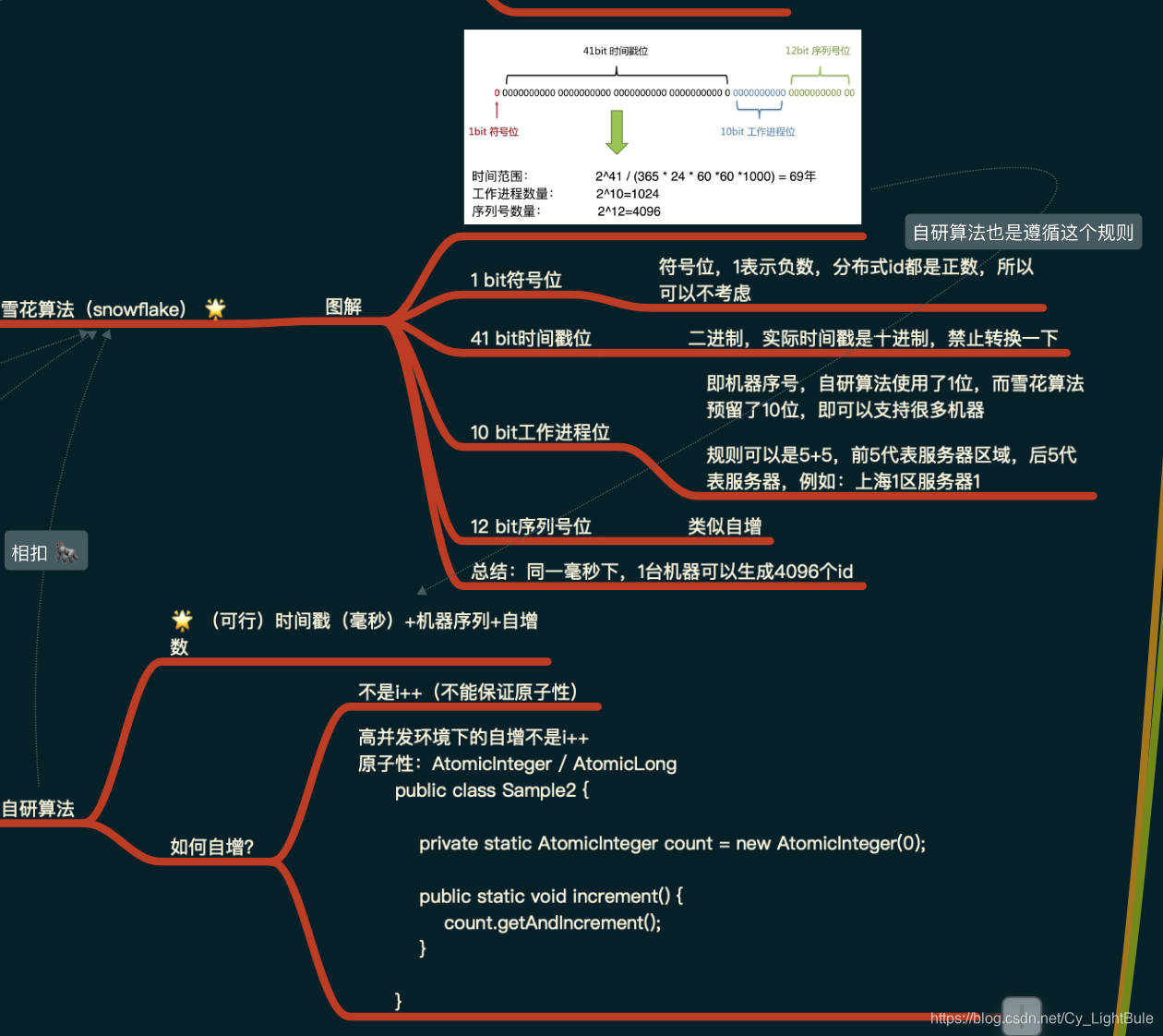
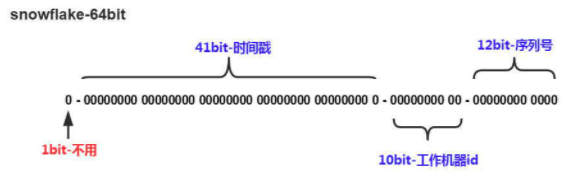
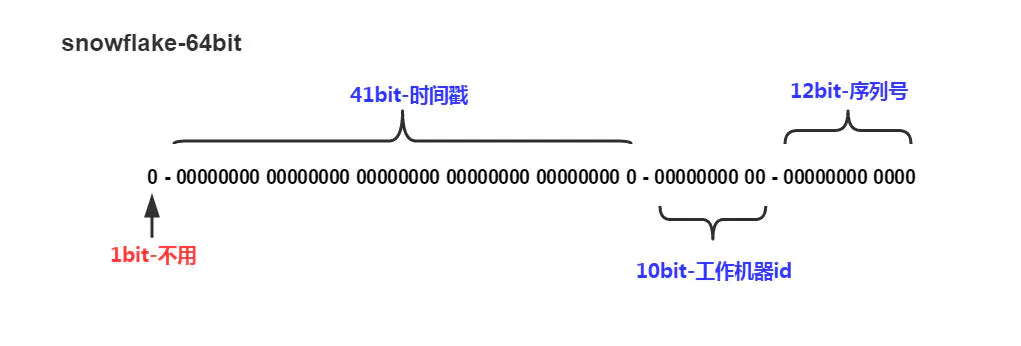
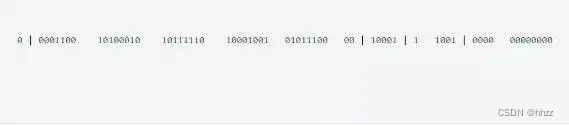
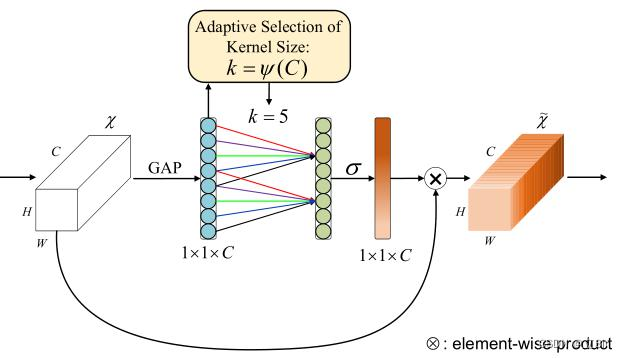
网络架构图:
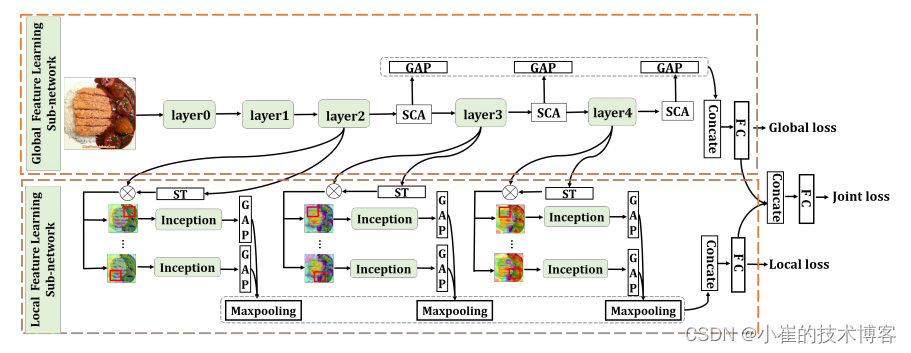
准备模型:
model_name = 'se_resnext101_32x4d'
model = MODEL( num_classes= 500 , senet154_weight = WEIGHT_PATH, multi_scale = True, learn_region=True)
model = torch.nn.DataParallel(model)
vgg16 = model
vgg16.load_state_dict(torch.load('./model/ISIAfood500.pth'))
Senet模型代码:
"""这段代码定义了一个名为senet154的函数,它使用SENet模型来进行图像分类。
"""def senet154(num_classes=1000, pretrained='imagenet'):model = SENet(SEBottleneck, [3, 8, 36, 3], groups=64, reduction=16,dropout_p=0.2, num_classes=num_classes)if pretrained is not None:settings = pretrained_settings['senet154'][pretrained]initialize_pretrained_model(model, num_classes, settings)return model"""SENet是一种卷积神经网络,它使用SEBottleneck块来增强特征表示。这个函数
使用了一个包含四个元素的列表来定义SENet的结构,其中每个元素表示一个阶段,
每个阶段包含多个SEBottleneck块。groups参数指定了SEBottleneck块中的卷积分组数,
reduction参数指定了SE块中的通道缩减比例。如果pretrained参数不为None,则会使用
预训练的权重来初始化模型。预训练的权重存储在pretrainedsettings字典中,
可以通过指定pretrained参数来选择不同的预训练权重。最后,函数返回SENet模型。"""class SENet(nn.Module):def __init__(self, block, layers, groups, reduction, dropout_p=0.2,inplanes=128, input_3x3=True, downsample_kernel_size=3,super(SENet, self).__init__()self.inplanes = inplanesif input_3x3:layer0_modules = [('conv1', nn.Conv2d(3, 64, 3, stride=2, padding=1,bias=False)),('bn1', nn.BatchNorm2d(64)),('relu1', nn.ReLU(inplace=True)), # 从这 224 -> 112 stride =2 ('conv2', nn.Conv2d(64, 64, 3, stride=1, padding=1,bias=False)),('bn2', nn.BatchNorm2d(64)),('relu2', nn.ReLU(inplace=True)),('conv3', nn.Conv2d(64, inplanes, 3, stride=1, padding=1,bias=False)),('bn3', nn.BatchNorm2d(inplanes)),('relu3', nn.ReLU(inplace=True)), # 输出的是 128 * 112* 112] else:layer0_modules = [('conv1', nn.Conv2d(3, inplanes, kernel_size=7, stride=2,padding=3, bias=False)),('bn1', nn.BatchNorm2d(inplanes)),('relu1', nn.ReLU(inplace=True)),]# To