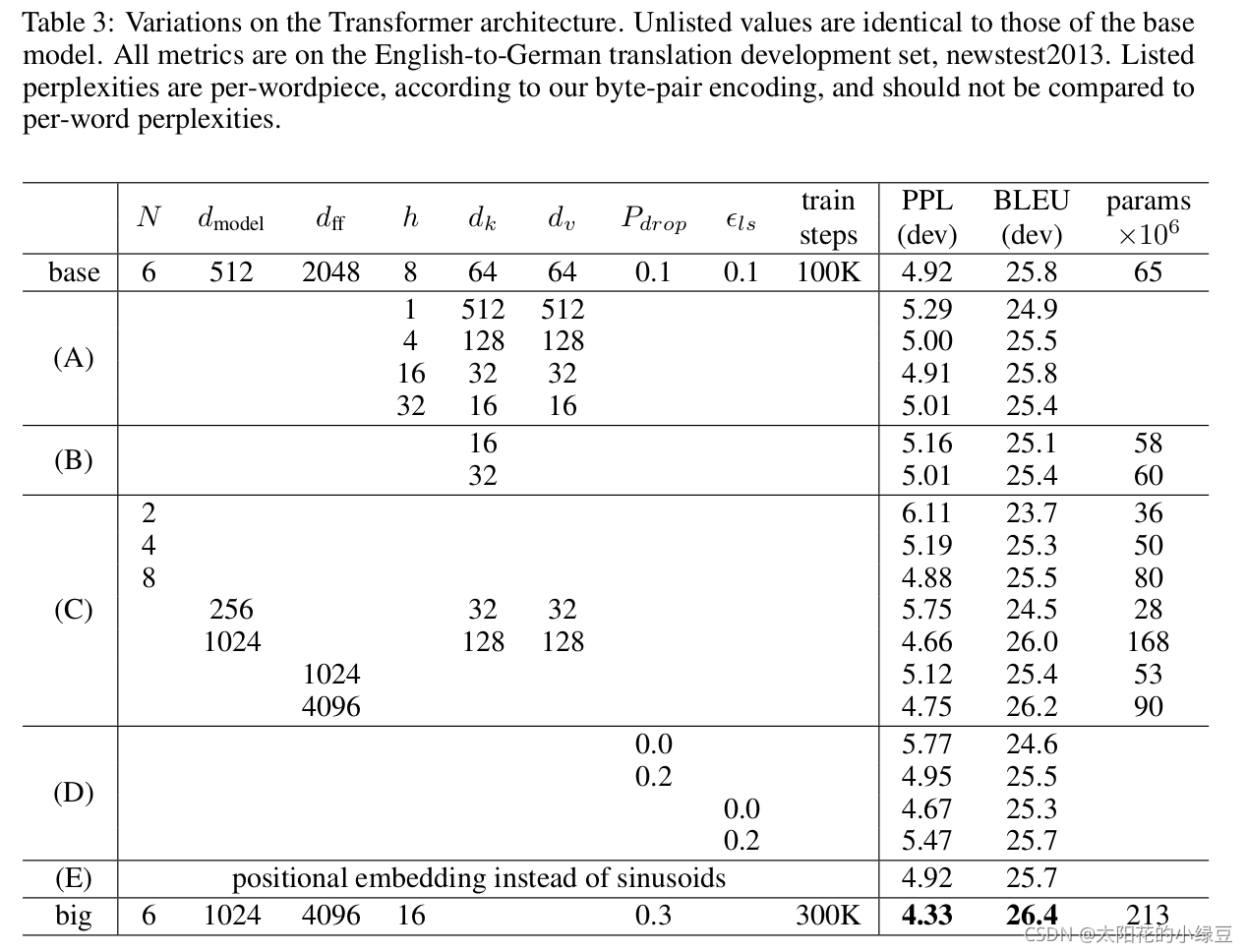
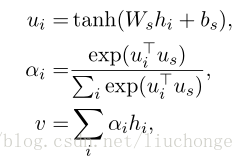Attention(注意力机制)在NLP、图像领域被广泛采用,其显而易见的优点包括:
(1)从context中捕捉关键信息;
(2)良好的可视性和可解释性。
我们常用QKV模型来理解Attention,Q指query,K指key,V指value。其整个流程包括三个步骤(如下图):
(1)Attention Score。通过Q和K的计算,得到各元素的attention score;
(2)Alignment。将attention score进行对齐/归一化;
(3)Concatenate。以归一化的attention score为权重,V为值进行加权平均。

所以,我们可以将广义的Attention技术简单理解为加权平均,至于如何计算权重,对什么进行加权计算,则取决于具体的应用场景和计算策略。
下面介绍下NLP中典型的Attention技术应用。
(1)Bahdanau/Additive Attention
2015年 ICLR 《Neural machine translation by jointly learning to align and translate》首次在机器翻译Seq2Seq模型中提出了attention的概念,用于目标语言与源语言token间的对齐,让模型自动学习到目标语言sequence中应当分别关注源语言的什么地方,从而清晰的解释了模型到底学习了什么。
该文采用了Bahdanau/Additive Attention的注意力算法:
- 计算Attention Score,即根据某个时间步上decoder的hidden向量与encoder的各hidden向量的FC计算,找到当前翻译时,需要从输入知道的重点信息:
e i j = a ( h j e n , h i d e ) = v a T tanh ( W a ∗ [ h j e n ; h i d e ] ) e_{ij}=a(\boldsymbol{h_j^{en}}, \boldsymbol{h_i^{de}})=\boldsymbol {v_a^T}\tanh( \boldsymbol {W_a}*[\boldsymbol{h_j^{en}};\boldsymbol{h_i^{de}}]) eij=a(hjen,hide)=vaTtanh(Wa∗[hjen;hide])
- 计算Alignment后的归一化值:
α i j = e i j ∑ j e i k \alpha_{ij}=\frac{e_{ij}}{\sum\limits_je_{ik}} αij=j∑eikeij - Concatenate得到当前时间步的加权context vector:
c i = ∑ j α i j h j e n \boldsymbol {c_i}=\sum\limits_j \alpha_{ij}\boldsymbol {h_j^{en}} ci=j∑αijhjen
在后续decoder部分的迭代计算中,考虑上述的context vector:
y i d e = f ( y i − 1 d e , h i d e , c i d e ) ; h i + 1 d e = g ( y i d e , h i d e ) \boldsymbol {y_i^{de}}=f(\boldsymbol{y_{i-1}^{de}},\boldsymbol{h_i^{de}},\boldsymbol{c_i^{de}}) ;\boldsymbol {h_{i+1}^{de}}=g(\boldsymbol{y_{i}^{de}},\boldsymbol{h_i^{de}}) yide=f(yi−1de,hide,cide);hi+1de=g(yide,hide)
