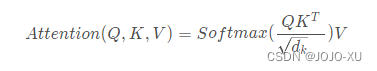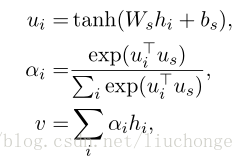1.Encoder-Decoder中的attention机制
上一篇文章最后,在Encoder-Decoder框架中,输入数据的全部信息被保存在了C。而这个C很容易受到输入句子长度的影响。当句子过长时,C就有可能存不下这些信息,导致模型后续的精度下降。Attention机制对于这个问题的解决方案是在decoder阶段,每个时间点输入的C都是不一样的。而这个C,会根据当前要输出的y,去选取最适合y的上下文信息。
整体的流程如下图所示
从图上可以看出,在Decoder结构中,每一个时间点的输入都是不同的。这就是attention机制起作用的地方。对于Encoder中包含的输入内容的信息,attention机制会根据当前的输出,对Encoder中获得的输入做一个权重分配。这一点和人类的注意力也很像。当人在翻译句子中某个词的时候,肯定也会有所针对的看原句中的对应部分,而不是把原句所有词都同等看待。
下面举一个具体的翻译的例子,
Encoder模型中的h1,h2,h3,h4可以看做是输入‘我爱中国’所代表的信息。如果不做处理的话,那么c就是一个包含h1到h4全部信息的一个状态。现在对于不同的隐状态h,配以不同的权重a。这样,在输出不同的词的时候,虽然h的值都一样,但h对应的a的值是不同的。这就会导致c是不一样的。在输出每一个y的时候,输入进来的c都是不同的。
这个过程与人的注意力非常相像。以图中的翻译为例,输出的一个词 I 与中文的我关系最密切,所以h1分配的权重最大,也就是将翻译的注意力集中在h1。这里的权重a,是通过训练得来的。对于![]() 而言,是通过decoder的上一个隐状态ci和encoder的隐状态hj学习得来的。
而言,是通过decoder的上一个隐状态ci和encoder的隐状态hj学习得来的。
具体到RNN模型的decoder模型来讲,在时刻i,如果要生成yi单词,我们可以得到在生成Yi之前的时刻,i-1时,隐层节点i-1时刻的输出值![]() ,而我们的目的是要计算生成Yi时输入句子中的每个词对Yi来说的注意力分配概率分布,那么可以用Target输出句子i-1时刻的隐层节点状态
,而我们的目的是要计算生成Yi时输入句子中的每个词对Yi来说的注意力分配概率分布,那么可以用Target输出句子i-1时刻的隐层节点状态![]() 去和输入句子Source中每个单词对应的RNN隐层节点状态hj进行对比,即通过函数
去和输入句子Source中每个单词对应的RNN隐层节点状态hj进行对比,即通过函数
![]()
来获得目标单词yi和每个输入单词对应的对齐可能性,这个F函数在不同论文里可能会采取不同的方法,然后函数F的输出经过Softmax进行归一化就得到了符合概率分布取值区间的注意力分配概率分布数值。
总结一下,对于encoder-decoder模型中的attention机制。
在decoder阶段,生成最后的输出时

其中,每个ci包含了对于最初输入句子中每个词的注意力分配。
![]()
这里f2表示encoder模型中的变换函数。在RNN的实例中,f2的结果就是RNN模型中的隐层状态值h。
g函数通常使用求和函数。
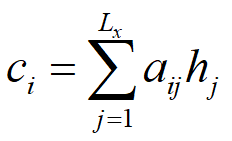
这里的L表示了句子的长度。
以上内容就是在Encoder-Decoder结构下的attention机制。
2. Attention机制
如果离开上面提到的Encoder-Decoder框架,单纯的讨论attention机制,会发现attention机制的核心就是从大量的信息中有选择的选择重要信息。捕获到对当前任务有用的重要的信息。
我们把输入的内容作为source,生成的目标作为target。
source可以看成由一个一个的<key,value>对组成的,target里面含有不同的query。
Attention机制的作用就是计算每一个query,在source中的值。
