Python 实现雪花算法
雪花算法:雪花算法是一种分布式全局唯一ID,一般不需要过多的深入了解,一般个人项目用不到分布式之类的大型架构,另一方面,则是因为,就算用到市面上很多 ID 生成器帮我们完成了这项工作。
介绍:Twitter 于 2010 年开源了内部团队在用的一款全局唯一 ID 生成算法 Snowflake,翻译过来叫做雪花算法。Snowflake 不借助数据库,可直接由编程语言生成,它通过巧妙的位设计使得 ID 能够满足递增属性,且生成的 ID 并不是依次连续的。
参考文章:https://www.cnblogs.com/oklizz/p/11865750.html
1.原理及介绍
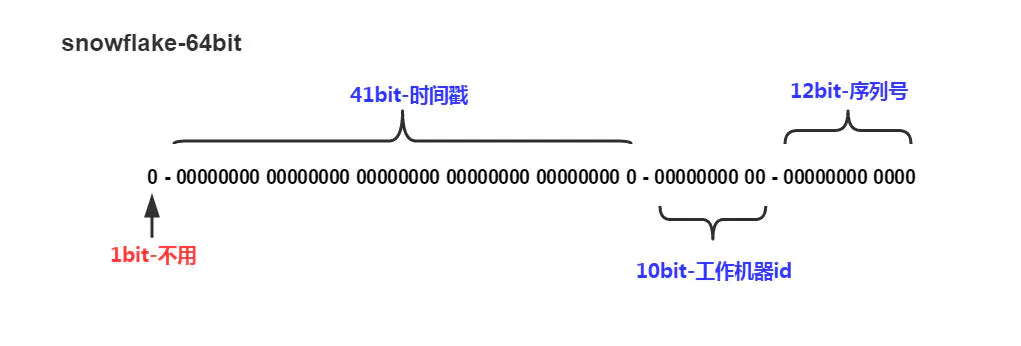
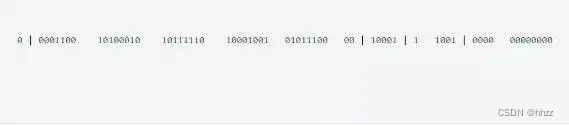
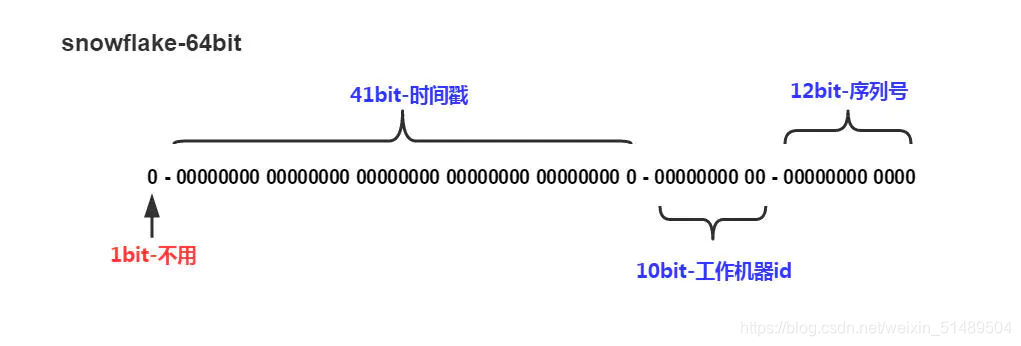
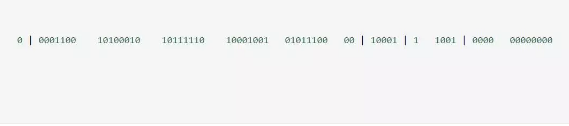
Snowflake 是 Twitter 提出的一个算法,其目的是生成一个64位的整数;
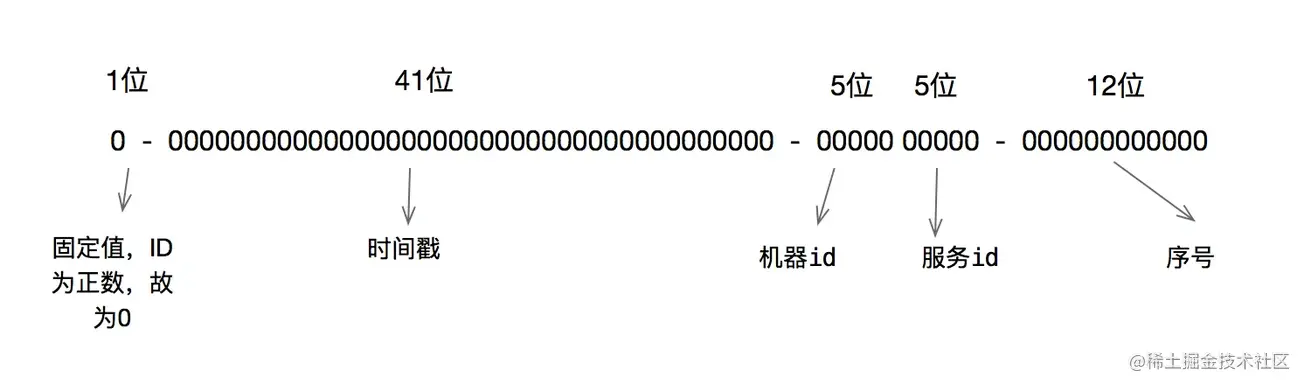
64位的分布图如下图所示:
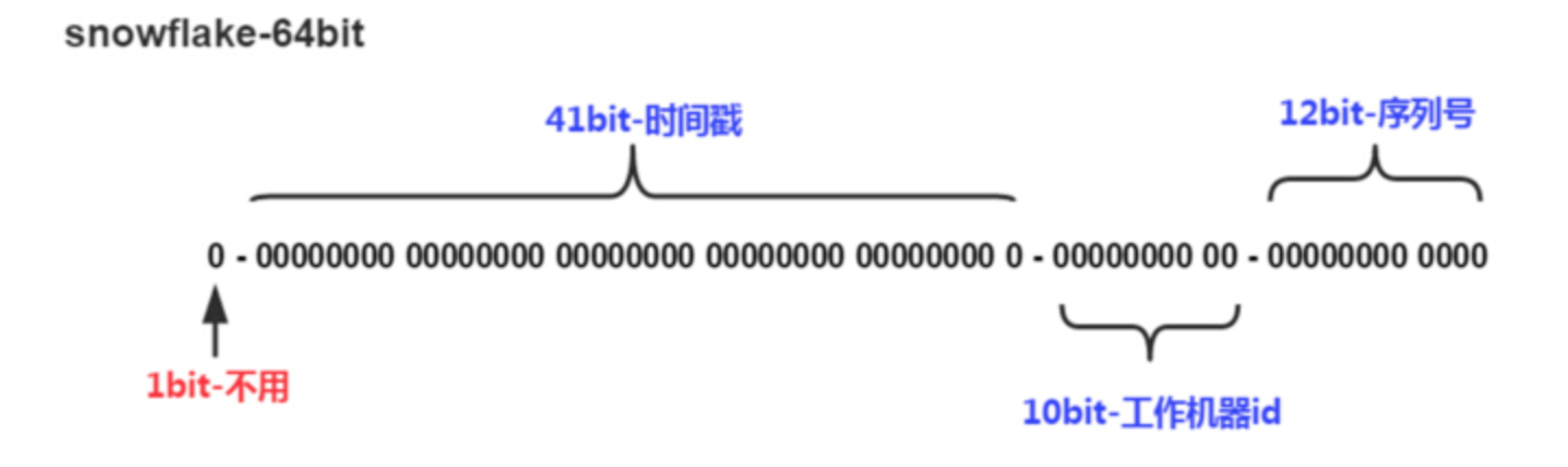
- 1 bit:一般是符号位,不做处理。
- 41bit : 用来记录时间戳,这里可以记录69年,如果设置好起始时间,比如今年是 2022 ,那么可以用到 2091 年,到时候怎么办,这个系统要是能够使用 69 年,估计系统早已经优化过很多次了。
- 10bit : 用来记录机器ID,总共可以记录1024台机器,一般用前5位代表数据中心,后面5位是某个数据中心的机器ID。(注:位数可以根据情况进行设定。)
- 12bit:循环用来对同一个毫秒内产生的不同的 ID,12位可以最多记录4095(212-1)次,多余的需要在下一毫秒进行处理。
上面是一个将64bit划分标准,当然也不一定这么做,可以根据不同的业务的具体场景进行行划分,例如:
服务目前QPS10万,预计几年之内会发展到百万。
当前机器三地部署,上海,北京,深圳都有。
当前机器10台左右,预计未来会增加至百台。
