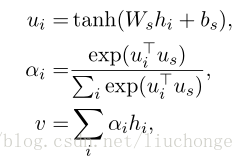1.背景知识
Seq2Seq模型:使用两个RNN,一个作为编码器,一个作为解码器。
编码器:将输入数据编码成一个特征向量。
解码器:将特征向量解码成预测结果。

缺点:只将编码器的最后一个节点的结果进行了输出,但是对于一个序列长度特别长的特征来说,这种方式无疑将会遗忘大量的前面时间片的特征。也就是句子太长,翻译精度会进行下降。

优点:解决输入输出结点不对等,RNN只能输出N对N,N对1
2.Attention机制
注意力机制:生成每个单词时,都会有意识的从原始句子提取生成该单词时最需要的信息,成功摆脱了输入序列的长度限制。

缺点:计算太慢,RNN需要逐个看过句子中的单词,才能给出输出

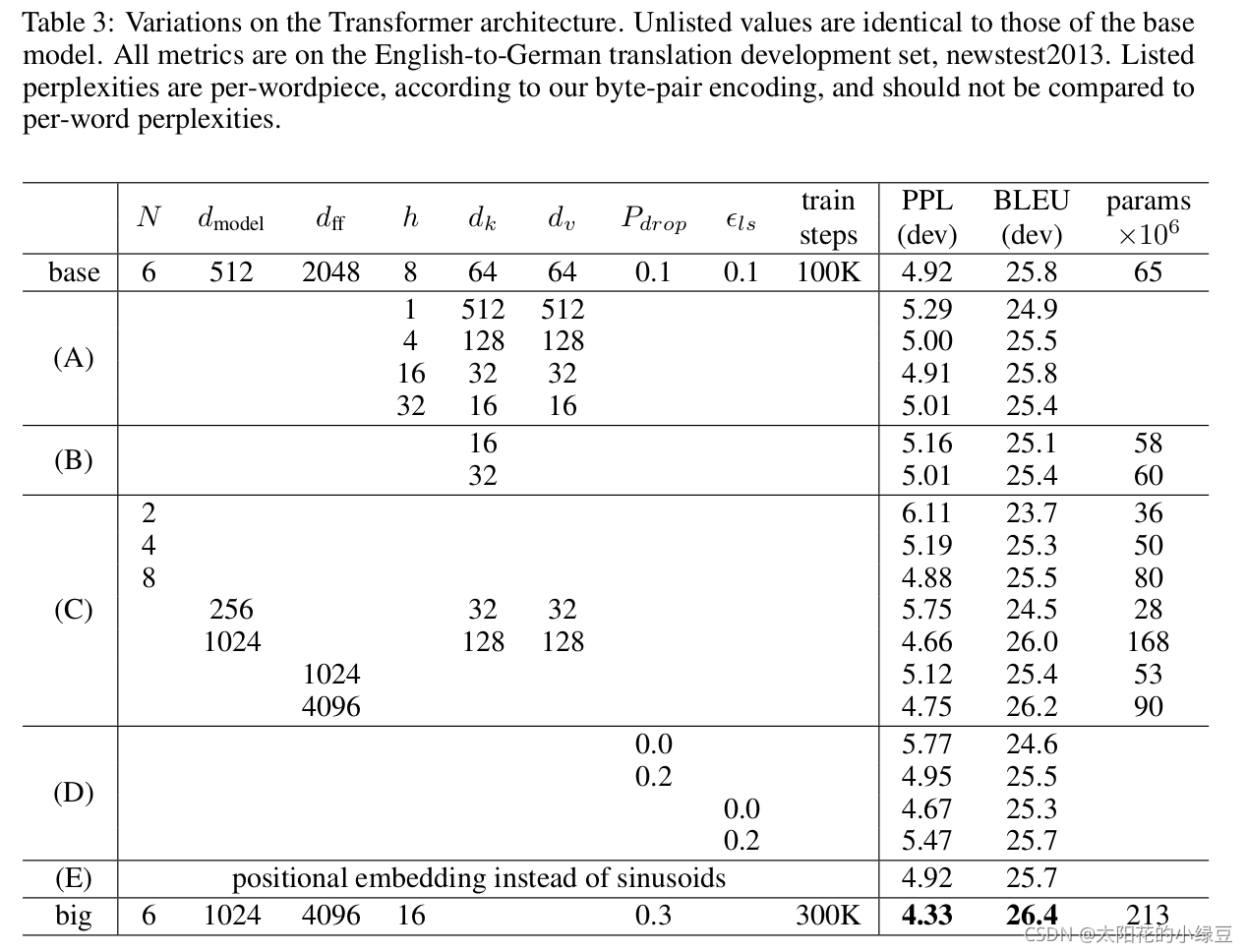
Attention是一个介于编码器和解码器之间的一个接口,用于将编码器的编码结果以一种更有效的方式传递给解码器。一个特别简单且有效的方式就是让解码器知道哪些特征重要,哪些特征不重要,即让解码器明白如何进行当前时间片的预测结果和输入编码的对齐,如图4所示。Attention模型学习了编码器和解码器的对齐方式,因此也被叫做对齐模型(Alignment Model)。
3.Self-attention
先提取每个单词的意义 再依据生成顺序选取所需要的信息
支持并行计算,效率更高
结构上:完全去掉了RNN
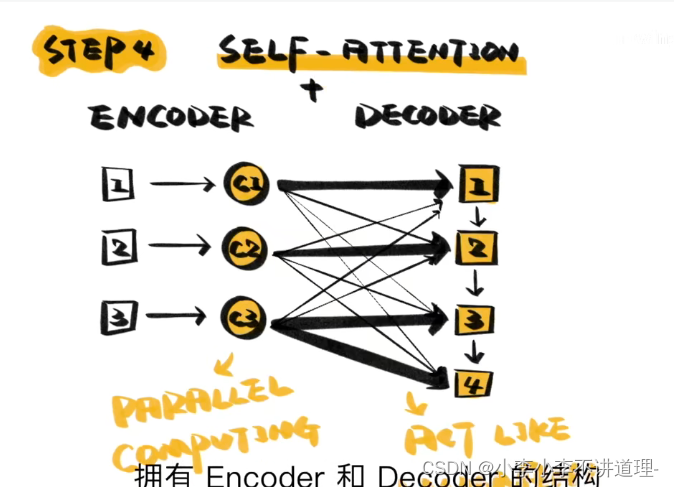
5.Attention应用
NLP中用于定位关键toke或者特征
6.Attention与Self Attention区别
以Encoder-Decoder框架为例,输入Source和输出Target内容是不一样的,比如对于英-中机器翻译来说,Source是英文句子,Target是对应的翻译出的中文句子,Attention发生在Target的元素Query和Source中的所有元素之间。
Self Attention,指的不是Target和Source之间的Attention机制,而是Source内部元素之间或者Target内部元素之间发生的Attention机制,也可以理解为Target=Source这种特殊情况下的Attention。
两者具体计算过程是一样的,只是计算对象发生了变化而已。