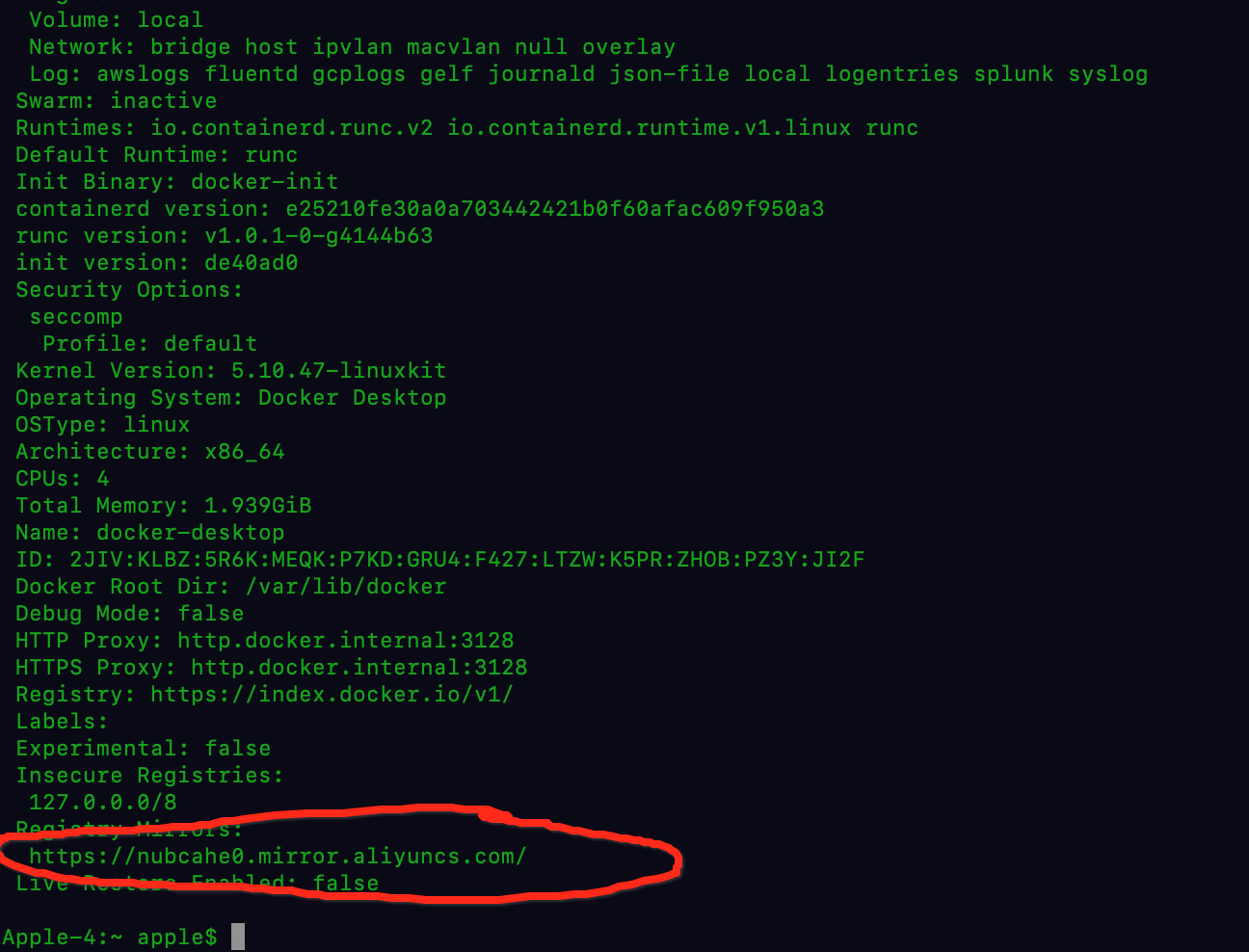
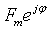skiplist介绍
跳表(skip List)是一种随机化的数据结构,基于并联的链表,实现简单,插入、删除、查找的复杂度均为O(logN)。跳表的具体定义,请参考参考维基百科 点我,中文版。跳表是由William Pugh发明的,这位确实是个大牛,搞出一些很不错的东西。简单说来跳表也是
链表的一种,只不过它在链表的基础上增加了跳跃功能,正是这个跳跃的功能,使得在查找元素时,跳表能够提供O(log n)的时间复杂
度。红黑树等这样的平衡数据结构查找的时间复杂度也是O(log n),并且相对于红黑树这样的平衡二叉树skiplist的优点是更好的支持并
发操作,但是要实现像红黑树这样的数据结构并非易事,但是只要你熟悉链表的基本操作,再加之对跳表原理的理解,实现一个跳表数据
结构就是一个很自然的事情了。
此外,跳表在当前热门的开源项目中也有很多应用,比如LevelDB的核心数据结构memtable是用跳表实现的,redis的sorted set数据
结构也是有跳表实现的。
skiplist主要思想
先从链表开始,如果是一个简单的链表(不一定有序),那么我们在链表中查找一个元素X的话,需要将遍历整个链表直到找到元素X为止。
现在我们考虑一个有序的链表:

从该有序表中搜索元素 {13, 39} ,需要比较的次数分别为 {3, 5},总共比较的次数为 3 + 5 = 8 次。我们想下有没有更优的算法? 我们想到了对于
有序数组查找问题我们可以使用二分查找算法,但对于有序链表却不能使用二分查找。这个时候我们在想下平衡树,比如BST,他们都是通过把一些
节点取出来作为其节点下某种意义的索引,比如父节点一般大于左子节点而小于右子节点。因此这个时候我们想到类似二叉搜索树的做法把一些
节点提取出来,作为索引。得到如下结构:
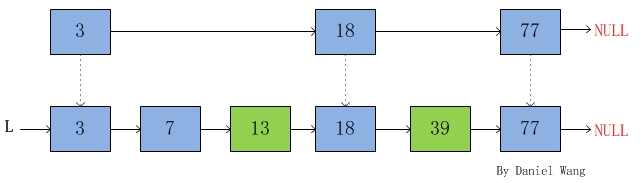
在这个结构里我们把{3, 18, 77}提取出来作为一级索引,这样搜索的时候就可以减少比较次数了,比如在搜索39时仅比较了3次(通过比较3,18,39)。
当然我们还可以再从一级索引提取一些元素出来,作为二级索引,这样更能加快元素搜索。
这基本上就是跳表的核心思想,其实是一种通过“空间来换取时间”的一个算法,通过在每个节点中增加了向前的指针(即层),从而提升查找的效率。
跳跃列表是按层建造的。底层是一个普通的有序链表。每个更高层都充当下面列表的「快速跑道」,这里在层 i 中的元素按某个固定的概率 p (通常
为0.5或0.25)出现在层 i+1 中。平均起来,每个元素都在 1/(1-p) 个列表中出现, 而最高层的元素(通常是在跳跃列表前端的一个特殊的头元素)
在 O(log1/p n) 个列表中出现。
SkipList基本数据结构及其实现
一个跳表,应该具有以下特征:
1,一个跳表应该有几个层(level)组成;
2,跳表的第一层包含所有的元素;
3,每一层都是一个有序的链表;
4,如果元素x出现在第i层,则所有比i小的层都包含x;
5,每个节点包含key及其对应的value和一个指向同一层链表的下个节点的指针数组