preserve compatibility with Caffe weights `ceil_mode=True`# is used instead of `padding=1`.layer0_modules.append(('pool', nn.MaxPool2d(3, stride=2,ceil_mode=True))) # 这个 就 变成了 112 -> 56self.layer0 = nn.Sequential(OrderedDict(layer0_modules)) # output 128 * 56 * 56self.layer1 = self._make_layer(block,planes=64,blocks=layers[0],groups=groups,reduction=reduction,downsample_kernel_size=1,downsample_padding=0 # layer 1 不会降尺寸。 但是会改变通道。 所以输出是256 * 56 *56)self.layer2 = self._make_layer(block,planes=128,blocks=layers[1],stride=2,groups=groups,reduction=reduction,downsample_kernel_size=downsample_kernel_size,downsample_padding=downsample_padding # layer 2 降尺寸。 因为stride =2 要进行降采样。 输出就是 512 * 28 * 28) self.layer3 = self._make_layer(block,planes=256,blocks=layers[2],stride=2,groups=groups,reduction=reduction,downsample_kernel_size=downsample_kernel_size,downsample_padding=downsample_padding # layer 3 降尺寸。 因为stride =2 要进行降采样。 输出就是 1024 * 14 * 14)self.layer4 = self._make_layer(block,planes=512,blocks=layers[3],stride=2,groups=groups,reduction=reduction,downsample_kernel_size=downsample_kernel_size, # layer 4 降尺寸。 因为stride =2 要进行降采样。 输出就是 2048 * 7 * 7downsample_padding=downsample_padding)self.avg_pool = nn.AvgPool2d(7, stride=1)self.dropout = nn.Dropout(dropout_p) if dropout_p is not None else Noneself.last_linear = nn.Linear(512 * block.expansion, num_classes)def _make_layer(self, block, planes, blocks, groups, reduction, stride=1,downsample_kernel_size=1, downsample_padding=0):downsample = Noneif stride != 1 or self.inplanes != planes * block.expansion:downsample = nn.Sequential(nn.Conv2d(self.inplanes, planes * block.expansion,kernel_size=downsample_kernel_size, stride=stride,padding=downsample_padding, bias=False),nn.BatchNorm2d(planes * block.expansion),)layers = []layers.append(block(self.inplanes, planes, groups, reduction, stride,downsample))self.inplanes = planes * block.expansionfor i in range(1, blocks):layers.append(block(self.inplanes, planes, groups, reduction))return nn.Sequential(*layers)def