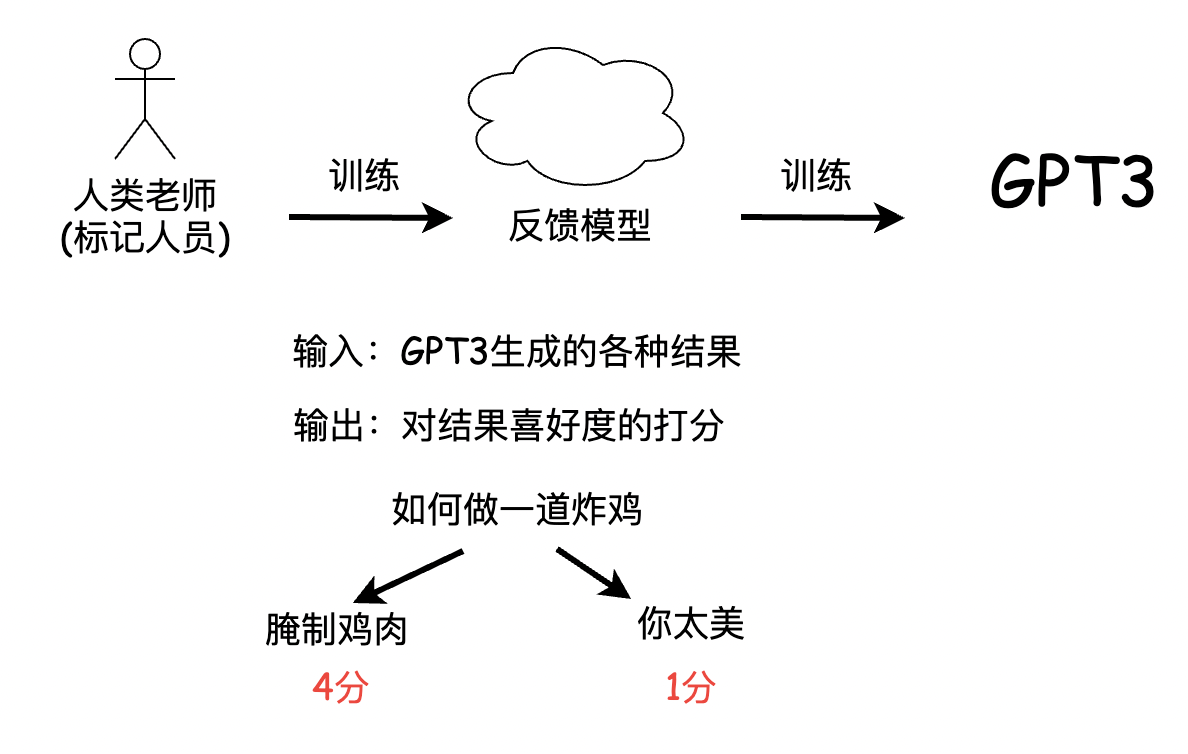
随着深度学习技术的发展,语言模型也得到了长足的进步。其中,GPT系列模型一直受到广泛关注。GPT全称为Generative Pre-trained Transformer,是一种基于Transformer架构的预训练语言模型。ChatGPT则是在GPT系列的基础上进行了改进,专门用于对话生成。本文将详细介绍ChatGPT模型的原理及其在AI行业中的重要意义。
一、GPT模型的基础
GPT模型是由OpenAI团队提出的预训练语言模型,其基础是Transformer模型。Transformer模型是2017年提出的一种全新的深度学习模型,用于解决序列到序列(Sequence-to-Sequence)的任务,比如机器翻译、文本摘要等。它由编码器(Encoder)和解码器(Decoder)组成,其中编码器将输入序列映射成一组隐藏表示,解码器则将隐藏表示映射回输出序列。Transformer模型采用自注意力机制(Self-Attention)来实现序列建模,可以并行计算,大大提高了模型的训练效率和性能。
GPT模型在Transformer模型的基础上进行了改进,主要有以下三点:
1.单向语言模型
GPT模型是一种单向语言模型,即只使用前面的词来预测后面的词。这与双向语言模型(如BERT)不同,双向语言模型同时利用前后上下文信息进行预测,但也因此无法用于生成任务。
2.自回归模型
GPT模型是一种自回归模型,即在生成下一个词时,会将前面的所有词都作为输入。这种方法可以保证生成的句子流畅且有逻辑,但也会导致生成速度较慢。
3.基于Transformer的解码器
GPT模型只使用了Transformer的解码器,即将前面生成的词作为输入来生成下一个词。这样可以避免编码器过度捕捉输入信息而导致生成的内容过于严格,同时也减少了模型训练的难度。