如图所示。
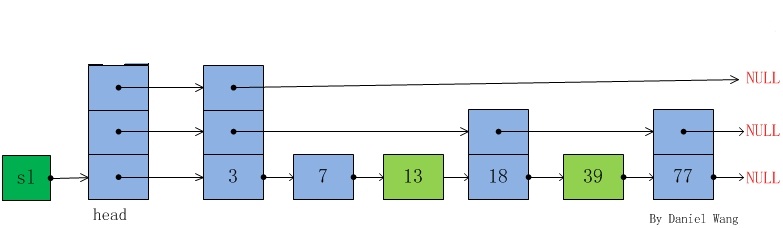
跳表基本数据结构
定义跳表数据类型:
//跳表结构
typedef struct skip_list
{int level;// 层数Node *head;//指向头结点
} skip_list;
其中level是当前跳表最大层数,head是指向跳表的头节点如上图。
跳表的每个节点的数据结构:
typedef struct node
{keyType key;// key值valueType value;// value值struct node *next[1];// 后继指针数组,柔性数组 可实现结构体的变长
} Node;
对于这个结构体重点说说,struct node *next[1] 其实它是个柔性数组,主要用于使结构体包含可变长字段。我们可以通过如下方法得到包含可变
层数(n)的Node *类型的内存空间:
#define new_node(n)((Node*)malloc(sizeof(Node)+n*sizeof(Node*)))
通过上面我们可以根据层数n来申请指定大小的内存,从而节省了不必要的内存空间(比如固定大小的next数组就会浪费大量的内存空间)。
跳表节点的创建
// 创建节点
Node *create_node(int level, keyType key, valueType val)
{Node *p=new_node(level);if(!p)return NULL;p->key=key;p->value=val;return p;
}
跳表的创建
列表的初始化需要初始化头部,并使头部每层(根据事先定义的MAX_LEVEL)指向末尾(NULL)
//创建跳跃表
skip_list *create_sl()
{skip_list *sl=(skip_list*)malloc(sizeof(skip_list));//申请跳表结构内存if(NULL==sl)return NULL;sl->level=0;// 设置跳表的层level,初始的层为0层(数组从0开始)Node *h=create_node(MAX_L-1, 0, 0);//创建头结点if(h==NULL){free(sl);return NULL;}sl->head = h;int i;// 将header的next数组清空for(i=0; i<MAX_L; ++i){h->next[i] = NULL;}srand(time(0));return sl;
}
跳表插入操作
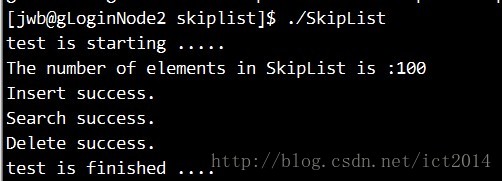
我们知道跳表是一种随机化数据结构,其随机化体现在插入元素的时候元素所占有的层数完全是随机的,层数是通过随机算法产生的:
//插入元素的时候元素所占有的层数完全是随机算法
int randomLevel()
{int level=1;while (rand()%2)level++;level=(MAX_L>level)? level:MAX_L;return level;
}
相当与做一次丢硬币的实验,如果遇到正面(rand产生奇数),继续丢,遇到反面,则停止,用实验中丢硬币的次数level作为元素占有的层数。