features(self, x):x = self.layer0(x)x = self.layer1(x)x = self.layer2(x)x = self.layer3(x)x = self.layer4(x)return xdef logits(self, x):x = self.avg_pool(x)if self.dropout is not None:x = self.dropout(x)x = x.view(x.size(0), -1)x = self.last_linear(x)return xdef forward(self, x):x = self.features(x)x = self.logits(x)return x
模型构建代码:
class ConvBlock(nn.Module):"""基本卷积块。卷积 + 批量归一化 + relu。Args:in_c (int): 输入通道数。out_c (int): 输出通道数。k (int or tuple): 卷积核大小。s (int or tuple): 步长。p (int or tuple): 填充。"""def __init__(self, in_c, out_c, k, s=1, p=0):super(ConvBlock, self).__init__()self.conv = nn.Conv2d(in_c, out_c, k, stride=s, padding=p)self.bn = nn.BatchNorm2d(out_c)def forward(self, x):return F.relu(self.bn(self.conv(x)))# 定义InceptionA模块
class InceptionA(nn.Module):def __init__(self, in_channels, out_channels):super(InceptionA, self).__init__()mid_channels = out_channels // 4# 第一个分支self.stream1 = nn.Sequential(ConvBlock(in_channels, mid_channels, 1), # 1x1卷积ConvBlock(mid_channels, mid_channels, 3, p=1), # 3x3卷积)# 第二个分支self.stream2 = nn.Sequential(ConvBlock(in_channels, mid_channels, 1), # 1x1卷积ConvBlock(mid_channels, mid_channels, 3, p=1), # 3x3卷积)# 第三个分支self.stream3 = nn.Sequential(ConvBlock(in_channels, mid_channels, 1), # 1x1卷积ConvBlock(mid_channels, mid_channels, 3, p=1), # 3x3卷积)# 第四个分支self.stream4 = nn.Sequential(nn.AvgPool2d(3, stride=1, padding=1), # 平均池化ConvBlock(in_channels, mid_channels, 1), # 1x1卷积)def forward(self, x):# 将四个分支的输出拼接在一起s1 = self.stream1(x)s2 = self.stream2(x)s3 = self.stream3(x)s4 = self.stream4(x)y = torch.cat([s1, s2, s3, s4], dim=1)return y# 定义InceptionB模块
class InceptionB(nn.Module):def __init__(self, in_channels, out_channels):super(InceptionB, self).