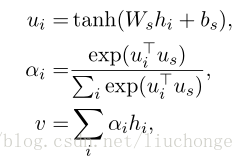文章目录
- Attention原理
- HAN原理
- 利用Attention模型进行文本分类
- 参考资料
Attention原理
转载一个Hierarchical Attention神经网络的实现
转载 图解Transformer
转载 Attention原理和源码解析
论文链接 Attention is All You Need
HAN原理
论文链接Hierarchical Attention Network for Document Classification
HAN模型就是分层次的利用注意力机制来构建文本向量表示的方法。
文本由句子构成,句子由词构成,HAN模型对应这个结构分层的来构建文本向量表达;
文本中不同句子对文本的主旨影响程度不同,一个句子中不同的词语对句子主旨的影响程度也不同,因此HAN在词语层面和句子层面分别添加了注意力机制;
分层的注意力机制还有一个好处,可以直观的看出用这个模型构建文本表示时各个句子和单词的重要程度,增强了可解释性;
模型结构:

论文里面使用双向GRU来构建句子表示和文本表示,以句子为例,得到循环神经网络中每个单元的输出后利用注意力机制整合得到句子向量表示(不使用attention时,一般会使用MAX或AVE),过程如下:
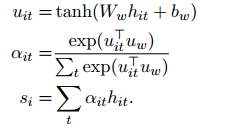
按照文中说法,先经过一层MLP得到隐层表示,然后与word level context vector " u w u_w uw"做点积,各词语得到的结果再经过softmax函数后的结果就是各自的重要程度,即 α \alpha αit,最后加权和得到句子表示 s i s_i si 。文本向量的构建与此一致,之后经过全连接层和softmax分类。
利用Attention模型进行文本分类
转载 mt_attention_birnn
参考资料
使用CNN,RNN,HAN进行文本分类的对比报告
HAN
一个Hierarchical Attention神经网络的实现