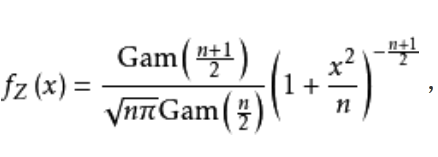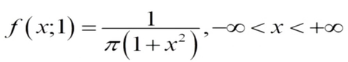Hello,大家好!最近有在学习一些有关偏态分布的数理知识,但在搜偏 t t t分布的相关资料的时候感觉比较散,所以做个整理,主要参考的书籍是Azzalini在2014年出版的一本有关偏态分布族的书《The Skew-Normal and Related Families》,大家可以文末获取,有哪里理解不对的地方,还请各位大佬多多指正。
目录
- 偏 t t t分布定义
- 资源获取
偏 t t t分布定义
偏 t t t分布的生成,可以通过调节 t t t分布的尾部厚度来实现,那么我们先来写下 t t t分布的概率密度函数
t ( x ; ν ) = Γ ( ν + 1 2 ) π ν Γ ( ν 2 ) ( 1 + x 2 ν ) − ν + 1 2 , x ∈ R , t(x;\nu)=\frac{\Gamma(\frac{\nu+1}{2})}{\sqrt{\pi \nu}\Gamma(\frac{\nu}{2})}\big( 1+\frac{x^2}{\nu} \big)^{-\frac{\nu+1}{2}},\qquad x \in \mathbb{R}, t(x;ν)=πνΓ(2ν)Γ(2ν+1)(1+νx2)−2ν+1,x∈R,
其中, ν \nu ν代表自由度。
性质1.1: 用 f 0 f_0 f0表示 R d \mathbb{R}^d Rd上的概率密度函数,用 G ( ⋅ ) G(\cdot) G(⋅)表示一个连续分布函数,用 w ( ⋅ ) w(\cdot) w(⋅)表示 R d \mathbb{R}^d Rd上的实值函数,使得
f 0 ( − x ) = f 0 ( x ) , w ( − x ) = − w ( x ) , G 0 ( − y ) = 1 − G 0 ( y ) f_0(-x)=f_0(x), \quad w(-x)=-w(x), \quad G_0(-y)=1-G_0(y) f0(−x)=f0(x),w(−x)=−w(x),G0(−y)=1−G0(y)
对于 x ∈ R d x \in \mathbb{R}^d x∈Rd, y ∈ R y \in \mathbb{R} y∈R,则
f ( x ) = 2 f 0 ( x ) G { w ( x ) } f(x)=2f_0(x)G\{ w(x)\} f(x)=2f0(x)G{w(x)}
表示为 R d \mathbb{R}^d Rd上的概率密度函数。
那么对于 t t t分布,我们就可以通过性质1.1来生成尾部厚度不一的偏 t t t分布,根据以往的研究,以线性形式来引入不对称的版本,即
2 t ( x ; ν ) T ( α x ; ν ) 2t(x;\nu)T(\alpha x;\nu) 2t(x;ν)T(αx;ν)
其中, T ( ⋅ ; ν ) T(\cdot;\nu) T(⋅;ν)表示 t t t分布的累积分布函数, α \alpha α表示偏度参数。
除了这种构建方式外,还可以通过类似于 t t t分布随机变量的构建方式来获得,并且这种方式更被普遍引用,同样,我们先写出 t t t分布的随机变量
Z = Z 0 V , Z=\frac{Z_0}{\sqrt{V}}, Z=VZ0,
其中, Z 0 ∼ N ( 0 , 1 ) Z_0 \sim \mathrm{N}(0,1) Z0∼N(0,1)和 V ∼ χ ν 2 / ν V \sim \chi_{\nu}^2 / \nu V∼χν2/ν为独立随机变量。
相应地,通过将 Z 0 Z_0 Z0的正态分布假设替换为 Z 0 ∼ S N ( 0 , 1 , α ) Z_0 \sim \mathrm{SN}(0,1,\alpha) Z0∼SN(0,1,α)来获得偏 t t t分布的公式。在这种情况下,若 h ( ⋅ ) h(\cdot) h(⋅)表示 V V V的密度函数,则随机变量 Z Z Z的密度函数为
KaTeX parse error: No such environment: align* at position 8: \begin{̲a̲l̲i̲g̲n̲*̲}̲ t(x;\alpha,\nu…
便得到了 Z ∼ S T ( 0 , 1 , α , ν ) Z \sim \mathrm{ST}(0,1,\alpha,\nu) Z∼ST(0,1,α,ν),如果 α = 0 \alpha=0 α=0,那么该密度函数便会变回常规的学生 t t t分布;如果 ν → ∞ \nu \to \infty ν→∞,则变回 S N ( 0 , 1 , α ) \mathrm{SN}(0,1,\alpha) SN(0,1,α)密度函数。
为了更广泛的使用,我们需要让该分布再包含位置参数和尺度参数来进一步推广偏 t t t分布。我们令 Y = ξ + ω Z Y=\xi+\omega Z Y=ξ+ωZ,那么原来关于 x x x的概率密度函数 t ( x ; α , ν ) t(x;\alpha,\nu) t(x;α,ν),变为了 ω − 1 t ( z ; α , ν ) \omega^{-1}t(z;\alpha,\nu) ω−1t(z;α,ν),其中 z = ω − 1 ( x − ξ ) z=\omega^{-1}(x-\xi) z=ω−1(x−ξ),这样就得到含有均值、方差、偏度、自由度四个参数的偏 t t t分布 Y ∼ S T ( ξ , ω 2 , α , ν ) Y \sim \mathrm{ST(\xi,\omega^2,\alpha,\nu)} Y∼ST(ξ,ω2,α,ν),即
f S T ( y ) = 2 ω t ( η ; ν ) T ( α η ν + 1 ν + η 2 ; ν + 1 ) , η = y − ξ ω f_{ST}(y)=\frac{2}{\omega}t(\eta;\nu)T(\alpha \eta \sqrt{\frac{\nu+1}{\nu+\eta^2}};\nu+1), \qquad \eta=\frac{y-\xi}{\omega} fST(y)=ω2t(η;ν)T(αην+η2ν+1;ν+1),η=ωy−ξ
(先整理了定义,后续再逐步更新相关性质,未完待续…)
资源获取
- 关注公众号,回复“偏t分布”,获得电子书。