__init__()mid_channels = out_channels // 4# 第一个分支self.stream1 = nn.Sequential(ConvBlock(in_channels, mid_channels, 1), # 1x1卷积ConvBlock(mid_channels, mid_channels, 3, s=2, p=1), # 3x3卷积)# 第二个分支self.stream2 = nn.Sequential(ConvBlock(in_channels, mid_channels, 1), # 1x1卷积ConvBlock(mid_channels, mid_channels, 3, p=1), # 3x3卷积ConvBlock(mid_channels, mid_channels, 3, s=2, p=1), # 3x3卷积)# 第三个分支self.stream3 = nn.Sequential(nn.MaxPool2d(3, stride=2, padding=1), # 最大池化ConvBlock(in_channels, mid_channels*2, 1), # 1x1卷积)def forward(self, x):# 分别对三个分支进行计算s1 = self.stream1(x)s2 = self.stream2(x)s3 = self.stream3(x)# 将三个分支的结果进行拼接y = torch.cat([s1, s2, s3], dim=1)return yclass SpatialAttn(nn.Module):"""Spatial Attention (Sec. 3.1.I.1)"""def __init__(self):super(SpatialAttn, self).__init__()self.conv1 = ConvBlock(1, 1, 3, s=2, p=1)self.conv2 = ConvBlock(1, 1, 1)def forward(self, x):# global cross-channel averagingx = x.mean(1, keepdim=True) # 由hwc 变为 hw1# 3-by-3 convh = x.size(2)x = self.conv1(x)# bilinear resizingx = F.upsample(x, (h,h), mode='bilinear', align_corners=True)# scaling convx = self.conv2(x)return x ## 返回的是h*w*1 的 soft mapclass ChannelAttn(nn.Module):"""通道注意力机制"""def __init__(self, in_channels, reduction_rate=16):super(ChannelAttn, self).__init__()assert in_channels%reduction_rate == 0self.conv1 = ConvBlock(in_channels, in_channels // reduction_rate, 1)self.conv2 = ConvBlock(in_channels // reduction_rate, in_channels, 1)def forward(self, x):# 压缩操作(全局平均池化)x = F.avg_pool2d(x, x.size()[2:]) # 激励操作(2个卷积层)x = self.conv1(x)x = self.conv2(x)return x'''
空间和通道上的attention 融合
就是空间和通道上的attention做一个矩阵乘法
'''class SoftAttn(nn.Module):"""Soft Attention (Sec. 3.1.I)Aim: Spatial Attention + Channel AttentionOutput: attention maps with shape identical to input."""def __init__(self, in_channels):super(SoftAttn, self).__init__()self.spatial_attn = SpatialAttn()self.channel_attn = ChannelAttn(in_channels)self.conv = ConvBlock(in_channels, in_channels, 1)def forward(self, x):y_spatial = self.spatial_attn(x) # 空间注意力输出y_channel = self.channel_attn(x) # 通道注意力输出y = y_spatial * y_channel # 空间注意力和通道注意力相乘y = torch.sigmoid(self.conv(y)) # 卷积块输出return y'''
输出的是STN 需要的theta
'''
