各位同学好,今天和大家分享一下attention注意力机制在CNN卷积神经网络中的应用,重点介绍三种注意力机制,及其代码复现。
在我之前的神经网络专栏的文章中也使用到过注意力机制,比如在MobileNetV3、EfficientNet网络中都是用了SE注意力机制,感兴趣的可以看一下:https://blog.csdn.net/dgvv4/category_11517910.html。那么今天就和大家来聊一聊注意力机制。
1. 引言
注意力机制源于对人类视觉的研究。在认知科学中,由于信息处理的瓶颈,人类会选择性地关注所有信息中的一部分,同时忽略其他可见信息。为了合理利用有限的视觉信息处理资源,人类需要选择视觉区域中的特定部分,然后重点关注它。
注意力机制没有严格的数学定义,例如传统的局部图像特征提取、滑动窗口方法等都可以看作是一种注意力机制。在神经网络中,注意力机制通常是一个额外的神经网络,能够硬性选择输入的某些部分,或者给输入的不同部分分配不同的权重。注意力机制能够从大量的信息中筛选出重要的信息。
在神经网络中引入注意力机制有很多种方法,以卷积神经网络为例,可以在空间维度增加引入注意力机制,也可以在通道维度增加注意力机制(SE),当然也有混合维度(CBAM)即空间维度和通道维度增加注意力机制。
2. SENet注意力机制
2.1 方法介绍
SE注意力机制(Squeeze-and-Excitation Networks)在通道维度增加注意力机制,关键操作是squeeze和excitation。
通过自动学习的方式,即使用另外一个新的神经网络,获取到特征图的每个通道的重要程度,然后用这个重要程度去给每个特征赋予一个权重值,从而让神经网络重点关注某些特征通道。提升对当前任务有用的特征图的通道,并抑制对当前任务用处不大的特征通道。
如下图所示,在输入SE注意力机制之前(左侧白图C2),特征图的每个通道的重要程度都是一样的,通过SENet之后(右侧彩图C2),不同颜色代表不同的权重,使每个特征通道的重要性变得不一样了,使神经网络重点关注某些权重值大的通道。
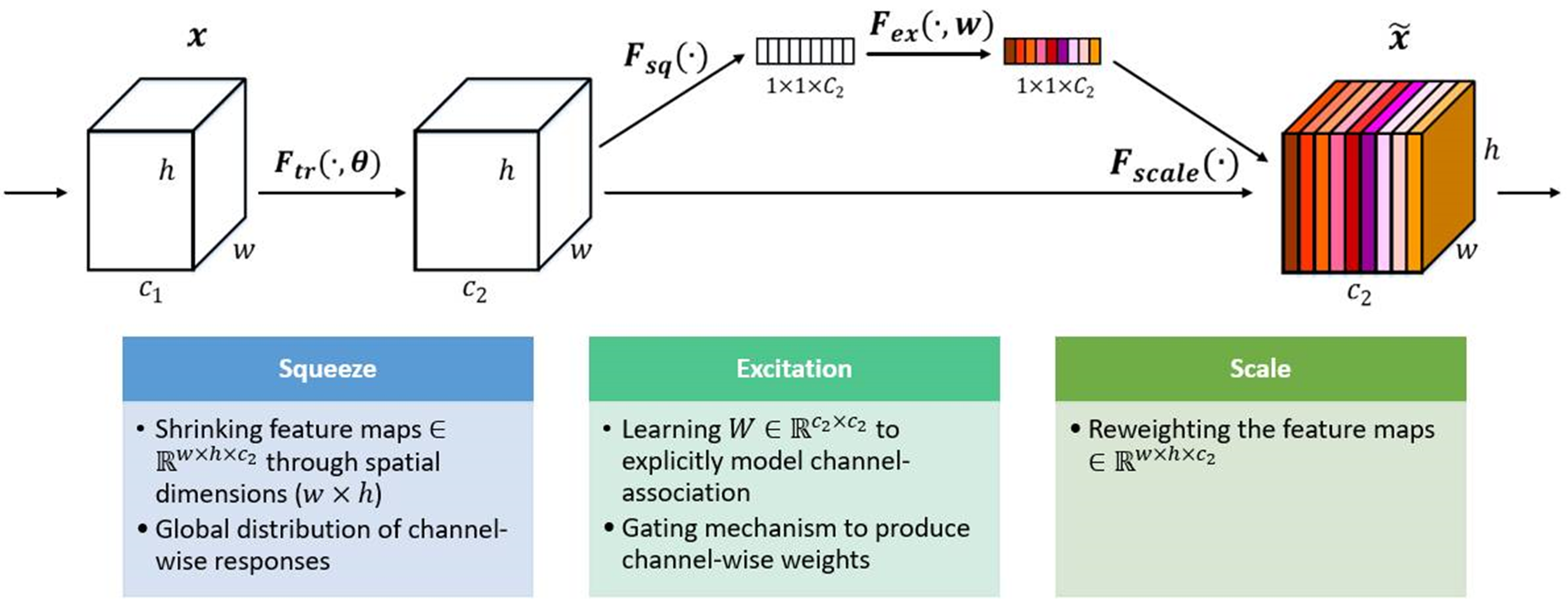
2.2 实现过程:
(1)Squeeze(Fsq):通过全局平均池化,将每个通道的二维特征(H*W)压缩为1个实数,将特征图从 [h, w, c] ==> [1,1,c]
(2)excitation(Fex):给每个特征通道生成一个权重值,论文中通过两个全连接层构建通道间的相关性,输出的权重值数目和输入特征图的通道数相同。[1,1,c] ==> [1,1,c]
(3)Scale(Fscale):将前面得到的归一化权重加权到每个通道的特征上。论文中使用的是乘法,逐通道乘以权重系数。[h,w,c]*[1,1,c] ==> [h,w,c]
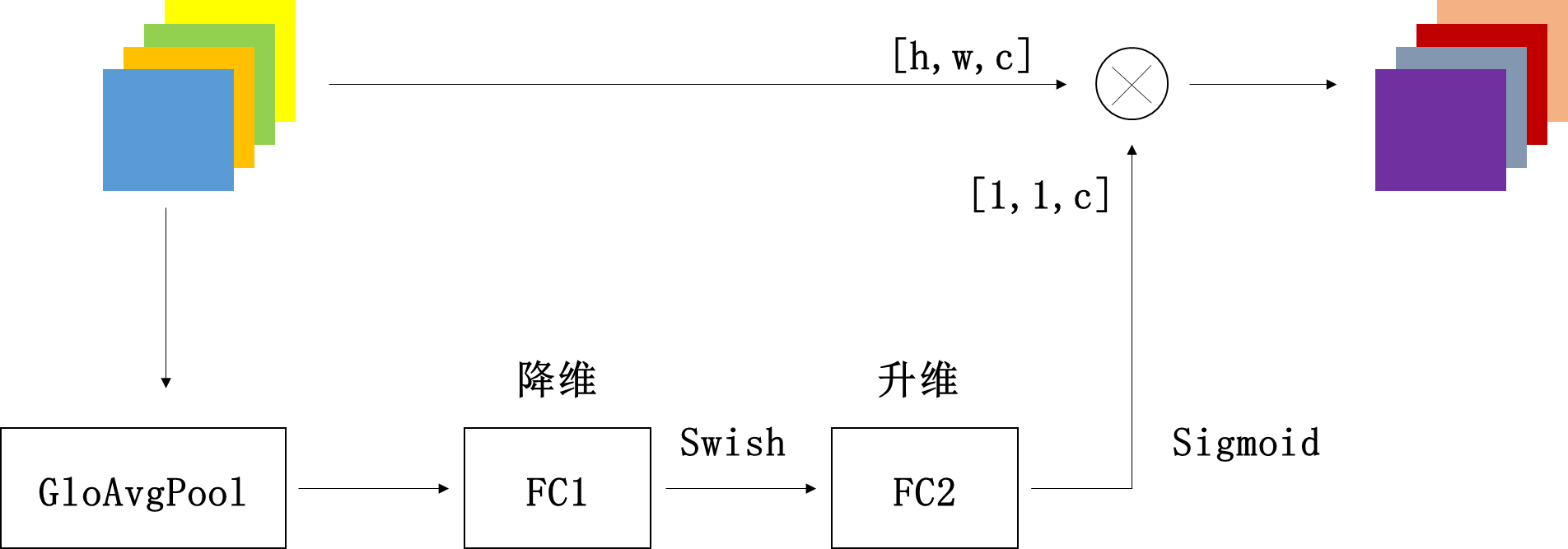
下面我用EfficientNet中的SE注意力机制来说明一下这个流程。
squeeze操作:特征图经过全局平均池化,将特征图压缩成特征向量[1,1,c]
excitation操作:FC1层+Swish激活+FC2层+Sigmoid激活。通过全连接层(FC1),将特征图向量的通道维度降低为原来的1/r,即[1,1,c*1/r];然后经过Swish激活函数;再通过一个全连接层(FC2),将特征图向量的特征图上升回原来[1,1,c];然后经过sigmoid函数转化为一个0-1之间的归一化权重向量。
scale操作:将归一化权重和原输入特征图逐通道相乘,生成加权后的特征图。
小节:
(1)SENet的核心思想是通过全连接网络根据loss损失来自动学习特征权重,而不是直接根据特征通道的数值分配来判断,使有效的特征通道的权重大。当然SE注意力机制不可避免的增加了一些参数和计算量,但性价比还是挺高的。
(2)论文认为excitation操作中使用两个全连接层相比直接使用一个全连接层,它的好处在于,具有更多的非线性,可以更好地拟合通道间的复杂关联。
2.3 代码复现
import tensorflow as tf
from tensorflow.keras import layers, Model, Input# se注意力机制
