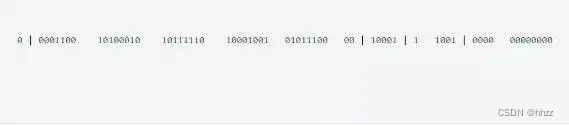
Twitter 于 2010 年开源了内部团队在用的一款全局唯一 ID 生成算法 Snowflake,翻译过来叫做雪花算法。Snowflake 不借助数据库,可直接由编程语言生成,它通过巧妙的位设计使得 ID 能够满足递增属性,且生成的 ID 并不是依次连续的。它连续生成的 3 个 ID 看起来像这样:
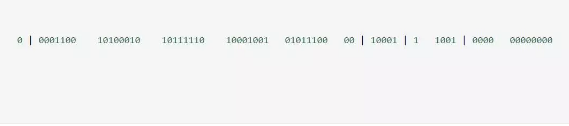
563583455628754944563583466173235200563583552944996352
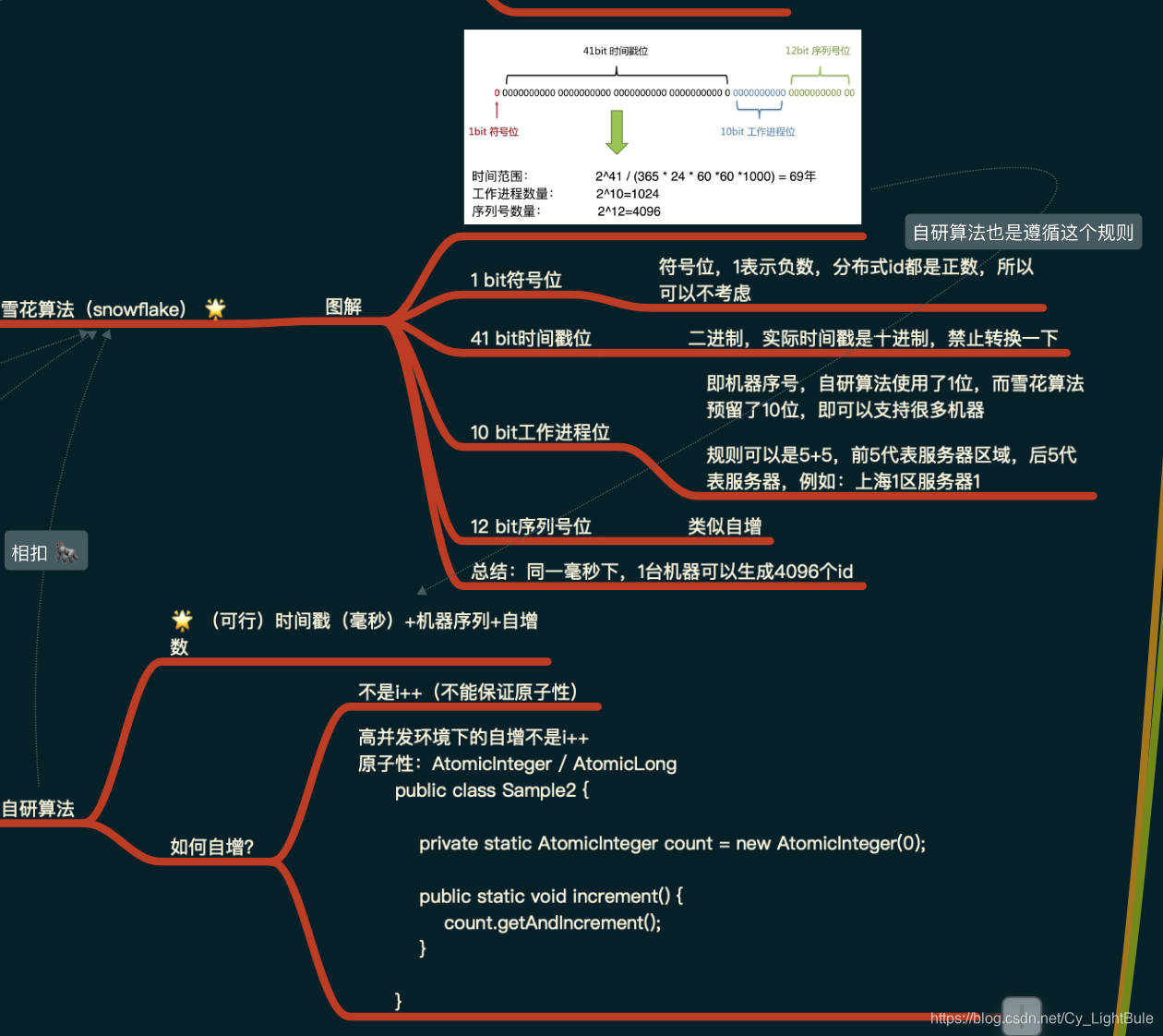
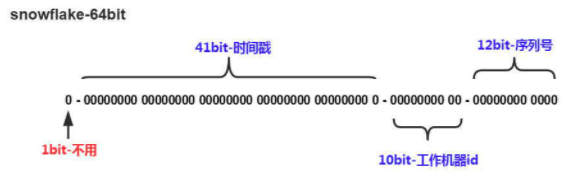
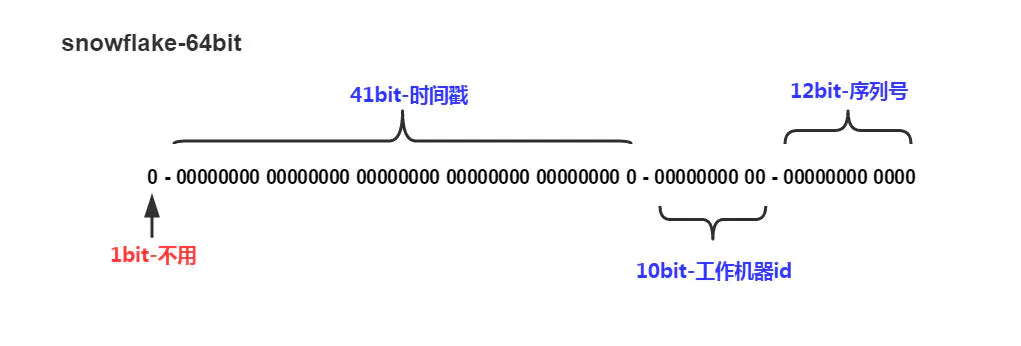
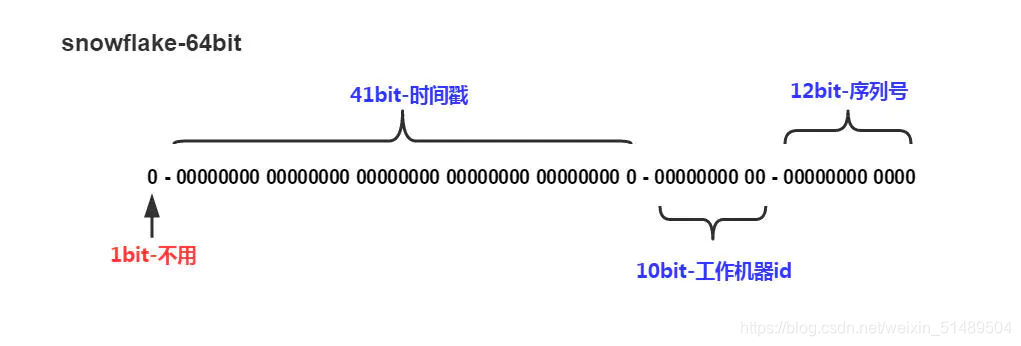
Snowflake 以 64 bit 来存储组成 ID 的4 个部分:
1、最高位占1 bit,值固定为 0,以保证生成的 ID 为正数;
2、中位占 41 bit,值为毫秒级时间戳;
3、中下位占 10 bit,值为工作机器的 ID,值的上限为 1024;
4、末位占 12 bit,值为当前毫秒内生成的不同 ID,值的上限为 4096;

Snowflake 的代码有很多,在此参考并复现了一个,理论上4096 * 1000 毫秒 就是400W 实际上1秒也就100W
import time# 注 机器ID占位5 这也就意味者十进制下编号不能超过31 将机器ID与机房ID合并,最大三个机房即00 10 20 每个机房的数值 + 1 即是机器ID 备用 30 31
WORKER_ID_BITS = 5
SEQUENCE_BITS = 12# 最大取值计算
MAX_WORKER_ID = -1 ^ (-1 << WORKER_ID_BITS)# 移位偏移计算
WORKER_ID_SHIFT = SEQUENCE_BITS
TIMESTAMP_LEFT_SHIFT = SEQUENCE_BITS + WORKER_ID_BITS
# print(WORKER_ID_SHIFT, TIMESTAMP_LEFT_SHIFT)# 序号循环掩码
SEQUENCE_MASK = -1 ^ (-1 << SEQUENCE_BITS)