class HardAttn(nn.Module):"""Hard Attention (Sec. 3.1.II)"""def __init__(self, in_channels):super(HardAttn, self).__init__()self.fc = nn.Linear(in_channels, 4*2)self.init_params()def init_params(self):self.fc.weight.data.zero_()# 初始化 参数# if x_t = 0 the performance is very lowself.fc.bias.data.copy_(torch.tensor([0.3, -0.3, 0.3, 0.3, -0.3, 0.3, -0.3, -0.3], dtype=torch.float))def forward(self, x):# squeeze operation (global average pooling)x = F.avg_pool2d(x, x.size()[2:]).view(x.size(0), x.size(1))# predict transformation parameterstheta = torch.tanh(self.fc(x))theta = theta.view(-1, 4, 2)return theta# 返回的是 2T T为区域数量。 因为尺度会固定。 所以只要学位移的值class HarmAttn(nn.Module):"""Harmonious Attention (Sec. 3.1)"""# 定义一个名为HarmAttn的类,继承自nn.Module类,表示这是一个神经网络模型def __init__(self, in_channels):super(HarmAttn, self).__init__()# 调用父类的构造函数,初始化神经网络模型self.soft_attn = SoftAttn(in_channels)# 定义一个名为soft_attn的属性,其值为SoftAttn(in_channels),表示该属性是一个软注意力机制self.hard_attn = HardAttn(in_channels)# 定义一个名为hard_attn的属性,其值为HardAttn(in_channels),表示该属性是一个硬注意力机制def forward(self, x):# 定义一个名为forward的函数,表示前向传播过程y_soft_attn = self.soft_attn(x)# 定义一个名为y_soft_attn的变量,其值为self.soft_attn(x),表示使用软注意力机制对输入x进行处理theta = self.hard_attn(x)# 定义一个名为theta的变量,其值为self.hard_attn(x),表示使用硬注意力机制对输入x进行处理return y_soft_attn, thetaclass MODEL(nn.Module):'''cvper2020的主模型'''def __init__(self, num_classes, senet154_weight, nchannels=[256,512,1024,2048], multi_scale = False ,learn_region=True, use_gpu=True):super(MODEL,self).__init__()self.learn_region=learn_regionself.use_gpu = use_gpuself.conv = ConvBlock(3, 32, 3, s=2, p=1)self.senet154_weight = senet154_weightself.multi_scale = multi_scaleself.num_classes = num_classes# 构建SEnet154 senet154_ = senet154(num_classes=1000, pretrained=None)senet154_.load_state_dict(torch.load(self.senet154_weight))self.extract_feature = senet154_.layer0#全局backboneself.global_layer1 = senet154_.layer1self.global_layer2 = senet154_.layer2self.global_layer3 = senet154_.layer3self.global_layer4 = senet154_.layer4self.classifier_global =nn.Sequential(nn.Linear(2048*2, 2048), # 将4个区域 融合成一个 需要加上batchnorma1d, 和 