def se_block(inputs, ratio=4): # ratio代表第一个全连接层下降通道数的系数# 获取输入特征图的通道数in_channel = inputs.shape[-1]# 全局平均池化[h,w,c]==>[None,c]x = layers.GlobalAveragePooling2D()(inputs)# [None,c]==>[1,1,c]x = layers.Reshape(target_shape=(1,1,in_channel))(x)# [1,1,c]==>[1,1,c/4]x = layers.Dense(in_channel//ratio)(x) # 全连接下降通道数# relu激活x = tf.nn.relu(x)# [1,1,c/4]==>[1,1,c]x = layers.Dense(in_channel)(x) # 全连接上升通道数# sigmoid激活,权重归一化x = tf.nn.sigmoid(x)# [h,w,c]*[1,1,c]==>[h,w,c]outputs = layers.multiply([inputs, x]) # 归一化权重和原输入特征图逐通道相乘return outputs # 测试SE注意力机制
if __name__ == '__main__':# 构建输入inputs = Input([56,56,24])x = se_block(inputs) # 接收SE返回值model = Model(inputs, x) # 构建网络模型print(x.shape) # (None, 56, 56, 24)model.summary() # 输出SE模块的结构查看SE模块的结构框架
Model: "model"
__________________________________________________________________________________________________
Layer (type) Output Shape Param # Connected to
==================================================================================================
input_1 (InputLayer) [(None, 56, 56, 24)] 0
__________________________________________________________________________________________________
global_average_pooling2d (Globa (None, 24) 0 input_1[0][0]
__________________________________________________________________________________________________
reshape (Reshape) (None, 1, 1, 24) 0 global_average_pooling2d[0][0]
__________________________________________________________________________________________________
dense (Dense) (None, 1, 1, 6) 150 reshape[0][0]
__________________________________________________________________________________________________
tf.nn.relu (TFOpLambda) (None, 1, 1, 6) 0 dense[0][0]
__________________________________________________________________________________________________
dense_1 (Dense) (None, 1, 1, 24) 168 tf.nn.relu[0][0]
__________________________________________________________________________________________________
tf.math.sigmoid (TFOpLambda) (None, 1, 1, 24) 0 dense_1[0][0]
