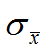关联规则挖掘是一种基于规则的机器学习算法,该算法可以在大数据库中发现感兴趣的关系。它的目的是利用一些度量指标来分辨数据库中存在的强规则。也即是说关联规则挖掘是用于知识发现,而非预测,所以是属于无监督的机器学习方法。
“尿布与啤酒”是一个典型的关联规则挖掘的例子,沃尔玛为了能够准确了解顾客在其门店的购买习惯,对其顾客的购物行为进行购物篮分析,想知道顾客经常一起购买的商品有哪些。沃尔玛利用所有用户的历史购物信息来进行挖掘分析,一个意外的发现是:"跟尿布一起购买最多的商品竟是啤酒!
关联规则挖掘算法不仅被应用于购物篮分析,还被广泛的应用于网页浏览偏好挖掘,入侵检测,连续生产和生物信息学领域。
与序列挖掘算法不同的是,传统的关联规则挖掘算法通常不考虑事务内或者事件之间的顺序。
支持度和置信度
那么我们如何能够从所有可能规则的集合中选择感兴趣的规则呢?需要利用一些度量方法来筛选和过滤,比较有名的度量方法是最小支持度(minimum support)和最小置信度(minimum confidence)。
假定我们一个数据库包含5条事务,每行表示一个购物记录,1 表示购买,0 表示没有购买,如下图表格所示:
ID | milk | bread | butter | beer | diapers
----|------|------|------|----
1 | 1| 1 | 0 | 0 | 0
2| 0| 0| 1| 0| 0
3| 0| 0| 0| 1| 1
4| 1| 1| 1| 0| 0
5| 0| 1| 0| 0| 0
让 X,Y 各表示为一个 item-set, X ⇒ Y 表示为一条规则(尿布 ⇒ 啤酒 就是一条规则),用 T 表示为事务数据库(并不是说只局限于事务数据库)。
支持度(Support)
支持度表示 item-set 在整个 T 中出现的频率。假定 T 中含有 N 条数据,那么支持度的计算公式为:

譬如在上面的示例数据库中,{beer, diaper} 的支持度为 1/5 = 0.2。5 条事务中只有一条事务同事包含 beer和 diaper ,实际使用中我们会设置一个最低的支持度(minimum support),那些大于或等于最低支持度的 X 称之为频繁的 item-set 。
置信度(Confidence)
置信度表示为规则 X ⇒ Y 在整个 T 中出现的频率。而置信度的值表示的意思是在包含了 X 的条件下,还含有 Y 的事务占总事务的比例。同样假定 T 中含有 N 条数据,那么置信度的计算公式为:

譬如再上面的示例数据库中,{beer, diaper} 的置信度为 0.2/0.2 = 1。表面在所有包含 beer 的事务中都会一定包含 diaper。同样的,在实际使用中我们会设置一个最低置信度,那些大于或等于最小置信度的规则我们称之为是有意义的规则。
相关性度量
有时候使用支持度和置信度挖掘到的规则可能是无效的。
举个例子:
10000 个事务中, 6000 个事务包含计算机游戏, 7500 个包含游戏机游戏, 4000 个事务同时包含两者。关联规则(计算机游戏 ⇒ 游戏机游戏) 支持度为 0.4 ,看似很高,但其实这个关联规则是一个误导。在用户购买了计算机游戏后有 (4000÷6000) = 0.667 的概率的去购买游戏机游戏,而在没有任何前提条件时,用户反而有 (7500÷10000) = 0.75的概率去购买游戏机游戏,也就是说设置了购买计算机游戏这样的前置条件反而会降低用户去购买游戏机游戏的概率,所以计算机游戏和游戏机游戏是相斥的,也即表明是独立的。
因此我们可以通过下面的一些相关性度量方法来筛选挖掘到的规则。
提升度(Lift)
提升度可以用来判断规则 X ⇒ Y 中的 X 和 Y 是否独立,如果独立,那么这个规则是无效的。
计算提升度的公式如下:

如果该值等于 1 ,说明两个条件没有任何关联。如果小于 1 ,说明 X 与 Y 是负相关的关系,意味着一个出现可能导致另外一个不出现。大于 1 才表示具有正相关的关系。一般在数据挖掘中当提升度大于 3 时,我们才承认挖掘出的关联规则是有价值的。
他可以用来评估一个出现提升另外一个出现的程度。
提升度是一种比较简单的判断手法,实际中受零事务(也即不包含 X 也不包含 Y 的事务)的影响比较大。所以如果数据中含有的零事务数量较大,该度量则不合适使用。
全置信度 和 最大置信度
给定两个项集 X 和 Y ,其全置信度为

不难知道,最大置信度为

全置信度和最大置信度的取值都是从 0 ~ 1 ,值越大,联系越大。
该度量是不受零事务影响的。
KULC 度量 + 不平衡比(IR)
给定两个项集 X 和 Y,其 Kulczynski(Kulc) 度量定义为:

可以看做是两个置信度的平均值,同样取值也是从 0 ~ 1,值越大,联系越大,关系越大。
该度量同样也是不受零事务影响的。
Apriori 算法
在执行算法之前,用户需要先给定最小的支持度和最小的置信度。
生成关联规则一般被划分为如下两个步骤:
1、利用最小支持度从数据库中找到频繁项集。
给定一个数据库 D ,寻找频繁项集流程如下图所示

频繁项集的流程示意图
C1 中 {1} 的支持度为 2/4 = 0.5 表示在 D 中的 4 条事务中,{1} 出现在其中的两条事务中,以后几个步骤的支持度计算方式也是类似的。假定给定的最小支持度为 0.5,那么最后我们可以得到一个包含 3 个项的频繁项集 {2 3 5}。
另外,从图中我们可以看到 itemset 中所包含的 item 是从 1 增长到 3 的。并且每次增长都是利用上一个 itemset 中满足支持度的 item 来生成的,这个过程称之为候选集生成(candidate generation)。譬如说 C2 里就不包含 C1 中的 4 。
2、利用最小置信度从频繁项集中找到关联规则。
同样假定最小的置信度为 0.5 ,从频繁项集 {2 3 5} 中我们可以发现规则 {2 3} ⇒ {5} 的置信度为 1 > 0.5 ,所以我们可以说 {2 3} ⇒ {5} 是一个可能感兴趣的规则。
从第一步中我们看出每次计算支持度都需要扫描数据库,这会造成很大的 I/O 开销,所以有很多变种的算法都会在该问题上进行优化(FP-Growth)。此外如何有效的生成候选集也是很多变种算法优化的问题之一(Apriori-all)。
总结
- 关联规则是无监督的学习算法,能够很好的用于知识的发现。
- 缺点是很难严重算法的有效性,一般只能够通过肉眼观察结果是否合理。
作者:曾梓华
链接:https://www.jianshu.com/p/7d459ace31ab
來源:简书
简书著作权归作者所有,任何形式的转载都请联系作者获得授权并注明出处。