 1 2 ∑ i = 1 k W ( A i , A ˉ i ) vol ( A i ) \operatorname{NCut}\left(A_1, A_2, \ldots A_k\right)=\frac{1}{2} \sum_{i=1}^k \frac{W\left(A_i, \bar{A}_i\right)}{\operatorname{vol}\left(A_i\right)} NCut(A1,A2,…Ak)=21i=1∑kvol(Ai)W(Ai,Aˉi)
由于子图样本的个数多并不一定权重就大,我们切图时基于权重也更合我们的目标,因此一般来说Ncut切图优于RatioCut切图。为了显示篇幅只讲最常用的方法,本文只讲解Ncut切图(RatioCut切图可以非常简单的类比过去):
我们引入指示向量: h j ∈ { h 1 , h 2 , … h k } , j = 1 , 2 , … k h_j \in\left\{h_1, h_2, \ldots h_k\right\} ,j=1,2, \ldots k hj∈{h1,h2,…hk},j=1,2,…k对于任意一个向量 h j h_j hj, 它是一个n维向量(n为样本数),我们定义 h i j h_{ij} hij为:
h i j = { 0 v i ∉ A j 1 v o l ( A j ) v i ∈ A j h_{i j}= \begin{cases}0 & v_i \notin A_j \\ \frac{1}{\sqrt{v o l\left(A_j\right)}} & v_i \in A_j\end{cases} hij={0vol(Aj)1vi∈/Ajvi∈Aj
然后我们得把切图用矩阵表示出来,不然一个一个顶点算费老鼻子劲了,有一些大佬就发现,可以用 h i T L h i h_i^T L h_i hiTLhi表示某个集合的切图:
h i T L h i = 1 2 ∑ m = 1 ∑ n = 1 w m n ( h i m − h i n ) 2 = 1 2 ( ∑ m ∈ A i , n ∉ A i w m n ( 1 v o l ( A i ) − 0 ) 2 + ∑ m ∉ A i , n ∈ A i w m n ( 0 − 1 v o l ( A i ) ) 2 = 1 2 ( ∑ m ∈ A i , n ∉ A i w m n 1 vol ( A i ) + ∑ m ∉ A i , n ∈ A i w m n 1 vol ( A i ) = 1 2 ( cut ( A i , A ˉ i ) 1 vol ( A i ) + cut ( A ˉ i , A i ) 1 vol ( A i ) ) = cut ( A i , A ˉ i ) vol ( A i ) \begin{aligned} h_i^T L h_i &=\frac{1}{2} \sum_{m=1} \sum_{n=1} w_{m n}\left(h_{i m}-h_{i n}\right)^2 \\ &=\frac{1}{2}\left(\sum_{m \in A_i, n \notin A_i} w_{m n}\left(\frac{1}{\sqrt{v o l}\left(A_i\right)}-0\right)^2+\sum_{m \notin A_i, n \in A_i} w_{m n}\left(0-\frac{1}{\sqrt{v o l\left(A_i\right)}}\right)^2\right.\\ &=\frac{1}{2}\left(\sum_{m \in A_i, n \notin A_i} w_{m n} \frac{1}{\operatorname{vol}\left(A_i\right)}+\sum_{m \notin A_i, n \in A_i} w_{m n} \frac{1}{\operatorname{vol}\left(A_i\right)}\right.\\ &=\frac{1}{2}\left(\operatorname{cut}\left(A_i, \bar{A}_i\right) \frac{1}{\operatorname{vol}\left(A_i\right)}+\operatorname{cut}\left(\bar{A}_i, A_i\right) \frac{1}{\operatorname{vol}\left(A_i\right)}\right) \\ &=\frac{\operatorname{cut}\left(A_i, \bar{A}_i\right)}{\operatorname{vol}\left(A_i\right)} \end{aligned} hiTLhi=21m=1∑n=1∑wmn(him−hin)2=21⎝ ⎛m∈Ai,n∈/Ai∑wmn(vol(Ai)1−0)2+m∈/Ai,n∈Ai∑wmn(0−vol(Ai)1)2=21⎝ ⎛m∈Ai,n∈/Ai∑wmnvol(Ai)1+m∈/Ai,n∈Ai∑wmnvol(Ai)1=21(cut(Ai,Aˉi)vol(Ai)1+cut(Aˉi,Ai)vol(Ai)1)=vol(Ai)cut(Ai,Aˉi)
那么所有子集切图和:
NCut ( A 1 , A 2 , … A k ) = ∑ i = 1 k h i T L h i = ∑ i = 1 k ( H T L H ) i i = tr ( H T L H ) \operatorname{NCut}\left(A_1, A_2, \ldots A_k\right)=\sum_{i=1}^k h_i^T L h_i=\sum_{i=1}^k\left(H^T L H\right)_{i i}=\operatorname{tr}\left(H^T L H\right) NCut(A1,A2,…Ak)=i=1∑khiTLhi=i=1∑k(HTLH)ii=tr(HTLH)
最理想的情况下 h i h_i hi应该是单位向量,主要各个软件求特征向量都是求的单位向量,再如果不统一的话某一列特征向量元素值都巨大的话,那很多顶点都会被归为那一类,不过此时 H T D H ≠ I H^T D H\neq I HTDH=I不是正交的,反而 H T D H = I H^T D H=I HTDH=I:
h i T D h i = ∑ j = 1 n h i j 2 d j = 1 vol ( A i ) ∑ j ∈ A i d j = 1 vol ( A i ) vol ( A i ) = 1 h_i^T D h_i=\sum_{j=1}^n h_{i j}^2 d_j=\frac{1}{\operatorname{vol}\left(A_i\right)} \sum_{j \in A_i} d_j=\frac{1}{\operatorname{vol}\left(A_i\right)} \operatorname{vol}\left(A_i\right)=1 hiTDhi=j=1∑nhij2dj=vol(Ai)1j∈Ai∑dj=vol(Ai)1vol(Ai)=1