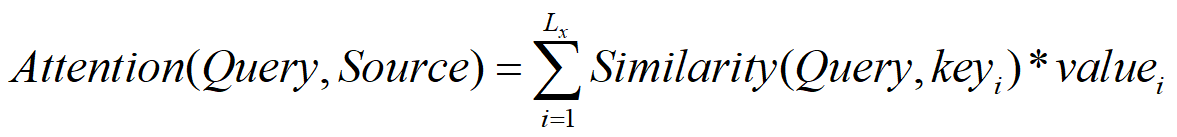
整个的计算过程分成两步。
第一步,计算source中的所有的key与query的相似性,并对计算得到的全部相似性做softmax归一化处理。
第二步,根据第一步中得到的权重,对value进行加权求和。
整个计算流程如下图所示
3. Self-Attention
在前面机器翻译的例子中,输入和输出的长度是不一样的。因为语言不同,所以句子长度通常不一样。在 self-attention中,我们可以认为source = target。 self-attention可以捕捉到句子里面的长依赖关系。
比如,对于句子
The animal didn't cross the street because it was too tired。
这里想要知道这个it代指的到底是什么,self-attention可以捕捉到句子中的长依赖关系。(Self-Attention 的核心是用文本中的其它词来增强目标词的语义表示,从而更好的利用上下文的信息。)将其结果可视化如下图所示。
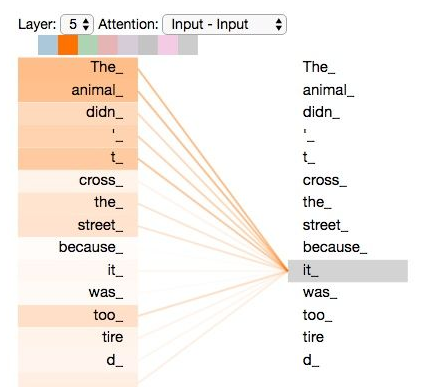
传统的RNN,LSTM网络,如果面对长句子的话,这种距离较远的依赖关系相比之下很难捕获到,因为根据RNN/LSTM的结构,需要按顺序进行序列计算,所以距离越远,关系越难捕捉。 而self-attention是针对句子中所有词两两计算,不存在距离长短这一说。此外,self-attention相比循环网络还有另外一个优点是便于并行计算。
3.1 下面将介绍self-attention的具体计算
首先,对于每一个词向量,我们创建3个向量,分别是query,key,value。
这三个向量是词向量与训练好的权重矩阵![]() 分别相乘得到的。
分别相乘得到的。
计算自注意力的第一步就是从每个编码器的输入向量(每个单词的词向量)中生成三个向量。也就是说对于每个单词,我们创造一个查询向量、一个键向量和一个值向量。这三个向量是通过词嵌入与三个权重矩阵后相乘创建的。
可以发现这些新向量在维度上比词嵌入向量更低。(他们的维度是64,而词嵌入和编码器的输入/输出向量的维度是512。)但实际上不强求维度更小,这只是一种基于架构上的选择,它可以使多头注意力(multiheaded attention)的大部分计算保持不变。
接下来,对于每个q而言,分别计算这个q与所有k的得分。计算公式
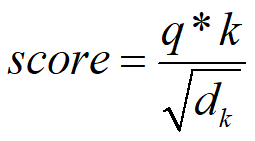
这里除以分母的作用是为了后面计算中有稳定的梯度。对于q1而言,经过计算后,获得了
![]()
n维句子的长度。
下一步把这些score进行softmax归一化。然后将归一化的结果与value向量相乘,获得最后的结果。
计算过程图
当遇到一个词的时候,整个的计算流程就和刚才介绍的一样。那么整个这个self-attention的作用是什么呢?其实是针对输入的句子,构建了一个attention map。假设输入句子是‘I have a dream’,整个句子作为输入,矩阵运算后,会得到一个4*4的attention map。如下图所示。
self-attention结构在Transformer结构中是非常重要的一步,这里先将其的基本过程梳理清楚。
对于Transformer结构的讲解,将在下一篇文章中详细介绍。
3.2 通过矩阵运算实现自注意力机制
在实际的应用场景,为了提高计算速度,我们采用的是矩阵的方式,直接计算出Query, Key, Value的矩阵,然后把embedding的值与三个矩阵直接相乘,把得到的新矩阵Q与K相乘,乘以一个常数,做softmax操作,最后乘上V矩阵
这种通过 query 和 key 的相似性程度来确定 value 的权重分布的方法被称为scaled dot-product attention:
Q,K,V的大小为[batch_size ,seq_length ,hidden_size].
