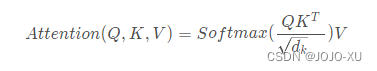文章目录
- 一、Attention机制是什么?
- 二、推荐论文与链接
- 三、self-attention
一、Attention机制是什么?
Attention机制最早在视觉领域提出,九几年就被提出来的思想,真正火起来应该算是2014年Google Mind发表了《Recurrent Models of Visual Attention》,使Attention机制流行起来,这篇论文采用了RNN模型,并加入了Attention机制来进行图像的分类。不同于全图扫描,该 算法每次仅瞥见图像中的部分区域,并按时间顺序 将多次瞥见的内容用循环神经网络加以整合,以建立图像的动态表示。
2015年,Bahdanau等人在论文《Neural Machine Translation by Jointly Learning to Align and Translate》中,将attention机制首次应用在nlp领域,其采用Seq2Seq+Attention模型来进行机器翻译,并且得到了效果的提升,Seq2Seq With Attention中进行了介绍。
2017 年,Google 机器翻译团队发表的《Attention is All You Need》中,完全抛弃了RNN和CNN等网络结构,而仅仅采用Attention机制来进行机器翻译任务,并且取得了很好的效果,注意力机制也成为了大家近期的研究热点。
二、推荐论文与链接
推荐先看看《自然语言处理中的注意力机制研究综述》论文解读:Attention is All you need https://zhuanlan.zhihu.com/p/46990010
【NLP论文笔记】Neural machine translation by jointly learning to align and translate https://www.jianshu.com/p/8d6341ded7eb
入门篇:一文看懂 Attention(本质原理+3大优点+5大类型) https://zhuanlan.zhihu.com/p/91839581
【self-attention论文】Non-local neural networks: https://arxiv.org/abs/1711.07971
Self-Attention Generative Adversarial Networks: https://arxiv.org/abs/1805.08318
【Multi-head Self-Attention计算复杂度】https://blog.csdn.net/qq_45588019/article/details/122599502
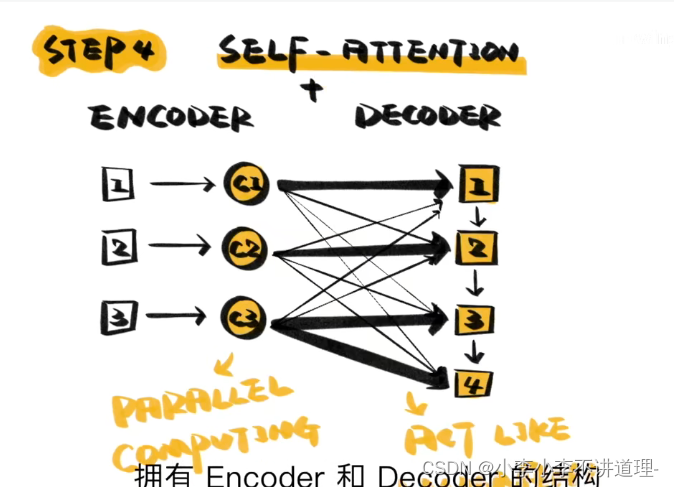
三、self-attention
Self Attention与传统的Attention机制非常的不同:传统的Attention是基于source端和target端的隐变量(hidden state)计算Attention的,得到的结果是源端的每个词与目标端每个词之间的依赖关系。但Self Attention不同,它分别在source端和target端进行,仅与source input或者target input自身相关的Self Attention,捕捉source端或target端自身的词与词之间的依赖关系;然后再把source端的得到的self Attention加入到target端得到的Attention中,捕捉source端和target端词与词之间的依赖关系。因此,self Attention Attention比传统的Attention mechanism效果要好,主要原因之一是,传统的Attention机制忽略了源端或目标端句子中词与词之间的依赖关系,相对比,self Attention可以不仅可以得到源端与目标端词与词之间的依赖关系,同时还可以有效获取源端或目标端自身词与词之间的依赖关系。
Transformer中提出的多头自注意力模块运算公式为: