如果你在网上快速的做一个关于 UUID 和 MySQL 的搜索,你会得到相当多的结果。以下是一些例子:
- 存储 UUID 和 生成列
- 在 MySQL 中存储 UUID 的值
- 说明 InnoDB 中的主键模型及其对磁盘使用的影响
- 主键选型之战 UUID vs. INT
- GUID / UUID 的性能突破
- 到底需不需要 UUID?
另:以上文章链接请在文章结尾处查看
那么,像这样一个众所周知的话题还需要更多关注吗?显然是的。
尽管大多数帖子都警告人们不要使用 UUID,但它们仍然非常受欢迎。这种受欢迎的原因是,这些值可以很容易地由远程设备生成,并且冲突的概率非常低。这篇文章,目标是总结其他人已经写过的东西,并希望能带来一些新的想法。
UUID 是什么?
UUID 代表通用唯一标识符,在 RFC 4122 中定义。它是一个 128 位数字,通常以十六进制表示,并用破折号分成五组。典型的UUID值如下所示:
RFC 4122:https://tools.ietf.org/html/rfc4122
yves@laptop:~$ uuidgen 83fda883-86d9-4913-9729-91f20973fa52一共有 5 种正式的 UUID 值类型(版本 1 - 5),但最常见的是:基于时间的(版本 1 / 2)和纯随机的(版本 3)。 自 1970 年 1 月 1 日起,对 10ns 内基于时间类型的 7.5 个字节(60位)形式的 UUID 数目进行编码,并以 "time-low"-"time-mid"-"time-hi" 的格式进行划分。 缺少的 4 位是用作 time-hi 字段前缀的版本号。前三组的 64 位值就这么产生了。 最后两组是时钟序列,每次修改时钟都会增加一个值以及一个主机唯一标识符。 大多数情况下,主机主网络接口的 MAC 地址用作唯一标识符。
使用基于时间的 UUID 值时,需要注意以下几点:
- 可以从前三个字段确定生成值的大概时间
- 连续的 UUID 值之间有许多重复字段
- 第一个字段 "time-low" 每 429 秒滚动一次
- MySQL UUID 函数产生 1 版本的值
这是一个使用 "uuidgen" (Unix 工具)生成基于时间的值的示例:
yves@laptop:~$ for i in $(seq 1 500); do echo "$(date +%s): $(uuidgen -t)"; sleep 1; done1573656803: 572e4122-0625-11ea-9f44-8c16456798f11573656804: 57c8019a-0625-11ea-9f44-8c16456798f11573656805: 586202b8-0625-11ea-9f44-8c16456798f1...1573657085: ff86e090-0625-11ea-9f44-8c16456798f11573657086: 0020a216-0626-11ea-9f44-8c16456798f1...1573657232: 56b943b2-0626-11ea-9f44-8c16456798f11573657233: 57534782-0626-11ea-9f44-8c16456798f11573657234: 57ed593a-0626-11ea-9f44-8c16456798f1...第一个字段翻转(t=1573657086),第二个字段递增。第一个字段再次看到相似的值大约需要 429s。第三个字段每年大约更改一次。最后一个字段在给定主机上是静态的,MAC 地址在笔记本电脑上使用:
yves@laptop:~$ ifconfig | grep ether | grep 8c ether 8c:16:45:67:98:f1 txqueuelen 1000 (Ethernet)另一个经常看到的 UUID 是版本 4,即纯随机版本。默认情况下 "uuidgen" 工具会生成 UUID 版本4 的值:
yves@laptop:~$ for i in $(seq 1 3); do uuidgen; done6102ef39-c3f4-4977-80d4-742d15eefe6614d6e343-028d-48a3-9ec6-77f1b703dc8fac9c7139-34a1-48cf-86cf-a2c823689a91唯一的 “重复”值是第三个字段开头的版本 "4"。 其他 124 位都是随机的。
UUID 的值到底有什么问题?
为了了解使用 UUID 值作为主键的影响,重要的是要检查 InnoDB 如何组织数据。 InnoDB 将表的行存储在主键的 b-tree(聚簇索引)中。 聚簇索引通过主键自动对行进行排序。
当插入具有随机主键值的新数据时,InnoDB 必须找到该行所属的页面,如果尚不存在该页面,则将其加载到缓冲池中,插入该行,然后最终将页面刷新回 磁盘。如果使用纯随机值和大表,则所有 b-tree 的叶子页都易于接收新行,没有热页。不按主键顺序插入的行会导致页面拆分,从而导致较低的填充系数。对于比缓冲池大得多的表,插入很可能需要从磁盘读取表页。缓冲池中已插入新行的页面将变为脏页。在需要刷新到磁盘之前,该页面接收第二行的几率非常低。在大多数情况下,每次插入都会导致两次 IOP(一读一写)。第一个主要是对 IOP 速率的影响,它是可伸缩性的主要限制因素。
因此,获得良好性能的唯一方法是使用具有低延迟和高耐久性的存储。这是第二个主要的影响因素。对于聚集索引,辅助索引将主键值用作指针。主键 b-tree 的叶子来存储行,而二级索引 b-tree 的叶子来存储主键值。
假设一张一百万行的表格具有 UUID 主键和五个辅助索引。通过阅读上一段,我们知道每行主键值存储六次。这意味着总共有六百万个char(36) 类型的值,意味着数据总量 216 GB。这只是冰山一角,因为表通常具有指向其他表的外键(无论是否显式)。当架构基于 UUID 值时,所有支持的列和索引均为 char(36) 类型。基于 UUID 的架构,大约 70% 的存储用于这些值。
如果这还不够,那么使用 UUID 值会产生第三个重要影响。CPU 一次最多可比较 8 个字节的整数值,但 UUID 值每个字符之间都要比较。数据库很少受到 CPU 的限制,但这仍然增加了查询的延迟。如果还不确定,请看一下整数与字符串之间的性能比较:
mysql> select benchmark(100000000,2=3);+--------------------------+| benchmark(100000000,2=3) |+--------------------------+| 0 |+--------------------------+1 row in set (0.96 sec)mysql> select benchmark(100000000,'df878007-80da-11e9-93dd-00163e000002'='df878007-80da-11e9-93dd-00163e000003');+----------------------------------------------------------------------------------------------------+| benchmark(100000000,'df878007-80da-11e9-93dd-00163e000002'='df878007-80da-11e9-93dd-00163e000003') |+----------------------------------------------------------------------------------------------------+| 0 |+----------------------------------------------------------------------------------------------------+1 row in set (27.67 sec)当然,以上示例是最坏的情况,但至少可以说明问题的范围。整数的比较大约快 28 倍。即使差值在 char 值中迅速出现,也仍然比 UUID 慢了约 2.5 倍:
mysql> select benchmark(100000000,'df878007-80da-11e9-93dd-00163e000002'='ef878007-80da-11e9-93dd-00163e000003');+----------------------------------------------------------------------------------------------------+| benchmark(100000000,'df878007-80da-11e9-93dd-00163e000002'='ef878007-80da-11e9-93dd-00163e000003') |+----------------------------------------------------------------------------------------------------+| 0 |+----------------------------------------------------------------------------------------------------+1 row in set (2.45 sec)让我们探索一些解决这些问题的解决方案。
值的尺寸
UUID,hash 和 token 的默认表示形式通常是十六进制表示法。对于基数,可能的值数(每个字节只有 16 个)远没有效率。使用其他表示形式(如 base64 或直接二进制)怎么办?我们可以节省多少?性能如何受到影响?
