欢迎关注我的CSDN:https://blog.csdn.net/caroline_wendy
本文地址:https://blog.csdn.net/caroline_wendy/article/details/128866056
发表于NLP会议:NeurlPS,EMNLP
- EMNLP: Empirical Methods in Natural Language Processing,自然语言处理中的经验方法
- NeurlPS: Neural Information Processing Systems,神经信息处理系统

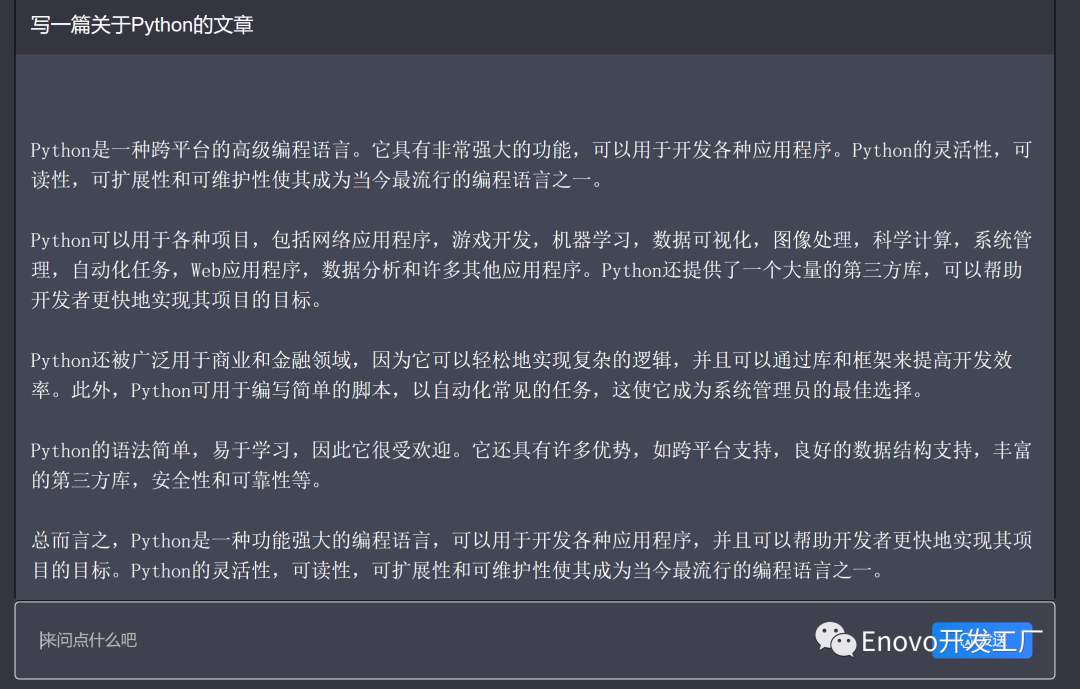
ChatGPT: Optimizing Language Models for Dialogue,优化对话的语言模型
- ChatGPT:https://openai.com/blog/chatgpt/
- GPT:Generative Pre-trained Transformer,生成式预训练Transformer
We’ve trained a model called ChatGPT which interacts in a conversational way. The dialogue format makes it possible for ChatGPT to answer followup questions, admit its mistakes, challenge incorrect premises, and reject inappropriate requests. ChatGPT is a sibling model to InstructGPT, which is trained to follow an instruction in a prompt and provide a detailed response.
- 我们已经训练了一个名为 ChatGPT 的模型,以对话方式进行交互。对话格式,使 ChatGPT 可以回答后续问题、承认错误、挑战不正确的前提,和拒绝不适当的请求等。 ChatGPT 是 InstructGPT 的兄弟模型,经过训练,可以按照提示中的说明(Instruction),进行操作并提供详细的响应。
发表时间:2022.3.4
InstructGPT: Training language models to follow instructions with human feedback
- 训练语义模型以服从带有人类反馈的指示
语言模型的有效性、安全性。
A diagram illustrating the three steps of our method: (1) supervised fine-tuning (SFT), (2) reward model (RM) training, and (3) reinforcement learning via proximal policy optimization (PPO) on this reward model. Blue arrows indicate that this data is used to train one of our models. In Step 2, boxes A-D are samples from our models that get ranked by labelers. See Section 3 for more details on our method.