relunn.BatchNorm1d(2048),nn.ReLU(),nn.Dropout(0.2),nn.Linear(2048, num_classes),)if self.multi_scale:self.global_fc = nn.Sequential(nn.Linear(2048+512+1024, 2048), # 将4个区域 融合成一个 需要加上batchnorma1d, 和 relunn.BatchNorm1d(2048),nn.ReLU(),)self.global_out = nn.Linear(2048,num_classes) # global 分类else:self.global_out = nn.Linear(2048,num_classes) # global 分类self.ha2 = HarmAttn(nchannels[1])self.ha3 = HarmAttn(nchannels[2])self.ha4 = HarmAttn(nchannels[3])self.dropout = nn.Dropout(0.2) # 分类层之前使用dropoutif self.learn_region:self.init_scale_factors()self.local_conv1 = InceptionB(nchannels[1], nchannels[1])self.local_conv2 = InceptionB(nchannels[2], nchannels[2])self.local_conv3 = InceptionB(nchannels[3], nchannels[3]) self.local_fc = nn.Sequential(nn.Linear(2048+512+1024, 2048), # 将4个区域 融合成一个 需要加上batchnorma1d, 和 relunn.BatchNorm1d(2048),nn.ReLU(),)self.classifier_local = nn.Linear(2048,num_classes)def init_scale_factors(self):# 初始化四个区域的缩放因子(s_w,s_h)# s_w和s_h是固定的。self.scale_factors = []self.scale_factors.append(torch.tensor([[0.5, 0], [0, 0.5]], dtype=torch.float))self.scale_factors.append(torch.tensor([[0.5, 0], [0, 0.5]], dtype=torch.float))self.scale_factors.append(torch.tensor([[0.5, 0], [0, 0.5]], dtype=torch.float))self.scale_factors.append(torch.tensor([[0.5, 0], [0, 0.5]], dtype=torch.float))def stn(self, x, theta):"""执行空间变换x: (batch, channel, height, width)theta: (batch, 2, 3)"""grid = F.affine_grid(theta, x.size())x = F.grid_sample(x, grid)return xdef transform_theta(self, theta_i, region_idx):"""将theta转换为包括(s_w,s_h)的形式,结果为(batch,2,3)"""scale_factors = self.scale_factors[region_idx]theta = torch.zeros(theta_i.size(0), 2, 3)theta[:,:,:2] = scale_factorstheta[:,:,-1] = theta_iif self.use_gpu: theta = theta.cuda()return thetadef forward(self, x):batch_size = x.size()[0] # 获取批量大小x = self.extract_feature(x) # 输出形状为128 * 56 *56 senet154第0层layer 提取特征# =================layer 1 ===============# 全局分支x1 = self.global_layer1(x) # 输出形状为256*56*56#============layer 2================#全局分支x2 = self.global_layer2(x1) # x2是512*28*28x2_attn, x2_theta = self.ha2(x2)x2_out = x2 * x2_attnif self.multi_scale:# attention global layer1 avg pooling x2_avg = Fx2_avg = F.adaptive_avg_pool2d(x2_out, (1, 1)).view(x2_out.size(0), -1) #512 向量# local branchif self.learn_region:x2_local_list = []for region_idx in range(4):x2_theta_i = x2_theta[:,region_idx,:]x2_theta_i = self.transform_theta(x2_theta_i, region_idx)x2_trans_i = self.stn(x2, x2_theta_i) #256*56*26x2_trans_i = F.upsample(x2_trans_i, (56, 56), mode='bilinear', align_corners=True)x2_local_i = x2_trans_i x2_local_i = self.local_conv1(x2_local_i) # 512*28*28x2_local_list.append(x2_local_i)#============layer 3================#global branchx3 = self.global_layer3(x2_out) # x3 is 1024*14*14# print('layer3 output')# print(x3.size())x3_attn, x3_theta = self.ha3(x3)x3_out = x3 * x3_attnif self.multi_scale:# attention global layer1 avg pooling x3_avg = F.adaptive_avg_pool2d(x3_out, (1, 1)).view(x3_out.size(0), -1) #1024 向量# local branchif self.learn_region:x3_local_list = []for region_idx in range(4):x3_theta_i = x3_theta[:,region_idx,:]x3_theta_i = self.transform_theta(x3_theta_i, region_idx)x3_trans_i = self.stn(x3, x3_theta_i) #512*28*28x3_trans_i = F.upsample(x3_trans_i, (28, 28), mode='bilinear', align_corners=True)x3_local_i = x3_trans_i x3_local_i = self.local_conv2(x3_local_i) # 1024*14*14x3_local_list.append(x3_local_i)#============layer 4================#global branchx4 = self.global_layer4(x3_out) # 2048*7*7x4_attn, x4_theta = self.ha4(x4)x4_out = x4 * x4_attn# local branchif self.learn_region:x4_local_list = []for region_idx in range(4):x4_theta_i = x4_theta[:,region_idx,:]x4_theta_i = self.transform_theta(x4_theta_i, region_idx)x4_trans_i = self.stn(x4, x4_theta_i) #1024*14*14x4_trans_i = F.upsample(x4_trans_i, (14,14), mode='bilinear', align_corners=True)x4_local_i = x4_trans_i x4_local_i = self.local_conv3(x4_local_i) # 2048*7*7x4_local_list.append(x4_local_i)# ============== Feature generation ==============# global branchx4_avg = F.avg_pool2d(x4_out, x4_out.size()[2:]).view(x4_out.size(0), -1) #全局pooling 2048 之前已经relu过了if self.multi_scale:multi_scale_feature = torch.cat([x2_avg, x3_avg, x4_avg],1)global_fc = self.global_fc(multi_scale_feature)global_out = self.global_out(self.dropout(global_fc))else:global_out = self.global_out(x4_avg) # 2048 -> num_classesif self.learn_region:x_local_list = []local_512 = torch.randn(batch_size, 4, 512).cuda()local_1024 = torch.randn(batch_size, 4, 1024).cuda()local_2048 = torch.randn(batch_size, 4, 2048).cuda()for region_idx in range(4):x2_local_i = x2_local_list[region_idx]x2_local_i = F.avg_pool2d(x2_local_i, x2_local_i.size()[2:]).view(x2_local_i.size(0), -1) #每个local 都全局poolinglocal_512[:,region_idx] = x2_local_ix3_local_i = x3_local_list[region_idx]x3_local_i = F.avg_pool2d(x3_local_i, x3_local_i.size()[2:]).view(x3_local_i.size(0), -1) #每个local 都全局poolinglocal_1024[:,region_idx] = x3_local_ix4_local_i = x4_local_list[region_idx]x4_local_i = F.avg_pool2d(x4_local_i, x4_local_i.size()[2:]).view(x4_local_i.size(0), -1) #每个local 都全局poolinglocal_2048[:,region_idx] = x4_local_ilocal_512_maxpooing = local_512.max(1)[0]local_1024_maxpooing = local_1024.max(1)[0]local_2048_maxpooing = local_2048.max(1)[0]local_concate = torch.cat([local_512_maxpooing, local_1024_maxpooing, local_2048_maxpooing], 1)local_fc = self.local_fc(local_concate)local_out = self.classifier_local(self.dropout(local_fc))if self.multi_scale:out = torch.cat([global_fc,local_fc],1)else: out = torch.cat([x4_avg, local_512_maxpooing, local_1024_maxpooing, local_2048_maxpooing], 1) # global 和 local 一起做拼接 2048*2out = self.classifier_global(out)if self.learn_region:return out, global_out,local_outelse:return global_out

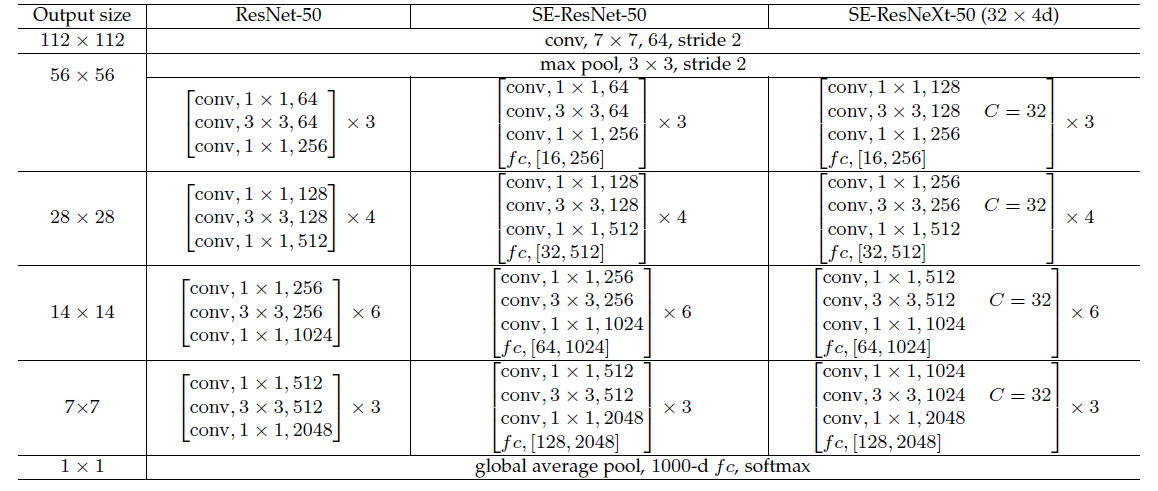
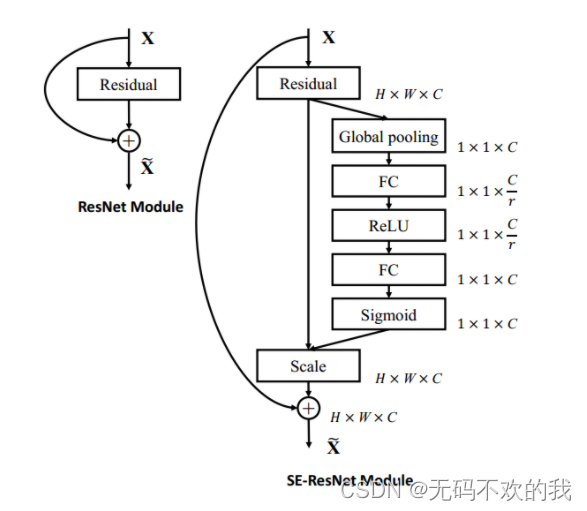


![[ 注意力机制 ] 经典网络模型1——SENet 详解与复现](https://img-blog.csdnimg.cn/76f92bb7921e4293800b75d7dcdde90f.png?x-oss-process=image/watermark,type_d3F5LXplbmhlaQ,shadow_50,text_Q1NETiBASG9yaXpvbiBNYXg=,size_14,color_FFFFFF,t_70,g_se,x_16#pic_center)