# print(SEQUENCE_MASK)# 起始时间
TWEPOCH = 1594977661913class IdWorker(object):def __init__(self, worker_id, sequence=0):""":param worker_id: 机房和机器的ID 最大编号可为00 - 31 实际使用范围 00 - 29 备用 30 31:param sequence: 初始码"""if worker_id > MAX_WORKER_ID or worker_id < 0:raise ValueError('worker_id值越界')self.worker_id = worker_idself.sequence = sequenceself.last_timestamp = -1 # 上次计算的时间戳def get_timestamp(self):"""生成毫秒级时间戳:return: 毫秒级时间戳"""return int(time.time() * 1000)def wait_next_millis(self, last_timestamp):"""等到下一毫秒"""timestamp = self.get_timestamp()while timestamp <= last_timestamp:timestamp = self.get_timestamp()return timestampdef get_id(self):""""""timestamp = self.get_timestamp()# 判断服务器的时间是否发生了错乱或者回拨if timestamp < self.last_timestamp:# 如果服务器发生错乱 应该抛出异常# 此处待完善passif timestamp == self.last_timestamp:self.sequence = (self.sequence + 1) & SEQUENCE_MASKif self.sequence == 0:timestamp = self.wait_next_millis(self.last_timestamp)else:self.sequence = 0self.last_timestamp = timestampnew_id = ((timestamp - TWEPOCH) << TIMESTAMP_LEFT_SHIFT) | (self.worker_id << WORKER_ID_SHIFT) | self.sequencereturn new_idif __name__ == '__main__':# 测试效率import datetimeworker = IdWorker(worker_id=1, sequence=0)ids = []start = datetime.datetime.now()for i in range(1000000):new_id = worker.get_id()ids.append(new_id)end = datetime.datetime.now()spend_time = end - startprint(spend_time, len(ids), len(set(ids)))大概就这样,有问题 加Q群1121306638。参考了别人的代码,但是代码都是自己一行行写的不是O(∩_∩)O。