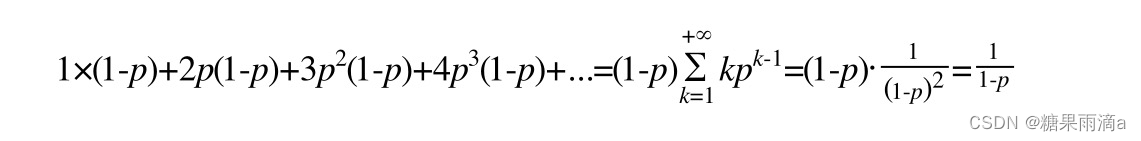一 前言
跳表(skiplist、跳跃表) 是一个很优秀的数据结构,比如用于 Redis、levelDB等出名的开源项目上。跳表在原有的有序链表上面增加了多级索引,通过索引来实现快速查找。
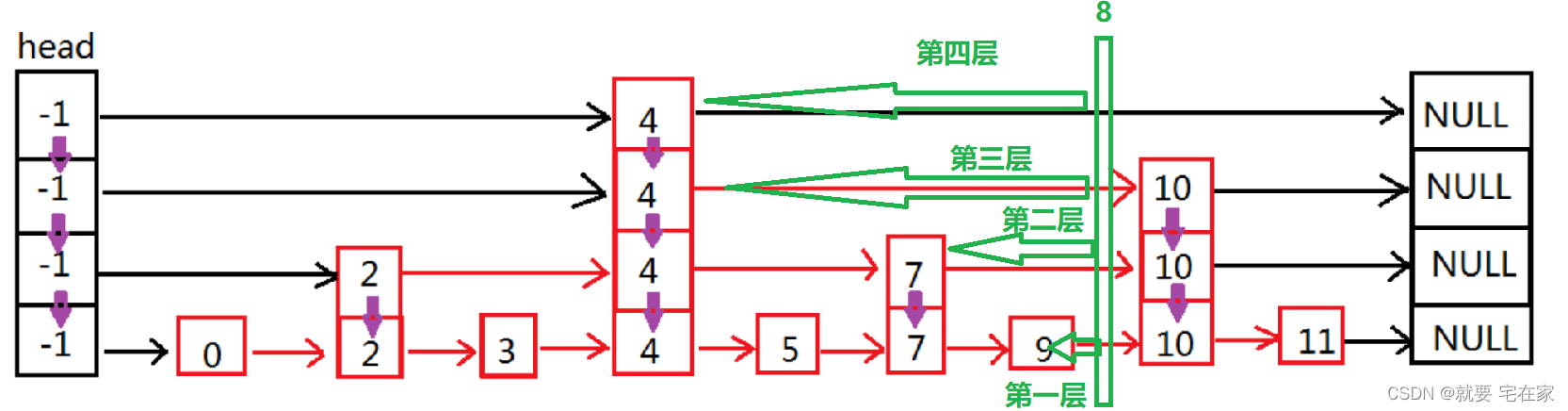
它的结构特点在名称能很好的体现出来,就像兔子一样,蹦蹦跳跳。可以结合下面的图有个初步的印象。

是不是看起来很形象了,接下来看看 Redis 是怎么实现跳表。
二 源码解读
本文讲解的版本为 Redis 6.0 ,可以在 server.h 头文件中找到对 skiplist 结构的定义。在 Redis 中,目前使用到跳表的只有 有序集合(zset)。
定义结构体处有段注释,也指明了跳表在 Redis 中的使用范围了。
ZSETs use a specialized version of Skiplists
// 有序集合的结构体
typedef struct zset {dict *dict; // 哈希表是一种实现方式。zskiplist *zsl; // 本文主题 跳表 实现方式。
} zset;// 跳表结构体
typedef struct zskiplist {struct zskiplistNode *header, *tail; // zskiplistNode 跳表节点, *header, *tail 头尾指针 unsigned long length; // 节点的数量int level; // 最大层数
} zskiplist;// 跳表节点结构体
typedef struct zskiplistNode {sds ele; // 成员对象double score; // 分值 作为索引struct zskiplistNode *backward; // 后退指针// 节点层结构 数组struct zskiplistLevel {struct zskiplistNode *forward; // 前进指针unsigned long span; // 该层向前跨越的节点数量} level[];
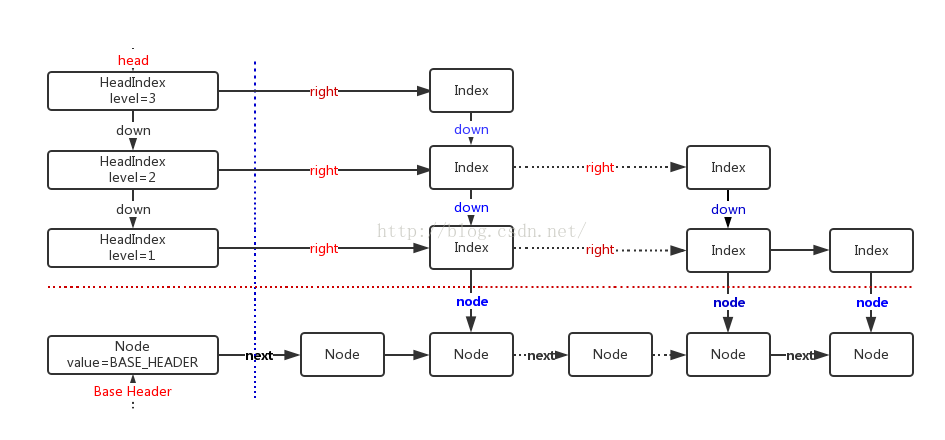
} zskiplistNode;看完上面的注视想必大家脑海中也构建出一张图了,它应该是长的和下图差不。

比如现在需要查找元素 56。
若是普通的链表就需要遍历整个链表,直到找到为止。如上图就需要查找 6 次。
但在跳表中,首先判断节点 56 是大于 34,则去下一层。 节点 56 < 节点 78,然后遍历 节点 34~ 节点 78中间。这时候只有一个节点 56。所以需要查找 3 次就可以找到了。
三 操作接口
操作结构的实现在 t_zset.c 文件中(不像 ziplist、quicklist 等是同名的一组文件)。
3.1 创建跳表
zskiplist *zslCreate(void) {int j;zskiplist *zsl; zsl = zmalloc(sizeof(*zsl)); // 申请内存zsl->level = 1; // 默认层级zsl->length = 0; // 默认长度// 头指针创建, ZSKIPLIST_MAXLEVEL 最大层级为 32,可容纳 2^64 个节点。zsl->header = zslCreateNode(ZSKIPLIST_MAXLEVEL,0,NULL);// 跳表结构的头节点需有足够的指针域,以满足可能构造最大级数的需要,而尾节点不需要指针域。for (j = 0; j < ZSKIPLIST_MAXLEVEL; j++) {zsl->header->level[j].forward = NULL;zsl->header->level[j].span = 0;}// 上面遍历 32 次,生成下面这段结构。// struct zskiplistLevel {// struct zskiplistNode *forward; // 前进指针// unsigned long span; // 该层向前跨越的节点数量// } level[];zsl->header->backward = NULL;zsl->tail = NULL;return zsl;}
