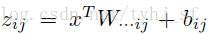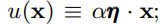文章目录
- 0️⃣前言
- 1️⃣Sigmoid
- 2️⃣tanh
- 3️⃣Relu
- 4️⃣Leaky Relu
- 5️⃣Softmax
- 6️⃣总结
0️⃣前言
用了这么久的激活函数,抽空总结一下吧,不然总是忘记,这里介绍常用到的sigmoid,tanh,relu,leaky relu,softmax
tips:部分图片来自计算机视觉研究院公众号
1️⃣Sigmoid

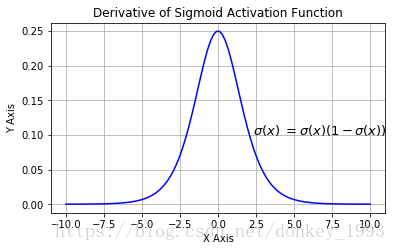
Sigmoid 函数的图像看起来像一个 S 形曲线。
函数表达式如下:

在什么情况下适合使用 Sigmoid 激活函数呢?
- Sigmoid 函数的输出范围是 0 到 1。由于输出值限定在 0 到 1,因此它对每个神经元的输出进行了归一化;
- 用于将预测概率作为输出的模型。由于概率的取值范围是 0 到 1,因此 Sigmoid 函数非常合适;
- 梯度平滑,避免「跳跃」的输出值;
- 函数是可微的 这意味着可以找到任意两个点的 sigmoid 曲线的斜率;
- 明确的预测,即非常接近 1 或 0。
Sigmoid 激活函数有哪些缺点?
- 倾向于梯度消失;
- 函数输出不是以 0 为中心的,这会降低权重更新的效率;
- Sigmoid 函数执行指数运算,计算机运行得较慢。
2️⃣tanh

tanh 激活函数的图像也是 S 形,表达式如下:

tanh 是一个双曲正切函数。tanh 函数和 sigmoid 函数的曲线相对相似。但是它比 sigmoid 函数更有一些优势。

优点:
- tanh 的输出间隔为 1,并且整个函数以 0 为中心,比 sigmoid 函数更好;
- 具有Sigmoid优点
缺点:
- 当输入较大或较小时,与Sigmoid函数一样,也存在消失梯度问题。
注意:在一般的二元分类问题中,tanh 函数用于隐藏层,而 sigmoid 函数用于输出层,但这并不是固定的,需要根据特定问题进行调整。
3️⃣Relu

ReLU 激活函数图像如上图所示,函数表达式如下:

ReLU 函数是深度学习中较为流行的一种激活函数,相比于 sigmoid 函数和 tanh 函数,它具有如下优点:
- 当输入为正时,不存在梯度饱和问题。
- 计算速度快得多。ReLU 函数中只存在线性关系,因此它的计算速度比 sigmoid 和 tanh 更快。
当然,它也有缺点:
- Dead ReLU 问题。当输入为负时,ReLU 完全失效,在正向传播过程中,这不是问题。有些区域很敏感,有些则不敏感。但是在反向传播过程中,如果输入负数,则梯度将完全为零,sigmoid 函数和 tanh 函数也具有相同的问题(输入过大或者过小会有问题);
- 我们发现 ReLU 函数的输出为 0 或正数,这意味着 ReLU 函数不是以 0 为中心的函数。
4️⃣Leaky Relu
它是一种专门设计用于解决 Dead ReLU 问题的激活函数:

Leaky Relu公式如下:(不知道空格怎么用,有点挤😢)

Leaky ReLU 通过把 x 的非常小的线性分量给予负输入(0.01x)来调整负值的零梯度(zero gradients)问题;
优点:
- 解决了 Dead ReLU 问题
- 具有Relu的优点
缺点:
- 结果不一致,无法为正负输入值提供一致的关系预测(不同区间函数不同)。
注意:从理论上讲,Leaky ReLU 具有 ReLU 的所有优点,而且 Dead ReLU 不会有任何问题,但在实际操作中,尚未完全证明 Leaky ReLU 总是比 ReLU 更好。
5️⃣Softmax

Softmax公式如下:

Softmax 是用于多类分类问题的激活函数,在多类分类问题中,超过两个类标签则需要类成员关系。对于长度为 K 的任意实向量,Softmax 可以将其压缩为长度为 K,值在(0,1)范围内,并且向量中元素的总和为 1 的实向量。

Softmax 与正常的 max 函数不同:max 函数仅输出最大值,但 Softmax 确保较小的值具有较小的概率,并且不会直接丢弃。我们可以认为它是 argmax 函数的概率版本或「soft」版本。
Softmax 函数的分母结合了原始输出值的所有因子,这意味着 Softmax 函数获得的各种概率彼此相关。
Softmax 激活函数的主要缺点是:
- 在零点不可微;
- 负输入的梯度为零,这意味着对于该区域的激活,权重不会在反向传播期间更新,因此会产生永不激活的死亡神经元。
6️⃣总结
Sigmoid、tanh:二分类任务输出层;模型隐藏层
Relu、Leaky Relu:回归任务;卷积神经网络隐藏层
Softmax:多分类任务输出层