- 说明我们方法的三个步骤的图表:
- (1) 监督微调(Supervised Fine-Tuning,SFT)。
- (2) 奖励模型(Reward Model,RM)训练。
- (3) 在奖励模型上,通过近端策略优化 (Proximal Policy Optimization,PPO) 进行强化学习。
- 蓝色箭头,表示此数据,用于训练我们的模型之一。在第 2 步中,方框 A-D 是来自我们的模型的样本,这些样本由标注者进行排序。有关我们方法的更多详细信息,请参阅第 3 节。
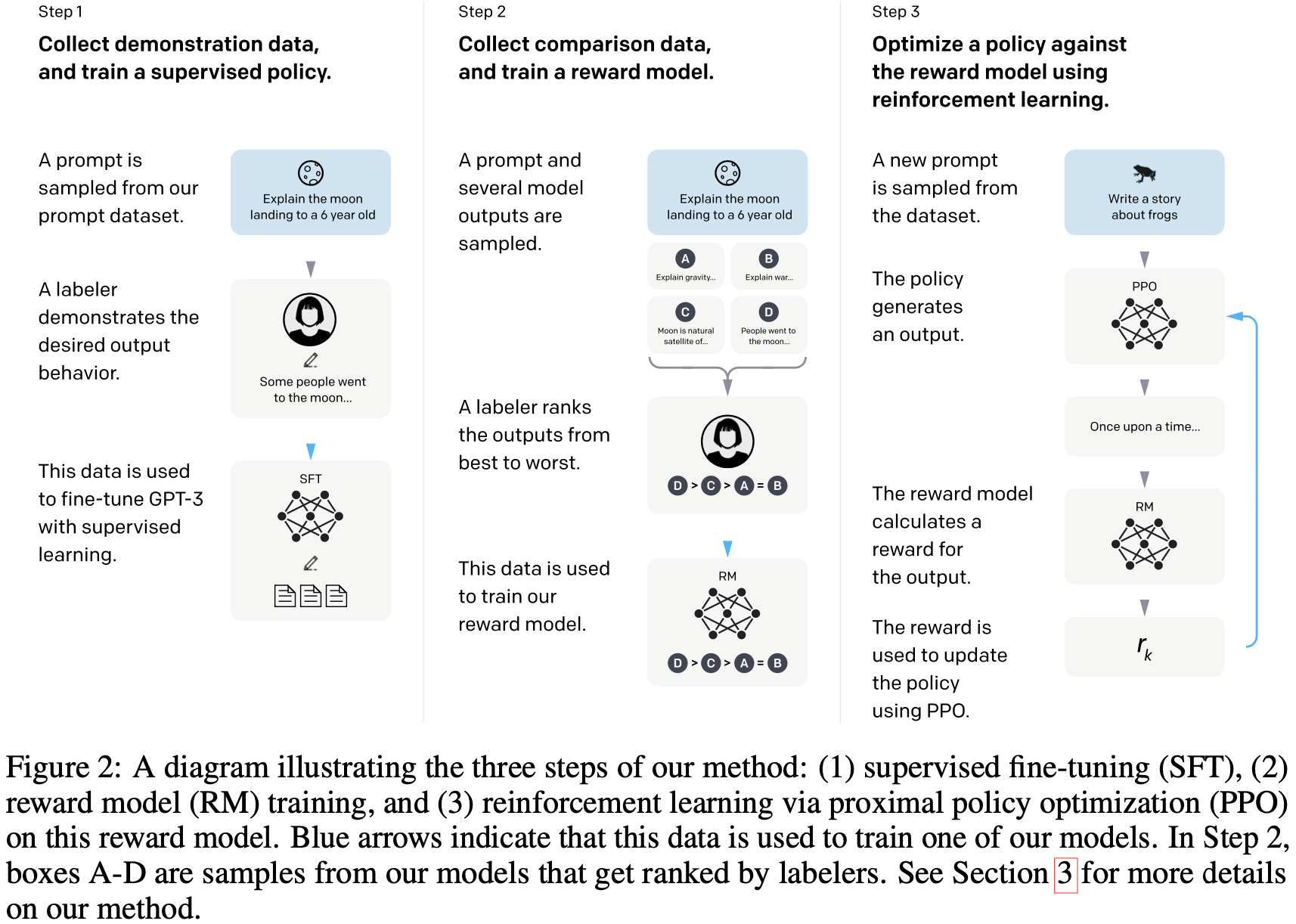
Step1: Collect demonstration data, and train a supervised policy. 收集示范数据,训练监督政策。
-
A prompt is sampled from out prompt dataset. -> Explain the moon landing to a 6 years old.