显然随机变量 level 满足参数为 p = 1/2 的几何分布,level 的期望值 E[level] = 1/p = 2. 就是说,各个元素的层数,期望值是 2 层。
由于跳表数据结构整体上是有序的,所以在插入时,需要首先查找到合适的位置,然后就是修改指针(和链表中操作类似),然后更新跳表的
level变量。 跳表的插入总结起来需要三步:
1:查找到待插入位置, 每层跟新update数组;
2:需要随机产生一个层数;
3:从高层至下插入,与普通链表的插入完全相同;
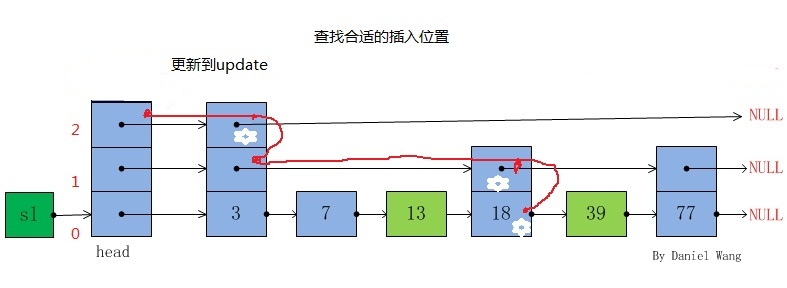
比如插入key为25的节点,如下图。
对于步骤1,我们需要对于每一层进行遍历并保存这一层中下降的节点(其后继节点为NULL或者后继节点的key大于等于要插入的key),如下图,
节点中有白色星花标识的节点保存到update数组。
对于步骤2我们上面已经说明了是通过一个随机算法产生一个随机的层数,但是当这个随机产生的层数level大于当前跳表的最大层数时,我们
此时需要更新当前跳表最大层数到level之间的update内容,这时应该更新其内容为跳表的头节点head,想想为什么这么做,呵呵。然后就是更
新跳表的最大层数。
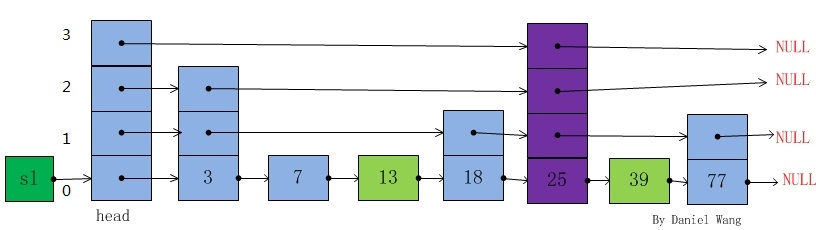
对于步骤3就和普通链表插入一样了,只不过现在是对每一层链表进行插入节点操作。最终的插入结果如图所示,因为新插入key为25的节点level随机
为4大于插入前的最大层数,所以此时跳表的层数为4。
实现代码如下:
bool insert(skip_list *sl, keyType key, valueType val)
{Node *update[MAX_L];Node *q=NULL,*p=sl->head;//q,p初始化int i=sl->level-1;/******************step1*******************///从最高层往下查找需要插入的位置,并更新update//即把降层节点指针保存到update数组for( ; i>=0; --i){while((q=p->next[i])&& q->key<key)p=q;update[i]=p;}if(q && q->key == key)//key已经存在的情况下{q->value = val;return true;}/******************step2*******************///产生一个随机层数levelint level = randomLevel();//如果新生成的层数比跳表的层数大if(level>sl->level){//在update数组中将新添加的层指向headerfor(i=sl->level; i<level; ++i){update[i]=sl->head;}sl->level=level;}//printf("%d\n", sizeof(Node)+level*sizeof(Node*));/******************step3*******************///新建一个待插入节点,一层一层插入q=create_node(level, key, val);if(!q)return false;//逐层更新节点的指针,和普通链表插入一样for(i=level-1; i>=0; --i){q->next[i]=update[i]->next[i];update[i]->next[i]=q;}return true;