而若令 H = D − 1 / 2 F H=D^{-1 / 2} F H=D−1/2F则:
H T L H = F T D − 1 / 2 L D − 1 / 2 F , H T D H = F T F = I H^T L H=F^T D^{-1 / 2} L D^{-1 / 2} F, H^T D H=F^T F=I HTLH=FTD−1/2LD−1/2F,HTDH=FTF=I
因此优化目标由:
arg min ⏟ H tr ( H T L H ) s.t. H T D H = I \underbrace{\arg \min }_H \operatorname{tr}\left(H^T L H\right) \text { s.t. } H^T D H=I H argmintr(HTLH) s.t. HTDH=I
变为:
arg min ⏟ F tr ( F T D − 1 / 2 L D − 1 / 2 F ) s.t. F T F = I \underbrace{\arg \min }_F \operatorname{tr}\left(F^T D^{-1 / 2} L D^{-1 / 2} F\right) \text { s.t. } F^T F=I F argmintr(FTD−1/2LD−1/2F) s.t. FTF=I
由于矩阵的迹等于全部特征值之和,我们只需要找到k个最小的特征值并找到其相对应的指示向量。
特征向量聚类
毕竟不是把数据每个点分成一类,而且只要前k个最小特征向量略去了很多信息,因此得到的指示向量不可能像下面这么完美:
0 0 c1
0 0 c1
0 0 c1
c2 0 0
0 c3 0
0 c3 0
… … …
他肯定大体是像这样:
0.1 0.2 0.9
0.0 0.1 0.8
2.0 0.8 0.1
1.8 0.6 0.1
… … …
那简单啊我们直接把行向量当作每一个元素直接k-means一下聚下类就好了呀。完美解决。
MATLAB实现
算法流程
- 构建样本的相似矩阵 S S S
- 根据相似矩阵 S S S构建邻接矩阵 W W W,构建度矩阵 D D D
- 计算出拉普拉斯矩阵 L L L
- 标准化的拉普拉斯矩阵 D − 1 / 2 L D − 1 / 2 D^{−1/2}LD^{−1/2} D−1/2LD−1/2