- 一个提示是从提示数据集中采样的。 -> 向 6 岁的孩子解释登月
-
A labeler demonstrates the desired output behavior. -> Some people went to the moon…
- 打标人员证明所需的输出行为。-> 有些人去了月球… (人工)
-
This data is used to fine-tune GPT-3 with supervised learning. -> SFT-Text
- 这些数据用于使用监督学习对GPT-3进行微调。 -> SFT,Supervised Fine-Tuning,监督微调
- 将问题和答案的文本,放到一起微调,标注答案很贵。
Step2: Collect comparison data, and train a reward model. 收集对比数据,训练奖励模型。
-
A prompt and several model outputs are sampled. -> Explain the moon landing to a 6 years old.
-
Explain gravity…,解释重力
-
Explain war…,解释战争
-
Moon is natural satellite of…,月球是天然卫星
-
People went to the moon…,人类去月球
-
一个提示是从提示数据集中采样的。 -> 向 6 岁的孩子解释登月
-
例如,使用集束搜索(beam search),采样答案。
-
-
A labeler ranks the outputs from best to worst. -> D > C > A = B
- 打标人员将输出从最好到最差进行排序。
- 数据标注变得简单,同样的标注成本下,得到更多的数据。
-
This data is used to train our reward model. -> RM-Rank
- 这些数据用于训练我们的奖励模型。
- 问题和答案,一起输入模型,输出打分,进行排序。同时,使得生成的答案分数更高。
Step3: Optimize a policy against the reward model using reinforcement learning. 使用强化学习,针对奖励模型优化策略。
- A new prompt is sampled from the dataset. -> Write a story about frogs.
- 从数据集中采样了一个新提示。 -> 写一个关于青蛙的故事。
- The policy generates an output. -> PPO - Once upon a time…
- 该策略生成输出。 -> 近端策略优化 (Proximal Policy Optimization,PPO) - 从前…
- The reward model calculates a reward for the output. 奖励模型为输出计算奖励。
- RM,奖励模型
- The reward is used to update the policy using PPO。 -> r k r_{k} rk
- 奖励用于使用 PPO 更新策略。
技术要点:
- 如何标注文本数据?
- 如何标注排序数据?
- RM模型如何训练?
- RM模型和PPO模型,如何进行强化学习?
模型具有泛化性,和先验知识,Few-shot,工具,可用性,正常的地方。
Prompt Dataset:
- 标注人员,写了很多问题。Plain、Few-shot、User-based。
- 每个用户采集200个问题,用户ID,避免同时出现在训练集和测试集,过滤人名。
- 内测版的模型,试用版本,发布子产品的思路,使用数据。
三个数据集:SFT Dataset (13k)、RM Dataset (33k)、PPO Dataset (31k)。
标注标准:helpfulness、truthfulness、harmlessness
- Supervised fine-tuning (SFT),监督微调,训练16个epoch。
- Reward modeling (RM),输出为1的线性层,1个标量奖励,模型由175B -> 6B。
- Pairwise Ranking loss,log(sigmoid(y1-y2)),交叉熵,K=9,选择36对。
- 9次前向,计算36次,4个答案。选择最好,softmax,容易overfitter
- Reinforcement learning (RL),PPO,Proximal Policy Optimization,近端策略优化。
- 强化学习里面,模型叫做Policy
- π S F T \pi^{SFT} πSFT训练好的模型, π ϕ R L \pi^{RL}_{\phi} πϕRL需要学习的模型,最大化目标函数,更新之后,采样的数据是不一样的,标的排序,而不是标的Y。
- 第1项:在线学习,人不停反馈,学一个函数替代人。
- 第2项:结果和之前的,不要跑太远,KL散度,softmax概率的相似度。PPO的主要思想。
- 第3项:原始数据集也不要放弃,原始的GPT3函数。
Reward modeling的Pairwise Ranking loss:

Proximal Policy Optimization:

参考文章:
- NLP:《ChatGPT: Optimizing Language Models for Dialogue一种优化的对话语言模型》翻译与解读
- AIGC:ChatGPT(一个里程碑式的对话聊天机器人)的简介(意义/功能/核心技术等)、使用方法(七类任务)、案例应用(提问基础性/事实性/逻辑性/创造性/开放性的问题以及编程相关)之详细攻略