__________________________________________________________________________________________________
multiply (Multiply) (None, 56, 56, 24) 0 input_1[0][0] tf.math.sigmoid[0][0]
==================================================================================================
Total params: 318
Trainable params: 318
Non-trainable params: 0
__________________________________________________________________________________________________3. ECANet注意力机制
3.1 方法介绍
ECANet是通道注意力机制的一种实现形式,ECANet可以看做是SENet的改进版。
作者表明SENet中的降维会给通道注意力机制带来副作用,并且捕获所有通道之间的依存关系是效率不高的且是不必要的。
ECA注意力机制模块直接在全局平均池化层之后使用1x1卷积层,去除了全连接层。该模块避免了维度缩减,并有效捕获了跨通道交互。并且ECA只涉及少数参数就能达到很好的效果。
ECANet通过一维卷积 layers.Conv1D来完成跨通道间的信息交互,卷积核的大小通过一个函数来自适应变化,使得通道数较大的层可以更多地进行跨通道交互。自适应函数为:,其中
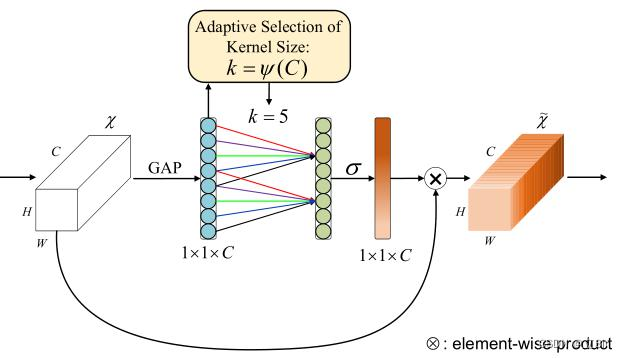
3.2 实现过程
(1)将输入特征图经过全局平均池化,特征图从[h,w,c]的矩阵变成[1,1,c]的向量
(2)计算得到自适应的一维卷积核大小kernel_size
(3)将kernel_size用于一维卷积中,得到对于特征图的每个通道的权重
(4)将归一化权重和原输入特征图逐通道相乘,生成加权后的特征图
3.3 代码实现
import tensorflow as tf
from tensorflow import keras
from tensorflow.keras import Model, layers
import mathdef eca_block(inputs, b=1, gama=2):# 输入特征图的通道数in_channel = inputs.shape[-1]# 根据公式计算自适应卷积核大小kernel_size = int(abs((math.log(in_channel, 2) + b) / gama))# 如果卷积核大小是偶数,就使用它if kernel_size % 2:kernel_size = kernel_size# 如果卷积核大小是奇数就变成偶数else:kernel_size = kernel_size + 1# [h,w,c]==>[None,c] 全局平均池化x = layers.GlobalAveragePooling2D()(inputs)# [None,c]==>[c,1]x = layers.Reshape(target_shape=(in_channel, 1))(x)# [c,1]==>[c,1]x = layers.Conv1D(filters=1, kernel_size=kernel_size, padding='same', use_bias=False)(x)# sigmoid激活x = tf.nn.sigmoid(x)# [c,1]==>[1,1,c]x = layers.Reshape((1,1,in_channel))(x)# 结果和输入相乘outputs = layers.multiply([inputs, x])return outputs# 验证ECA注意力机制
if __name__ == '__main__':# 构造输入层inputs = keras.Input(shape=[26,26,512])x = eca_block(inputs) # 接收ECA输出结果model = Model(inputs, x) # 构造模型model.summary() # 查看网络架构查看ECA模块,和SENet相比大大减少了参数量,参数量等于一维卷积的kernel_size的大小