- 计算 D − 1 / 2 L D − 1 / 2 D^{−1/2}LD^{−1/2} D−1/2LD−1/2最小的k个特征值所各自对应的特征向量 f \boldsymbol{f} f
- 将各自对应的特征向量 f \boldsymbol{f} f组成的矩阵按行标准化,最终组成 n × k n×k n×k维的特征矩阵 F F F
- 对 F F F中的每一行作为一个 k k k维的样本,共 n n n个样本,进行聚类
- 得到簇划分 C 1 , C 2 , … , C k C_1, C_2, \ldots, C_k C1,C2,…,Ck
谱聚类函数代码
function C=spectralCluster(X,K,Sigma)
format long;warning off
% 各维度数据归一化
X=X./max(abs(X),[],1:ndims(X));% 计算相似矩阵即||x_i-x_j||^2
S=pdist2(X,X).^2;% 高斯核函数RBF计算邻接矩阵
W=exp(-S./(2.*Sigma.*Sigma));% 计算度矩阵
D=diag(sum(W,2));% 计算拉普拉斯矩阵
L=D-W;
L_norm=D^(-1/2)*L*D^(-1/2);% 求特征向量 V
% 'SM':绝对值最小特征值排列
[V, ~]=eigs(L_norm,K,'SM');% 按行标准化
V_norm=V./vecnorm(V.')';% 对特征向量合并矩阵的行向量求k-means
C=kmeans(V_norm,K);
end
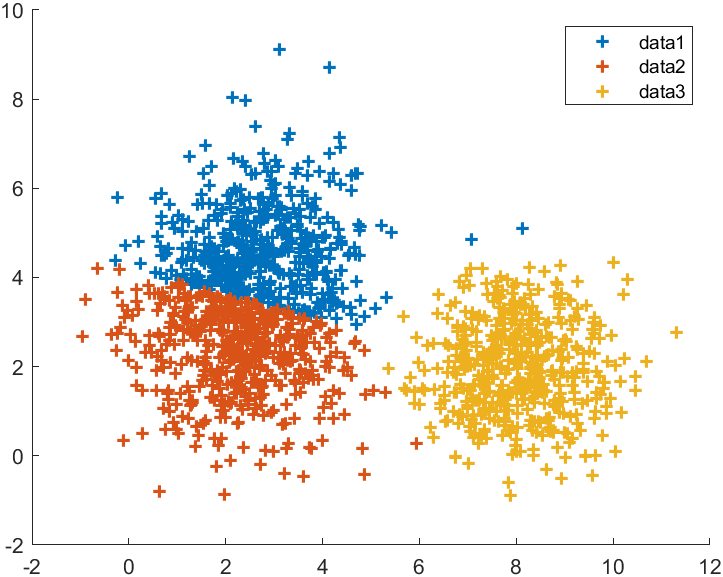
示例一:凸散点
% 随机数据生成
PntSet1=mvnrnd([2 3],[1 0;0 2],500);
PntSet2=mvnrnd([3 4],[1 0;0 2],500);
PntSet3=mvnrnd([8 2],[1 0;0 1],500);
X=[PntSet1;PntSet2;PntSet3];% 谱聚类
figure(1)
K=3;
Sigma=1;
C=spectralCluster(X,K,Sigma);
hold on
for i=1:Kplot(X(C==i,1),X(C==i,2),'+','LineWidth',1.5)
end
legend% 传统k-means
figure(2)