3.3 Self-Attention知识点
3.3.1 Self-Attention 的时间复杂度是怎么计算的?
Self-Attention 时间复杂度: ,这里,n 是序列的长度,d 是 embedding 的维度,不考虑 batch 维。
Self-Attention 包括三个步骤:相似度计算,softmax 和加权平均。
它们分别的时间复杂度是:
相似度计算 可以看作大小为(n,d)和(d,n)的两个矩阵相乘: ,得到一个(n,n)的矩阵。
softmax 就是直接计算了,时间复杂度为 。
加权平均 可以看作大小为(n,n)和(n,d)的两个矩阵相乘: ,得到一个(n,d)的矩阵。
因此,Self-Attention 的时间复杂度是 。
这里再提一下 Tansformer 中的 Multi-Head Attention,多头 Attention,简单来说就是多个 Self-Attention 的组合,它的作用类似于 CNN 中的多核。
多头的实现不是循环的计算每个头,而是通过 transposes and reshapes,用矩阵乘法来完成的。
In practice, the multi-headed attention are done with transposes and reshapes rather than actual separate tensors. —— 来自 google BERT 源代码注释
Transformer/BERT 中把 d ,也就是 hidden_size/embedding_size 这个维度做了 reshape 拆分,可以去看 Google 的 TF 源码或者上面的 pytorch 源码:
hidden_size (d) = num_attention_heads (m) * attention_head_size (a),也即 d=m*a。
并将 num_attention_heads 维度 transpose 到前面,使得 Q 和 K 的维度都是 (m,n,a),这里不考虑 batch 维度。
这样点积可以看作大小为 (m,n,a) 和 (m,a,n) 的两个张量相乘,得到一个 (m,n,n) 的矩阵,其实就相当于 m 个头,时间复杂度是 。
张量乘法时间复杂度分析参见:矩阵、张量乘法的时间复杂度分析 [1]。
因此 Multi-Head Attention 时间复杂度就是 ,而实际上,张量乘法可以加速,因此实际复杂度会更低一些。
3.3.2. 不考虑多头的原因,self-attention中词向量不乘QKV参数矩阵,会怎么样?
对于 Attention 机制,都可以用统一的 query/key/value 模式去解释,而对于 self-attention,一般会说它的 q=k=v,这里的相等实际上是指它们来自同一个基础向量,而在实际计算时,它们是不一样的,因为这三者都是乘了 QKV 参数矩阵的。那如果不乘,每个词对应的 q,k,v 就是完全一样的。
在 self-attention 中,sequence 中的每个词都会和 sequence 中的每个词做点积去计算相似度,也包括这个词本身。
在相同量级的情况下,qi 与 ki 点积的值会是最大的(可以从“两数和相同的情况下,两数相等对应的积最大”类比过来)。
那在 softmax 后的加权平均中,该词本身所占的比重将会是最大的,使得其他词的比重很少,无法有效利用上下文信息来增强当前词的语义表示。
而乘以 QKV 参数矩阵,会使得每个词的 q,k,v 都不一样,能很大程度上减轻上述的影响。
当然,QKV 参数矩阵也使得多头,类似于 CNN 中的多核,去捕捉更丰富的特征/信息成为可能。
3.3.3. 在常规 attention 中,一般有 k=v,那 self-attention 可以嘛?
self-attention 实际只是 attention 中的一种特殊情况,因此 k=v 是没有问题的,也即 K,V 参数矩阵相同。
扩展到 Multi-Head Attention 中,乘以 Q、K 参数矩阵之后,其实就已经保证了多头之间的差异性了,在 q 和 k 点积 +softmax 得到相似度之后,从常规 attention 的角度,觉得再去乘以和 k 相等的 v 会更合理一些。
在 Transformer / BERT 中,完全独立的 QKV 参数矩阵,可以扩大模型的容量和表达能力。
但采用 Q,K=V 这样的参数模式,我认为也是没有问题的,也能减少模型的参数,又不影响多头的实现。
当然,上述想法并没有做过实验,为个人观点,仅供参考。
参考文献
[1]完全图解RNN、RNN变体、Seq2Seq、Attention机制
[2]深度学习中的注意力模型(2017版)
[3]详解Transformer (Attention Is All You Need)
[4]The Illustrated Transformer
[5]Visualizing A Neural Machine Translation Model