让我们以 base64 表示法开始。每个字节的基数为 64(六十四进制),因此在 3 个字节在 base64 中需要 来表示 2 个字节的实际值。一个 UUID 的值由 16 个字节的数据组成,如果我们除以 3,则余数为 1。为处理该问题,base64 编码在末尾添加了 '==' :
mysql> select to_base64(unhex(replace(uuid(),'-','')));+------------------------------------------+| to_base64(unhex(replace(uuid(),'-',''))) |+------------------------------------------+| clJ4xvczEeml1FJUAJ7+Fg== |+------------------------------------------+1 row in set (0.00 sec)如果知道编码实体的长度(例如 UUID 的长度),我们就可以删除 "==",因为它只是一种长度配重。因此,以 base64 编码的 UUID 的长度为 22。
下一步的逻辑步骤是直接以二进制格式存储值。这是最理想的格式,但是在 MySQL 客户端中显示值不太方便。
那么,尺寸对性能有何影响?为了说明影响,我在具有以下定义的表中插入了随机的 UUID 值。
CREATE TABLE `data_uuid` ( `id` char(36) NOT NULL, PRIMARY KEY (`id`)) ENGINE=InnoDB DEFAULT CHARSET=latin1;为默认的十六进制表示形式。对于 base64,"id" 列定义为 char(22),而 binary(16) 用于二进制示例。数据库服务器的缓冲池大小为 128M,其 IOP 限制为 500。插入是在单个线程上完成的。
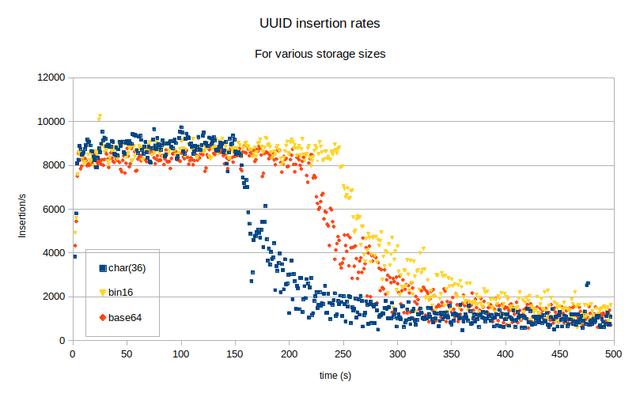
使用 UUID 值的不同表示形式的表的插入率
在所有情况下,插入速率最初都是受 CPU 限制的,但是一旦表大于缓冲池,则插入将很快成为 IO 限制。对于 UUID 值使用较小的表示形式只会使更多的行进入缓冲池,但从长远来看,这对性能没有真正的帮助,因为随机插入顺序占主导地位。如果使用随机 UUID 值作为主键,则性能会受到您可以承受的内存量的限制。
方案 1:使用伪随机顺序保存
如我们所见,最重要的问题是值的随机性。新的行可能会在任何表的子页中结束。因此,除非整个表都已加载到缓冲池中,否则它意味着读 IOP,最后是写 IOP。我的同事 David Ducos 为这个问题提供了一个很好的解决方案,但是一些客户不想 UUID 值中提取信息,例如生成时间戳。
如果我们只是稍微减少值的随机性,以使几个字节的前缀在一个时间间隔内不变,该怎么办? 在该时间间隔内,只需要将整个表的一小部分(对应于前缀的基数)存储在内存中,以保存读取的 IOP。 这也将增加页面在刷新到磁盘之前接收第二次写入的可能性,从而减少了写入负载。让我们考虑以下 UUID 生成函数:
drop function if exists f_new_uuid; delimiter ;;CREATE DEFINER=`root`@`%` FUNCTION `f_new_uuid`() RETURNS char(36) NOT DETERMINISTICBEGIN DECLARE cNewUUID char(36); DECLARE cMd5Val char(32); set cMd5Val = md5(concat(rand(),now(6))); set cNewUUID = concat(left(md5(concat(year(now()),week(now()))),4),left(cMd5Val,4),'-', mid(cMd5Val,5,4),'-4',mid(cMd5Val,9,3),'-',mid(cMd5Val,13,4),'-',mid(cMd5Val,17,12)); RETURN cNewUUID;END;;delimiter ;函数说明
UUID 值的前四个字符来自当前年份和星期编号的串联 MD5 哈希值。当然,该值在一个星期内是静态的。UUID 值的其余部分来自随机值的 MD5 和当前时间,精度为 1us。第三个字段以 "4" 为前缀,表示它是版本 4 的 UUID 类型。有 65536 个可能的前缀,因此在一周内,内存中仅需要表行的 1/65536,以避免在插入时读取 IOP。这更容易管理,一个 1TB 的表在缓冲池中只需要大约 16MB 的空间即可支持插入。
方案 2:将 UUID 映射成整数
即使您使用使用 binary(16) 存储的伪有序的 UUID 值,它仍然是非常大的数据类型,这会增大数据集的大小。请记住,InnoDB 将主键值用作辅助索引中的指针。如果我们将所有的 UUID 值存储在映射表中怎么办? 映射表将定义为:
CREATE TABLE `uuid_to_id` ( `id` int(10) unsigned NOT NULL AUTO_INCREMENT, `uuid` char(36) NOT NULL, `uuid_hash` int(10) unsigned GENERATED ALWAYS AS (crc32(`uuid`)) STORED NOT NULL, PRIMARY KEY (`id`), KEY `idx_hash` (`uuid_hash`)) ENGINE=InnoDB AUTO_INCREMENT=2590857 DEFAULT CHARSET=latin1;重要的是要注意 uuid_to_id 表不会强制 UUID 的唯一性。idx_hash 索引的作用有点像布隆过滤器。如果没有匹配的哈希值,我们肯定会知道表格中没有 UUID 值,但是如果有匹配的哈希值,我们就必须使用存储的 UUID 值进行验证。为帮助我们,请创建一个 SQL 函数:
DELIMITER ;;CREATE DEFINER=`root`@`%` FUNCTION `f_uuid_to_id`(pUUID char(36)) RETURNS int(10) unsigned DETERMINISTICBEGIN DECLARE iID int unsigned; DECLARE iOUT int unsigned; select get_lock('uuid_lock',10) INTO iOUT; SELECT id INTO iID FROM uuid_to_id WHERE uuid_hash = crc32(pUUID) and uuid = pUUID; IF iID IS NOT NULL THEN select release_lock('uuid_lock') INTO iOUT; SIGNAL SQLSTATE '23000' SET MESSAGE_TEXT = 'Duplicate entry', MYSQL_ERRNO = 1062; ELSE insert into uuid_to_id (uuid) values (pUUID); select release_lock('uuid_lock') INTO iOUT; set iID = last_insert_id(); END IF; RETURN iID;END ;;DELIMITER ;该函数检查 uuid_to_id 表中是否存在通过验证的 UUID 值,如果确实存在,则返回匹配的 id 值,否则将插入 UUID 值并返回 last_insert_id。为了防止同时提交相同的 UUID 值,我添加了一个数据库锁。数据库锁限制了解决方案的可伸缩性。如果您的应用程序无法在很短的时间内提交两次请求,则可以删除该锁。
替代方案结论
现在,让我们看一下使用这些替代方案的插入率。
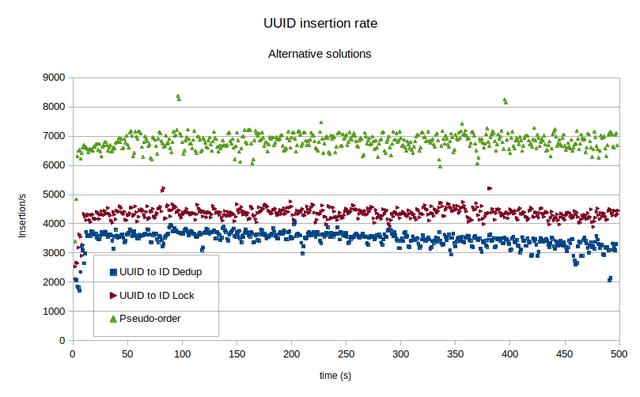
使用 UUID 值作为主键插入表的方法
伪顺序结果很好。在这里,我修改了算法,以使 UUID 前缀保持一分钟而不是一星期不变,以便更好地适应测试环境。即使伪顺序解决方案表现良好,也请记住,它仍然会使架构膨胀,总体而言,性能提升可能不会那么大。
尽管由于所需的附加 DML 导致插入率较小,但映射到整数值会使架构与 UUID 值分离。这些表现在使用整数作为主键。此映射几乎消除了使用 UUID 值的所有可伸缩性问题。尽管如此,即使在 CPU 和 IOP 受限的小型虚拟机上,UUID 映射技术也可以每秒产生近 4000次插入。在上下文中,这意味着每小时有 1400 万行,每天 3.45 亿行和每年 1260 亿行。这样的速度可能符合大多数要求。唯一的增长限制因素是哈希索引的大小。当哈希索引太大而无法容纳在缓冲池中时,性能将开始下降。
UUID 之外的选择
当然,还有其他生成唯一 ID 的可能性。MySQL 函数 UUID_SHORT() 使用的方法很有趣。诸如智能手机之类的远程设备可以使用 UTC 时间而不是服务器正常运行时间。这是一个建议:
(Seconds since January 1st 1970) << 32+ (lower 2 bytes of the wifi MAC address) << 16+ 16_bits_unsigned_int++;16 位计数器应初始化为随机值,并允许翻转。两个产生相同 ID 的设备的几率很小。它必须大约同时发生,两个设备的 MAC 必须具有相同的低字节,并且它们的 16 位计数器必须以相同的增量递增。
https://my.oschina.net/actiontechoss/blog/3144984