C=kmeans(X,K);
hold on
for i=1:Kplot(X(C==i,1),X(C==i,2),'+','LineWidth',1.5)
end
与k-means聚类效果相似,上图为谱聚类,下图为传统k-means:
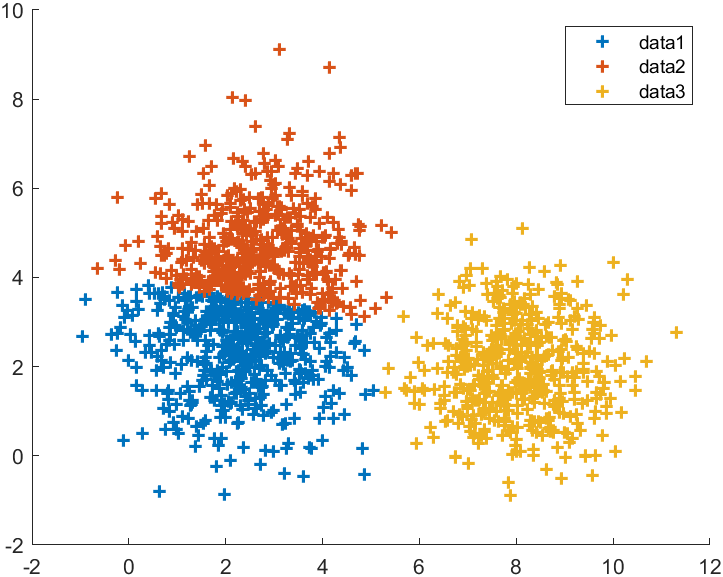
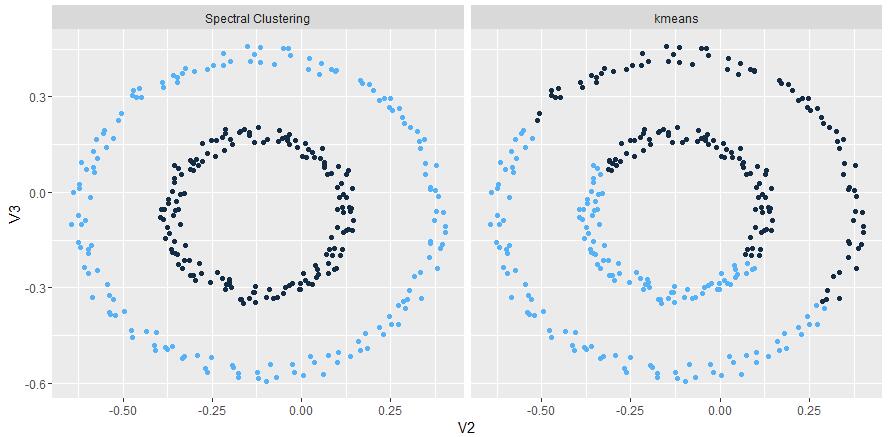
示例二:双圆
% 随机数据生成
t=linspace(0,2*pi,100)';
PntSet1=[cos(t),sin(t)].*[2.1,2.5]+rand([100,2]);
PntSet2=[cos(t),sin(t)].*[10.5,12.6]+rand([100,2]);
X=[PntSet1;PntSet2];% 谱聚类
figure(1)
K=2;
Sigma=.1;
C=spectralCluster(X,K,Sigma);
hold on
for i=1:Kplot(X(C==i,1),X(C==i,2),'+','LineWidth',1.5)
end
legend% 传统k-means
figure(2)
C=kmeans(X,K);
hold on
for i=1:Kplot(X(C==i,1),X(C==i,2),'+','LineWidth',1.5)
end
legend
上图为谱聚类,下图为传统k-means:
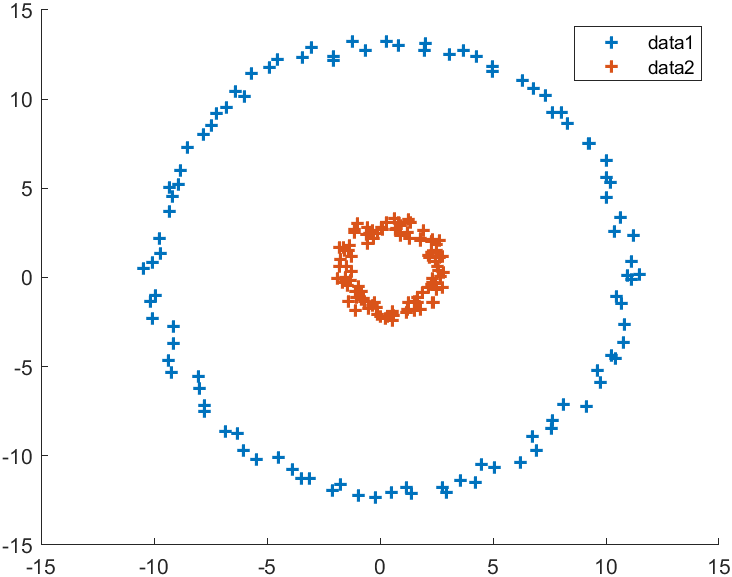
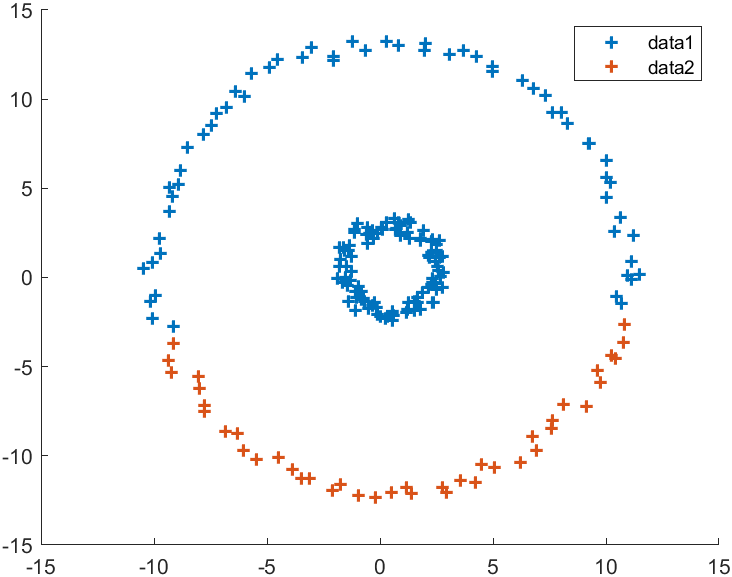
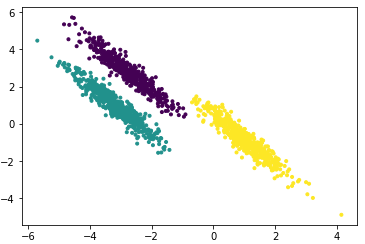
示例三:slandarer
X=load('slandarer.mat');
X=X.X;% 谱聚类
K=9;
Sigma=.02;
C=spectralCluster(X,K,Sigma);
hold on
for i=1:Kplot(X(C==i,1),X(C==i,2),'+','LineWidth',1.5)
end
legend% 传统k-means
figure(2)
C=kmeans(X,K);
hold on
for i=1:Kplot(X(C==i,1),X(C==i,2),'+','LineWidth',1.5)
end
legend
数据源自文末压缩包内slandarer.mat,上图为谱聚类,下图为传统k-means:


示例四:双弧
X=load('arcs2.mat');
X=X.X;% 谱聚类
figure(1)
K=2;
Sigma=.05;
C=spectralCluster(X,K,Sigma);
hold on
for i=1:Kplot(X(C==i,1),X(C==i,2),'+','LineWidth',1.5)
end
legend% 传统k-means
figure(2)
C=kmeans(X,K);
hold on
for i=1:Kplot(X(C==i,1),X(C==i,2),'+','LineWidth',1.5)
end
legend
数据源自文末压缩包内arcs2.mat,上图为谱聚类,下图为传统k-means:

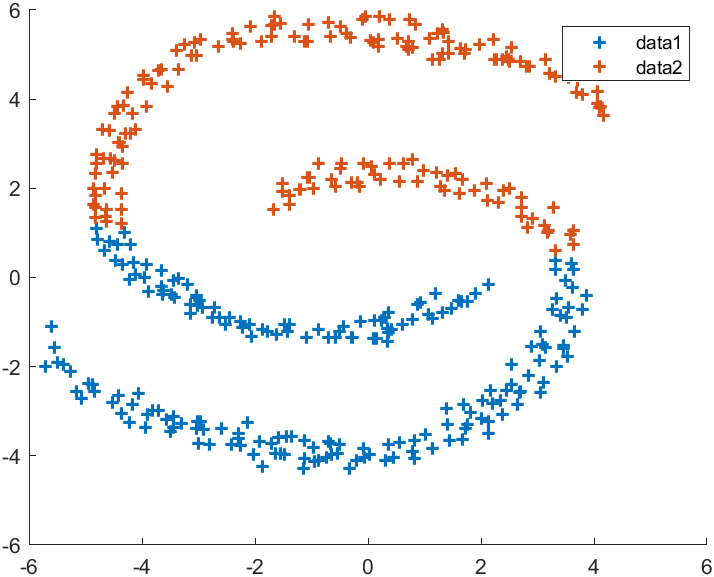
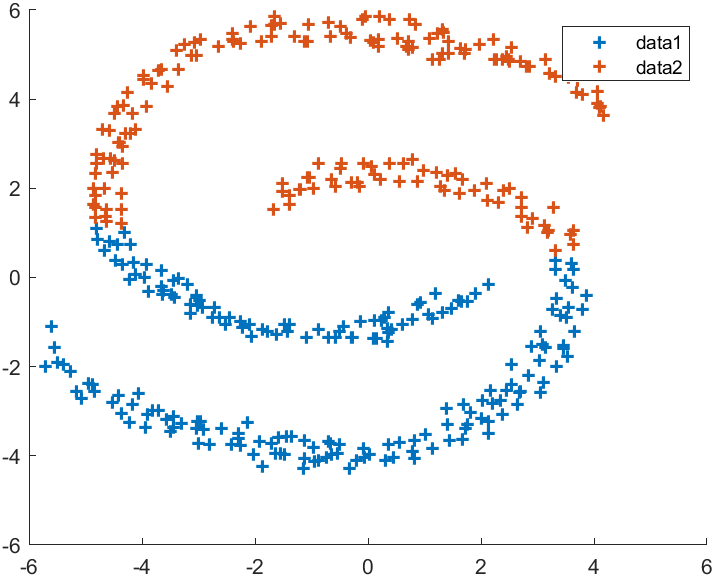
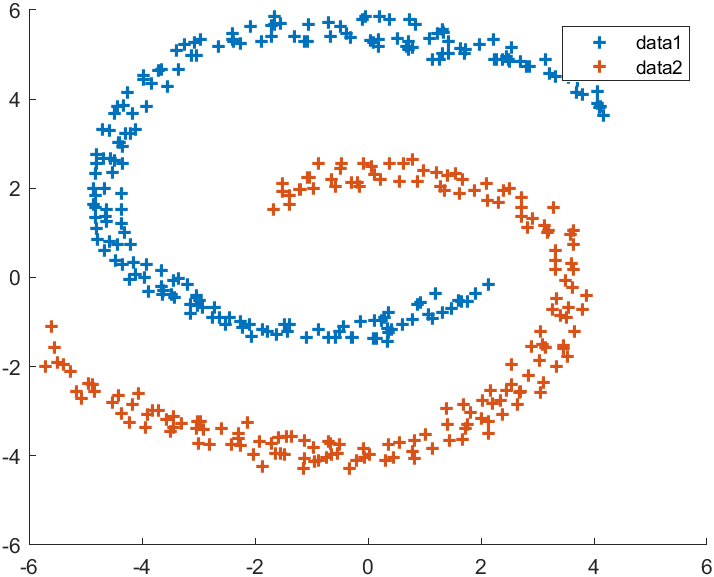
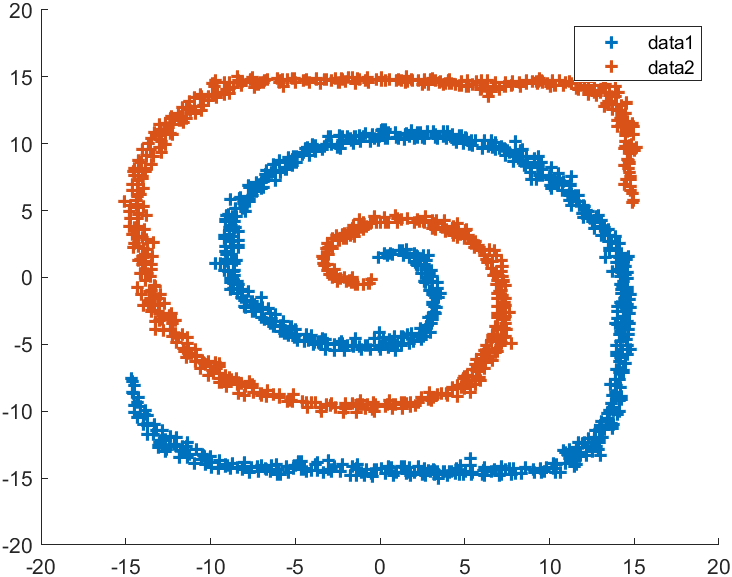
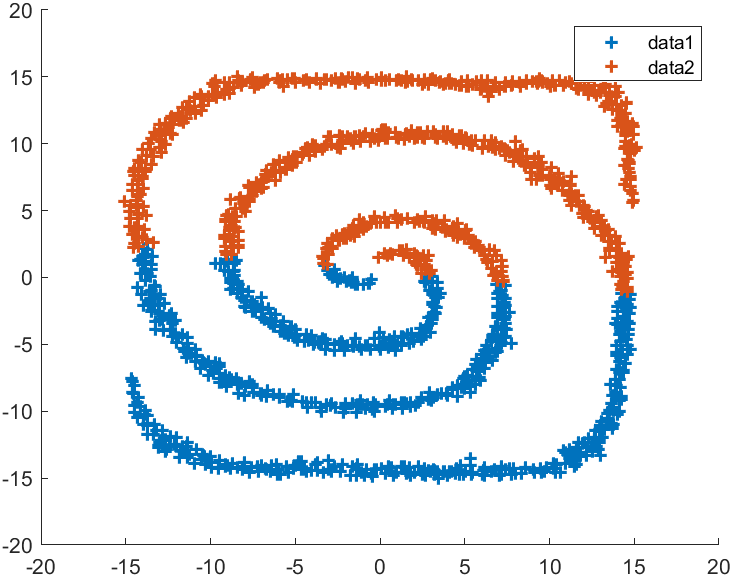
示例五:双螺旋
X=load('screw.mat');
X=X.X;% 谱聚类
figure(1)
K=2;
Sigma=.02;
C=spectralCluster(X,K,Sigma);
hold on
for i=1:Kplot(X(C==i,1),X(C==i,2),'+','LineWidth',1.5)
end
legend% 传统k-means
figure(2)
C=kmeans(X,K);
hold on
for i=1:Kplot(X(C==i,1),X(C==i,2),'+','LineWidth',1.5)
end
legend
数据源自文末压缩包内screw.mat,上图为谱聚类,下图为传统k-means:
完
全部示例请:
【谱聚类】
更新时会跟进更新以下连接:
【链接】:https://pan.baidu.com/s/1PFlVop1NwYPWDzuwhc2gxw?pwd=slan
【提取码】:slan