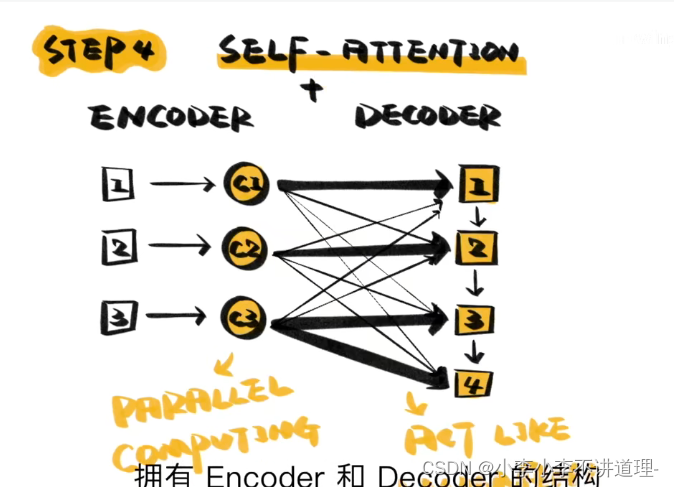
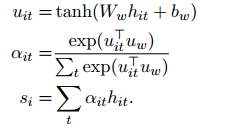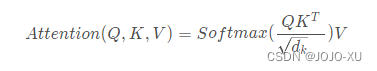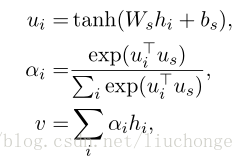Attention是模拟人脑的注意力机制。人在看到一些东西,往往只关注重要的信息,而忽略其他信息。自然语言处理中的attention是对文本分配注意力权重,Attention的本质就是从关注全部变为关注重点。
1 Attention的原理

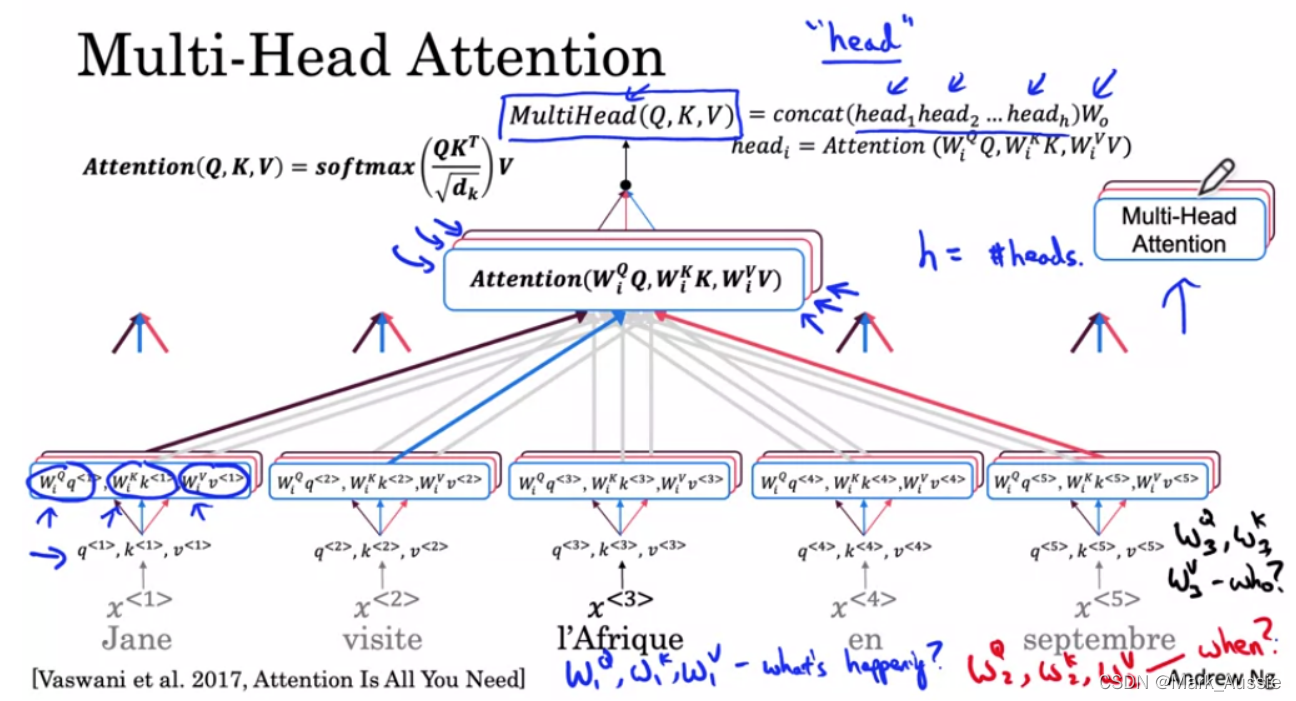
Attention的计算过程:
- query和key向量进行相似度计算,得到权重。
- 将得到的权值进行归一化,得到每个key的归一化权重。
- 根据权重,对value进行加权求和。
2 Attention的类型

如上图,按不同的方式,可将attention分为不同类型。

3 attention计算方式
attention通俗来讲是用两个向量(query,key)计算得到一个得分score。从数学角度看,就是两个向量得到一个数值。一般有以下计算方式:
(1)点乘: s ( q , k ) = q ⋅ k s(q,k)=q\cdot k s(q,k)=q⋅k
(2)余弦相似度: s ( q , k ) = q ⋅ k ∣ q ∣ ∣ k ∣ s(q,k)=\frac{q\cdot k}{|q||k|} s(q,k)=∣q∣∣k∣q⋅k
还有引入学习参数的方式
(3)矩阵相乘: s ( q , k ) = q T W k s(q,k)=q^TWk s(q,k)=qTWk
(4)小网络学习(多层感知机):输入两个向量,输出一个数值
4 attention的使用场景
4.1 长文本任务
如篇章级别的任务,这类型任务输入的信息过多,使用attention捕获关键信息。
4.2 涉及两端相关文本
可能需要对两端内容进行对齐,如机器翻译,翻译时当前词与原文的信息对齐。阅读理解,问题与原文信息的对齐。
4.3 任务只依赖某些特征
某些任务只依赖与部分强特征词。
引用自:
[1]Attention用于NLP的一些小结
[2]一文看懂attention