skiplist 原理介绍
skiplist 由William Pugh 在论文Skip Lists: A Probabilistic Alternative to Balanced Trees 中提出的一种数据结构,skiplist 是一种随机化存储的多层线性链表结构,插入,查找,删除的都是对数级别的时间复杂度。skiplist 和平衡树有相同的时间复杂度,但相比平衡树,skip实现起来更简单。
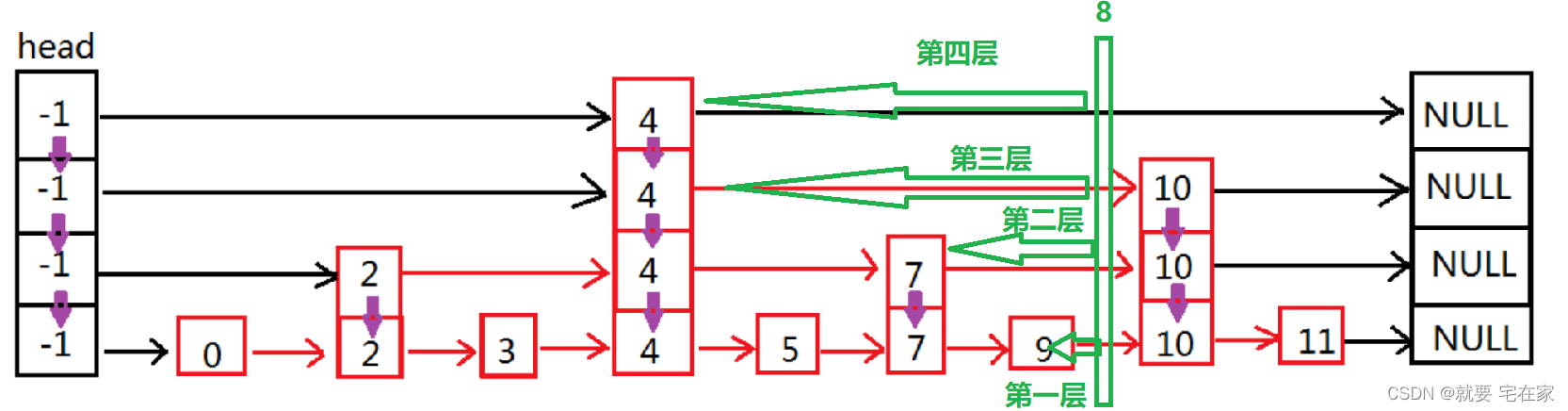
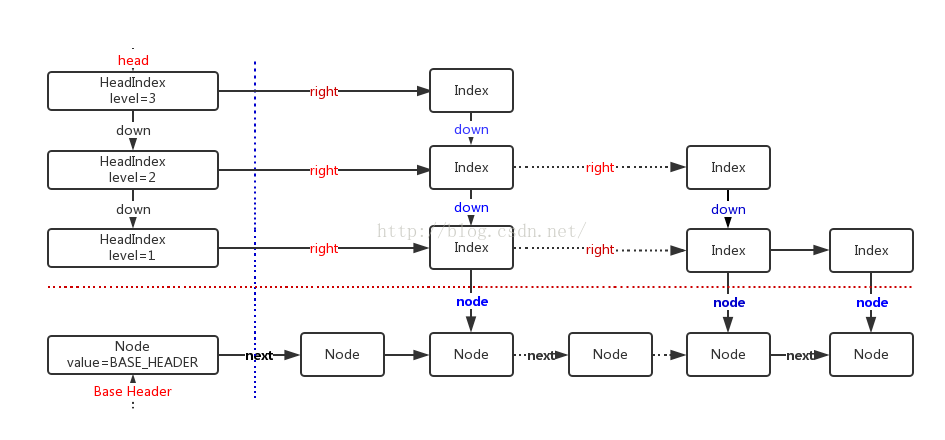
下图是wikipedia 上一个一个高度为4的skiplist

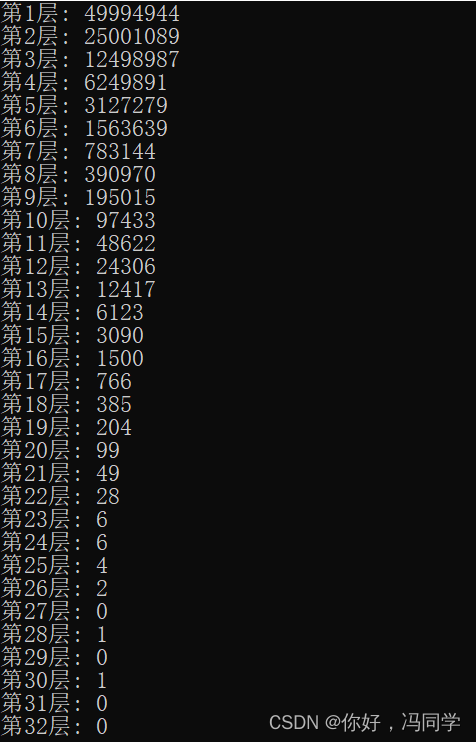
从垂直角度看,skiplist 的第0层以单链表的形式按照从小到大的顺序存储全部数据,越高层的链表的节点数越少,这样的特点实现了skiplist 在定位某个位置时,通过在高层较少的节点中查找就可以确定需要定位的位置处于哪个区间,从高层到低层不断缩小查找区间。以上图为例,比如我们需要在skiplist中查找2,查找过程如下,首先在最高层确定到2只可能处于1->NULL 这个区间,然后在第三层查找确定 2 只可能处于 1->4 这个区间,继续在第二层查找确定2 只可能处于1-3 这区间,最后在最底层1->3 这个区间查找可以确定2 是否存在于skiplist之中。
下图是wikipedia上提供的表示skiplist插入过程的一张gif,此图形象的说明了skiplist 定位以及插入节点的过程。

从水平角度来看,skiplist实现在链表开始的时候设置名为head 的哨兵节点,每一层链表的结束为止全部指向NULL。
leveldb 实现
leveldb 实现的skiplist位于db/skiplist.h。
skiplist Node 类型定义
// Implementation details follow
template<typename Key, class Comparator>
struct SkipList<Key,Comparator>::Node {explicit Node(const Key& k) : key(k) { }// Node 存储的内容Key const key;// Accessors/mutators for links. Wrapped in methods so we can// add the appropriate barriers as necessary.// 获取当前节点在指定level的下一个节点Node* Next(int n) {assert(n >= 0);// Use an 'acquire load' so that we observe a fully initialized// version of the returned Node.return reinterpret_cast<Node*>(next_[n].Acquire_Load());}// 将当前节点在指定level的下一个节点设置为xvoid SetNext(int n, Node* x) {assert(n >= 0);// Use a 'release