文章目录
- Attention
- 基本的Attention原理
- 参考
- Hierarchical Attention
- 原理
- 实践
- 参考
- Self Attention
- other Attention
Attention
Attention是一种机制,可以应用到许多不同的模型中,像CNN、RNN、seq2seq等。Attention通过权重给模型赋予了区分辨别的能力,从而抽取出更加关键及重要的信息,使模型做出更加准确的判断,同时不会对模型的计算和存储带来更大的开销。
基本的Attention原理
下面通过seq2seq模型中的Attention介绍Attention的原理。
seq2seq是RNN的一种变体,其不限制输入和输出的长度,是一种Encoder-Decoder的结构。未引入attention机制的seq2seq的结构如图
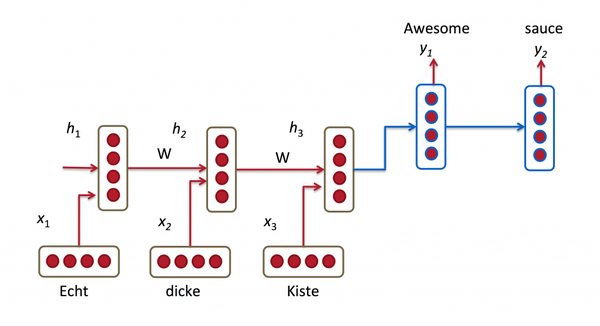
简化图如下
上图展示了将德语翻译成英语时的模型结构。encoder RNN(红色) 将输入语句信息编码到最后一个hidden vector中,并将其作为decoder(蓝色)初始的hidden vector,利用decoder解码成对应的其他语言中的文字。
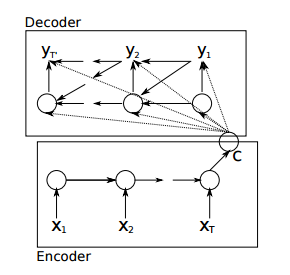
但对于较长的序列输入,由于长程梯度问题,最后的hidden vector不能保持所有的有效信息。通过引入attention机制,解决了长序列到定长向量转化时信息损失的瓶颈。引入attention机制后的动态图如下

下面给出数学上的运算过程
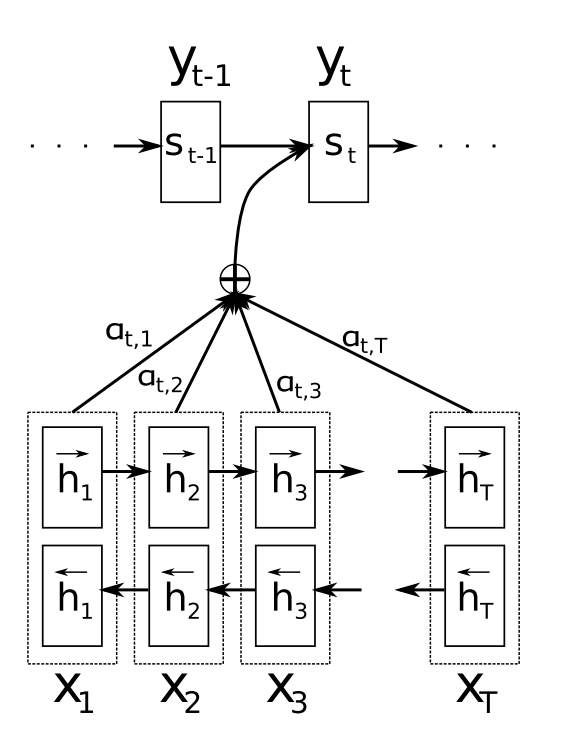
首先通过输入获得encoder中的隐状态
接着计算每一个encoder的隐状态与decoder中各个时刻的隐状态的关联性。现考虑decoder中t-1时刻的隐状态与encoder中每一个隐状态j的关联性。
即,写成相应的向量形式
。其中a是一种相关性的算符,例如常见的有点乘形式
,加权点乘
,加和
等等。
然后对 进行softmax操作将其normalize得到attention的分布,即
,展开形式为
再然后利用求得的对encoder中的所有隐状态进行加权求和得到decoder中各个时刻的隐状态对应的上下文向量
最后根据求得的上下文向量,可以求得decoder中t时刻(下一时刻)的隐状态及该位置的输出
上述过程中,通过获取encoder与decoder隐状态间的关联性,从而获取attention分布是关键。 通过观察attention权重矩阵的变化,可以更好地知道哪部分翻译对应哪部分源文字,如下图所示

Attention机制的引入,打破了之前只能利用encoder最终单一向量结果的限制,从而使模型可以集中在所有对于下一个目标单词重要的输入信息上,使模型效果得到极大的改善。
参考
Attention机制详解(一)——Seq2Seq中的Attention
Hierarchical Attention
原理
上面讲的在机器翻译中,seq2seq模型中的attention是基于源(encoder)与目标(decoder)的相关程度展开的,但是在文本分类中,只有源(原文),没有目标,在这种情况下,就需要attention的变种技术,叫self-Attention。即源(原文)自己内部的注意力机制。
self-Attention有不同的做法。比如Attention is All You Need中,相比之前的seq2seq模型中的attention,在机器翻译任务中,不仅去掉了rnn部分,全部换成attention,还通过把attention机制形式化成Key-Value的形式,表达了源语言和目标语言各自内部的注意力机制。这样做有利于更好的把控句子的结构和意义。变动后的模型就是大名鼎鼎的transformer。内部attention的可视化示意图如下:
在文本分类(Hierarchical Attention Networks for Document Classification)中,通过引入context vector uw(词级别的context vector) 和us(句级别的context vector)[待学习的参数] 来实现self-attention,从而找到高权重的词语和句子。
其主要思想是,首先考虑文档的分层结构:单词构成句子,句子构成文档,所以建模时也分这两部分进行。其次,句子中的不同单词和文档中的不同句子对文本分类来说分别具有不同的重要性,不能单纯的统一对待,所以引入Attention机制。而且引入Attention机制除了提高模型的精确度之外还可以进行单词、句子重要性的分析和可视化,让我们对文本分类的内部有一定了解。模型结构如下图所示:
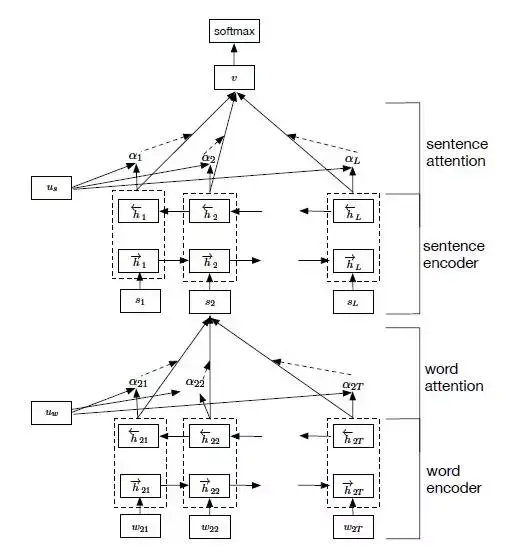