Model: "model_1"
__________________________________________________________________________________________________
Layer (type) Output Shape Param # Connected to
==================================================================================================
input_2 (InputLayer) [(None, 26, 26, 512) 0
__________________________________________________________________________________________________
global_average_pooling2d_1 (Glo (None, 512) 0 input_2[0][0]
__________________________________________________________________________________________________
reshape_1 (Reshape) (None, 512, 1) 0 global_average_pooling2d_1[0][0]
__________________________________________________________________________________________________
conv1d (Conv1D) (None, 512, 1) 5 reshape_1[0][0]
__________________________________________________________________________________________________
tf.math.sigmoid_1 (TFOpLambda) (None, 512, 1) 0 conv1d[0][0]
__________________________________________________________________________________________________
reshape_2 (Reshape) (None, 1, 1, 512) 0 tf.math.sigmoid_1[0][0]
__________________________________________________________________________________________________
multiply_1 (Multiply) (None, 26, 26, 512) 0 input_2[0][0] reshape_2[0][0]
==================================================================================================
Total params: 5
Trainable params: 5
Non-trainable params: 0
__________________________________________________________________________________________________
![[ 注意力机制 ] 经典网络模型1——SENet 详解与复现](https://img-blog.csdnimg.cn/76f92bb7921e4293800b75d7dcdde90f.png?x-oss-process=image/watermark,type_d3F5LXplbmhlaQ,shadow_50,text_Q1NETiBASG9yaXpvbiBNYXg=,size_14,color_FFFFFF,t_70,g_se,x_16#pic_center)