3.2 节点插入
zskiplistNode *zslInsert(zskiplist *zsl, double score, sds ele) {zskiplistNode *update[ZSKIPLIST_MAXLEVEL], *x;unsigned int rank[ZSKIPLIST_MAXLEVEL];int i, level;serverAssert(!isnan(score));x = zsl->header;for (i = zsl->level-1; i >= 0; i--) {// 遍历找到插入的位置rank[i] = i == (zsl->level-1) ? 0 : rank[i+1];while (x->level[i].forward &&(x->level[i].forward->score < score ||(x->level[i].forward->score == score &&sdscmp(x->level[i].forward->ele,ele) < 0))){rank[i] += x->level[i].span;x = x->level[i].forward;}update[i] = x;}// 调用 zslInsert 的地方需要在 hash 中判断当前插入的元素是否已经存在集合中。// 元素不能重复,但是元素的分数是可以重复的。// 生成随机值 代表需要插入的层级。 下面会讲解具体实现。level = zslRandomLevel();if (level > zsl->level) {for (i = zsl->level; i < level; i++) {rank[i] = 0;update[i] = zsl->header;update[i]->level[i].span = zsl->length;}zsl->level = level;}// 创建节点x = zslCreateNode(level,score,ele);for (i = 0; i < level; i++) {x->level[i].forward = update[i]->level[i].forward;update[i]->level[i].forward = x;// 插入新节点后需要更新前后节点对应的span值。 span 是到下一个节点的跨度 x->level[i].span = update[i]->level[i].span - (rank[0] - rank[i]);update[i]->level[i].span = (rank[0] - rank[i]) + 1;}// 更新 其他level增加 span 值for (i = level; i < zsl->level; i++) {update[i]->level[i].span++;}// 更新 后退指针。x->backward = (update[0] == zsl->header) ? NULL : update[0];if (x->level[0].forward)x->level[0].forward->backward = x;elsezsl->tail = x;zsl->length++;return x;
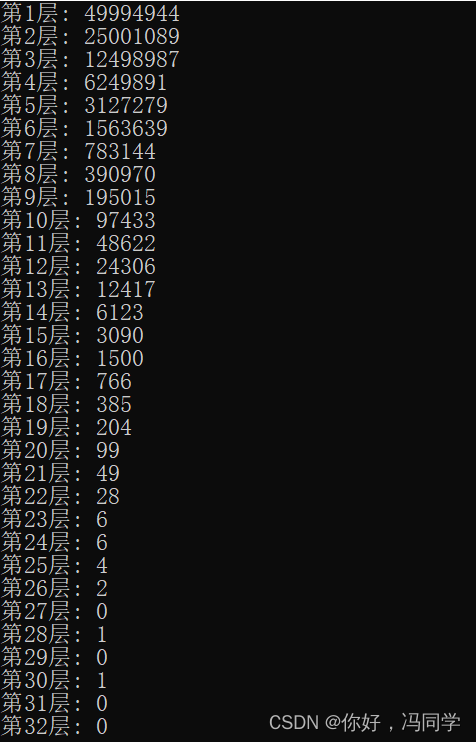
}// 这里需要单独说下这个随机值生成的规则。int zslRandomLevel(void) {int level = 1;// ZSKIPLIST_P = 0.25 ,虽然跳表的时间复杂度和二分查找一样,但是这里并不是 50% 的概率来控制一个节点是否放到下一层,而是 25%。 所以同一层节点下一层间的元素个数并不是一样的哦。// 还有的说法是这个值为 0.27更合适。 就是自然常数 e (2.7)。// random() 生成的随机数和 0xFFFF(16个1) 做 与运算。// 其实就是获取random()(32位)的前16位(或者说低位)。while ((random()&0xFFFF) < (ZSKIPLIST_P * 0xFFFF))level += 1;return (level<ZSKIPLIST_MAXLEVEL) ? level : ZSKIPLIST_MAXLEVEL;