其主要由下面四个部分构成
- a word sequence encoder
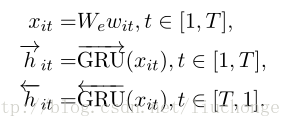
- a word-level attention layer

- a sentence encoder
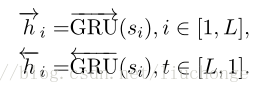
- a sentence-level attention layer
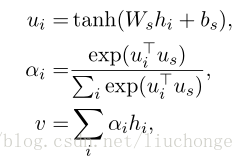
实践
在每一轮下的每一个批次(固定数量的文本数)中,首先通过选取当前批次下所有文档中最多的句子数以及所有句子中多的单词数来确定当前批次句子和词的维度。从而确定待训练数据的三个维度:文档数、句子数(最多,不足补0)、单词数(最多,不足补0),接着将待训练数据输入到嵌入层(embedding),获取word_embedding,并将word_embedding作为输入传到tf.nn.bidirectional_dynamic_rnn中,将到tf.nn.bidirectional_dynamic_rnn的输出作为attention的输入,求出词级别的attention输出,并将其作为sentence_embedding的输入再次传入到tf.nn.bidirectional_dynamic_rnn中,从而获取句级别的attention输出。最后将得到的sentence_embedding的输出全连接到神经元个数为种类个数的输出层,从而得到预测的种类。
model
from utils import *
import tensorflow as tf
from attention import attention
class hier_rnn():def __init__(self,args):self.args=argsself.sentence=tf.placeholder(tf.int32,[self.args.batch_size,None,None])self.target=tf.placeholder(tf.int64,[self.args.batch_size])self.seq_len=tf.placeholder(tf.int32,[None])self.max_len=tf.placeholder(tf.int32,shape=())def word_embedding(self,input):def cell():return tf.nn.rnn_cell.GRUCell(128)cell_bw=cell_fw=tf.nn.rnn_cell.MultiRNNCell([cell() for _ in range(3)])outputs,_=tf.nn.bidirectional_dynamic_rnn(cell_fw,cell_bw,input,sequence_length=self.seq_len,dtype=tf.float32,scope='word_embedding')return attention(outputs,128)def sentence_embedding(self,input):def cell():return tf.nn.rnn_cell.GRUCell(128)cell_bw=cell_fw=tf.nn.rnn_cell.MultiRNNCell([cell() for _ in range(3)])cell_fw_initial=cell_fw.zero_state(self.args.batch_size,tf.float32)cell_bw_initial=cell_bw.zero_state(self.args.batch_size,tf.float32)outputs,_=tf.nn.bidirectional_dynamic_rnn(cell_fw,cell_bw,input,initial_state_fw=cell_fw_initial,initial_state_bw=cell_bw_initial,scope='sentence_embedding')return attention(outputs,128)def forward(self):# time_step=self.sentence.shape[2].valuesen_in=tf.reshape(self.sentence,[self.args.batch_size*self.max_len,-1])with