(2)Luong/Multiplicative Attention
2015年 EMNLP 《Effective Approaches to Attention-based Neural Machine Translation》在上述Bahdanau/Additive Attention的基础上引入了各种变形,其中尤其以Luong/Multiplicative Attention被广为采用,其区别在于采用了矩阵乘法或向量的内积的形式直接计算,从而计算效率更高:
e i j = h j e n ∗ h i d e ; e i j = h j e n ∗ W ∗ h i d e e_{ij}=\boldsymbol{h_j^{en}}*\boldsymbol{h_i^{de}};\quad e_{ij}=\boldsymbol{h_j^{en}}*W*\boldsymbol{h_i^{de}} eij=hjen∗hide;eij=hjen∗W∗hide此外还可以采用多层感知机MLP的形式计算Attention Score:
e i j = a ( h j e n , h i d e ) = σ ( w 2 T tanh ( W 1 ∗ [ h j e n ; h i d e ] + b 1 ) + b 2 ) e_{ij}=a(\boldsymbol{h_j^{en}}, \boldsymbol{h_i^{de}})=\sigma(\boldsymbol {w_2^T}\tanh( \boldsymbol {W_1}*[\boldsymbol{h_j^{en}};\boldsymbol{h_i^{de}}]+\boldsymbol{b_1})+b_2) eij=a(hjen,hide)=σ(w2Ttanh(W1∗[hjen;hide]+b1)+b2)
值的注意的是:虽然attention的理念脱胎于机器翻译Seq2Seq架构,但完全可以推广到其它场景,用于提取背景语义中的有价值信息。
(3)Soft&Hard Attention
论文《Show, Attend and Tell: Neural Image Caption Generation with Visual Attention》提出了Soft&Hard Attention的概念。
Attention的KQV视角可以理解为一个软寻址的过程,即对寻址结果进行加权求和(avg-sum)。自然而然的,我们可以通过硬寻址的方式处理attention结果,即直接取attention score最大对应的context vector。
采用Hard Attention的方式得到的结果往往更加生硬,忽略了其它vector对的影响,从而倾向于过拟合,所以实践中更多的采用的soft attention的计算思路。
(4)Local&Global Attention
在论文《Effective Approaches to Attention-based Neural Machine Translation》中又提出了Local&Global Attention的概念。顾名思义,即attention作用的上下文window大小,可以是全局性的,也可以是局部的。
Local Attention的初衷很简单:进一步缩小关注的范围,从而减少不必要的噪声。但问题在于如何选择合适的window size?文中提出了local-m和local-p两套策略,但这种复杂化的计算本身就引入了假设和计算复杂度,效果也并不显著,因此在实践中并未被推广。