}3.3 节点删除
int zslDelete(zskiplist *zsl, double score, sds ele, zskiplistNode **node) {zskiplistNode *update[ZSKIPLIST_MAXLEVEL], *x;int i;x = zsl->header;for (i = zsl->level-1; i >= 0; i--) {while (x->level[i].forward &&(x->level[i].forward->score < score ||(x->level[i].forward->score == score &&sdscmp(x->level[i].forward->ele,ele) < 0))){x = x->level[i].forward;}update[i] = x;}// 找到分数和值都一样的元素。x = x->level[0].forward;if (x && score == x->score && sdscmp(x->ele,ele) == 0) {zslDeleteNode(zsl, x, update);if (!node)zslFreeNode(x);else*node = x;return 1;}return 0; // 没找到
}// 删除的具体逻辑
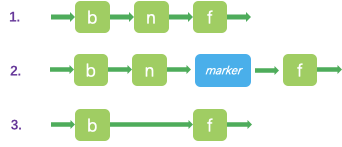
void zslDeleteNode(zskiplist *zsl, zskiplistNode *x, zskiplistNode **update) {int i;// 更新 每一层forward、span。for (i = 0; i < zsl->level; i++) {if (update[i]->level[i].forward == x) {update[i]->level[i].span += x->level[i].span - 1;update[i]->level[i].forward = x->level[i].forward;} else {update[i]->level[i].span -= 1;}}if (x->level[0].forward) {x->level[0].forward->backward = x->backward;} else {zsl->tail = x->backward;}// 若删除的层级没有元素 层级减 1。while(zsl->level > 1 && zsl->header->level[zsl->level-1].forward == NULL)zsl->level--;// 元素长度减 1。zsl->length--;
}源码解读就先到这里,更多的可以直接查看源码。
四 总结
跳表是一个随机化的数据结构,实质就是一种可以进行二分查找的有序链表。跳表在原有的有序链表上面增加了多级索引,通过索引来实现快速查找。跳表不仅能提高搜索性能,同时也可以提高插入和删除操作的性能。
跳表中的搜索、插入、删除操作的时间均为 O(logn),最坏情况((level = 1)时间复杂性为 O(n) 。相比之下,在一个有序数组或链表中进行插入/删除操作的时间为 O(n),最坏情况下为 O(n)。
它采用随机技术决定链表中哪些节点应增加向前指针以及在该节点中应增加多少个指针。跳表结构的头节点需有足够的指针域,以满足可能构造最大级数的需要,而尾节点不需要指针域。
不好之处就是多层结构会占用额外的空间,是典型的空间换时间的操作。
五 其他文章
- SDS-简单动态字符串
- Redis - String 类型数据结构(SDS、Int)图文详解
- ziplist-压缩列表
- zipmap-压缩字典
- quicklist-快速列表
- skiplist-跳表
- dict-字典
- intset-整数数组
- redis 通信协议讲解
- listpack-紧凑列表
- Redis7.0 新特性(超详细)
- Redis 请慎用String类型
- Redis 为什么使用单线程?
- Redis AOF日志备份原理
- Redis - ACID分析