二、ChatGPT模型的改进
与GPT模型相比,ChatGPT模型的改进主要体现在以下两点:
1.对话式学习
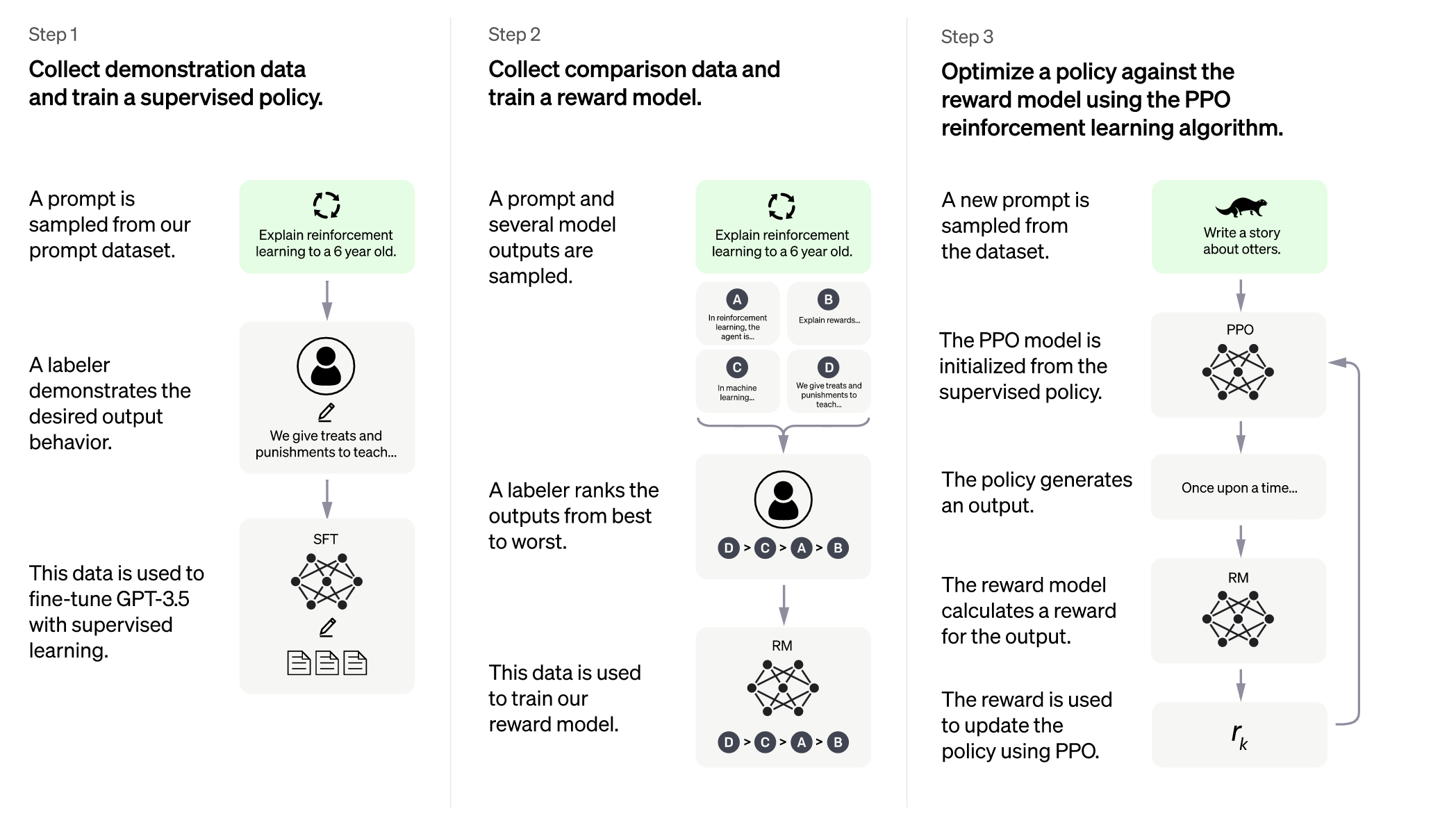
ChatGPT模型采用了对话式学习(Conversation-based Learning)的方式进行训练。在对话式学习中,模型需要对话历史进行建模,而不仅仅是对单个句子进行建模。这样可以更好地提高模型的对话生成能力和流畅度。在对话式学习中,模型会将前面的对话历史作为输入,生成下一条回复。这样可以模拟真实对话中的情境,使得模型更适合用于聊天机器人等对话生成任务。
2.多轮对话生成
与单轮对话生成不同,多轮对话生成需要模型能够在前文的基础上生成后续回复,同时也要保证回复的连贯性和逻辑性。ChatGPT模型在多轮对话生成方面进行了优化,采用了可持续性对话生成(Continual Conversation Generation)的方法。该方法可以使模型在多轮对话中更好地维护对话的连贯性和一致性。
三、ChatGPT模型的应用
ChatGPT模型的出现对AI行业有着重要的意义。首先,它可以用于构建智能聊天机器人,实现人机对话的自然交互。其次,ChatGPT模型还可以应用于智能客服、语音助手、社交媒体等多个领域。通过将ChatGPT模型集成到各种应用中,可以大大提高应用的智能化程度和用户体验。
总结
ChatGPT模型是一种基于GPT系列模型的对话生成模型。它采用了对话式学习和可持续性对话生成的方法,可以在多轮对话中生成连贯流畅的回复。ChatGPT模型的应用范围广泛,可以用于构建智能聊天机器人、智能客服、语音助手等多个领域。ChatGPT模型的出现,对于推动人机交互的智能化和推动AI技术的发展具有重要的意义。