(5)Scaled Multi-head Self-attention
如果说前面各种attention玩法是传统Pipeline上下文信息提取的优化,那么提出Transformer的《Attention is All You Need》中则将Attention技术发扬广大,将其构造成一种信息抽取器,兼具CNN并行化和RNN长距离依赖的优势,为后续GPT、Bert和XLNet等预训练模型的诞生奠定了基础。
Transformer的具体细节本文不做解释,下面仅仅介绍下其中的核心部件:Scaled Multi-head Self-attention。
从名称中不难知道,其由Self-attention、scaled和multi-head三个组成部分:
a) Self-attention
前文介绍的各类attention均是decoder对encoder序列的attention过程,而 Self-attention则直接作用在encoder序列或decoder序列内部,从而获得序列内部各元素间的相关性。
在具体实现中,通过引入Q、K、V参数矩阵,将每个token转换为对应的query、key和value向量,接着就按照前文计算流程进行计算。

b) scaled
文章在实践中发现,直接计算得到的query、key和value向量在经过Multiplicative/dot Attention操作后效果并不如Additive Attention,作者们认为在较大的向量维度前提下,内积score结果过大,从而落入softmax的饱和区域,使得归一化结果过于hard,而BP梯度过小。所以在得到内积结果,通过除以 d k \sqrt{d_k} dk进行缩放,从而在利用Multiplicative/dot Attention矩阵计算优势的同时,保证了attention的效果。
c) multi-head
文章在每一层的self-attention计算中,采用了多组的Q、K、V参数矩阵。如果说仅用一组Q、K、V得到的是attention结果的平均值,那么多组Q、K、V就扮演了类似filters的功能,可以在不同的sub space中提取不同的特征,从而使得特征提取结果更加丰富。
(6)Multi-dimensional Attention
Multi-dimensional Attention和multi-head的目的一样,即通过多组的attention计算使得结果的信息更加丰富,其区别在于其直接通过一个3-D的weight张量进行求解。
(7)Hierarchical Attention
Hierarchical Attention是指在使用Attention时,通过层次的反复使用,完成对不同粒度信息重要性的提取,比如token-sentence-doc,可以通过对token进行attention计算完成对sentence的编码,然后再对sentence进行attention实现对整个doc的编码,其代表作为《Hierarchical attention networks for document classification》。
总结:Attention可以从复杂信息中有效提取重要信息,具备良好的计算效果和可解释性,已经成为NLP各任务和模型广泛使用的标准模块。
【Reference】
- 遍地开花的 Attention ,你真的懂吗?
- An Introductory Survey on Attention Mechanisms in NLP Problems