tf.device("/cpu:0"):embedding=tf.get_variable('embedding',shape=[89526,256])inputs=tf.nn.embedding_lookup(embedding,sen_in)word_embedding=self.word_embedding(inputs)word_embedding=tf.reshape(word_embedding,[self.args.batch_size,-1,256])sen_embedding=self.sentence_embedding(word_embedding)logits=tf.layers.dense(sen_embedding,2)cross_entropy=tf.reduce_mean(tf.nn.sparse_softmax_cross_entropy_with_logits(labels=self.target,logits=logits))optimizer=tf.train.AdamOptimizer().minimize(cross_entropy)correct=tf.equal(self.target,tf.argmax(tf.nn.softmax(logits),axis=1))accuracy=tf.reduce_mean(tf.cast(correct,tf.float32))return cross_entropy,optimizer,accuracydef train(self):cross_entropy,optimizer,accuracy=self.forward()with tf.Session() as sess:sess.run(tf.global_variables_initializer())for epoch in range(10):x_batch,y_batch,seq_len,max_len=next_batch(self.args.batch_size)for step in range(len(x_batch)):# print(y_batch[step])# print(y_batch[step])loss,_,acc=sess.run([cross_entropy,optimizer,accuracy],feed_dict={self.sentence:x_batch[step],self.target:y_batch[step],self.seq_len:seq_len[step],#单词数self.max_len:max_len[step]})#句子数if step%10==0:print("Epoch %d,Step %d,loss is %f"%(epoch,step,loss))print("Epoch %d,Step %d,accuracy is %f"%(epoch,step,acc))x_batch,y_batch,seq_len,max_len=next_batch(self.args.batch_size,mode='test')test_accuracy=0for step in range(len(x_batch)):acc=sess.run(accuracy,feed_dict={self.sentence:x_batch[step],self.target:y_batch[step],self.seq_len:seq_len[step],self.max_len:max_len[step]})test_accuracy+=accprint('test accuracy is %f'%(test_accuracy/len(x_batch)))attention
import tensorflow as tfdef attention(inputs,attention_size):inputs=tf.concat(inputs,2)v=tf.layers.dense(inputs,attention_size,activation=tf.nn.tanh)vu=tf.layers.dense(v,1,use_bias=False)alphas=tf.nn.softmax(vu)output=tf.reduce_mean(alphas*inputs,axis=1)return output
参考
一个Hierarchical Attention神经网络的实现
Hierarchical Attention Network for Document Classification阅读笔记
Hierarchical Attention Network for Document Classification
Self Attention
Attention is All You Need中的self-attention把attention机制形式化成Key-Value的形式,属于transformer的一部分,在讲transformer时再详细展开。
other Attention
其他形式的attention见 深度学习中Attention Mechanism详细介绍:原理、分类及应用