}
跳表删除节点操作
删除节点操作和插入差不多,找到每层需要删除的位置,删除时和操作普通链表完全一样。不过需要注意的是,如果该节点的level是最大的,
则需要更新跳表的level。实现代码如下:
bool erase(skip_list *sl, keyType key)
{Node *update[MAX_L];Node *q=NULL, *p=sl->head;int i = sl->level-1;for(; i>=0; --i){while((q=p->next[i]) && q->key < key){p=q;}update[i]=p;}//判断是否为待删除的keyif(!q || (q&&q->key != key))return false;//逐层删除与普通链表删除一样for(i=sl->level-1; i>=0; --i){if(update[i]->next[i]==q)//删除节点{update[i]->next[i]=q->next[i];//如果删除的是最高层的节点,则level--if(sl->head->next[i]==NULL)sl->level--;}}free(q);q=NULL;return true;
}
跳表的查找操作
跳表的优点就是查找比普通链表快,其实查找操已经在插入、删除操作中有所体现,代码如下:
valueType *search(skip_list *sl, keyType key)
{Node *q,*p=sl->head;q=NULL;int i=sl->level-1;for(; i>=0; --i){while((q=p->next[i]) && q->key<key){p=q;}if(q && key==q->key)return &(q->value);}return NULL;
}
跳表的销毁
上面分别介绍了跳表的创建、节点插入、节点删除,其中涉及了内存的动态分配,在使用完跳表后别忘了释放所申请的内存,不然会内存泄露的。
不多说了,代码如下:
// 释放跳跃表
void sl_free(skip_list *sl)
{if(!sl)return;Node *q=sl->head;Node *next;while(q){next=q->next[0];free(q);q=next;}free(sl);
}skiplist复杂度分析
skiplist分析如下图(摘自 这里)


完整代码及其测试: https://github.com/ustcdane/skiplist/ , 接下来可以尝试着分析Redis 源代码中skiplist相关的数据结构了。
参考:
https://www.cs.auckland.ac.nz/software/AlgAnim/niemann/s_skl.htm
http://www.cnblogs.com/xuqiang/archive/2011/05/22/2053516.html