这个时候我们根据上面的场景可以再次合理的划分62 bit,QPS 几年之内会发展到百万,那么每毫秒就是千级的请求,目前 10 台机器那么每台机器承担百级的请求,为了保证扩展,后面的循环位可以限制到 1024,也就是2^10,那么循环位10位就足够了
机器三地部署我们可以用3bit总共8来表示机房位置,当前的机器10台,为了保证扩展到百台那么可以用7bit 128来表示,时间位依然是41bit,那么还剩下64-10-3-7-41-1 = 2bit,还剩下2bit可以用来进行扩展。

时钟回拨:因为机器的原因会发生时间回拨,雪花算法是强依赖时间的,如果发生时间回拨,有可能会发生重复ID,在我们上面的nextId中我们用当前时间和上一次时间进行判断,如果当前时间小于上一次的时间,那么肯定是发生了回拨,算法会直接抛出异常。
2.实现
2.1 知识补充
-
python中为位运算
运算符 描述 实例 << 左移运算符:运算数的各二进位全部左移若干位,
由<<右边的数字指定了移动的位数,高位丢弃(前面无效的0),低位补0.60 << 2 = 240 >> 右移运算符:把 >>左边的的运算数的各二进位全部
右移若干位,运算符右边的数字指定了右移的位数。
低位丢弃(无效的0),高位补0.60>>2 = 15 ^ 按位异或运算符:当两两对应的二进位相异时,结果取1. 01^11 = 10 a = 60 # 60 的二进制位数是: 0011 1100 (111100)print(a << 2) # 0011 1100 左移两位 1111 0000 = 240print(a >> 2) # 0011 1100 右移两位 0000 1111 = 15
# ^ 二进制之间的异或运算,当两值不同的时候为 1. 8 ^ 16 = 24 # 0000 1000 8 # 0001 0000 16 # 0001 1000 24 结果
-
回顾 bin 函数
bin()函数的返回值要从Ob之后开始阅读。
2.2 算法实现
import time
import loggingfrom exceptions import InvalidSystemClock # 继承的Excpetion即可。# 64 位 id 的划分,通常机器位和数据位各为 5 位
WORKER_ID_BITS = 5 # 机器位
DATACENTER_ID_BITS = 5 # 数据位
SEQUENCE_BITS = 12 # 循环位# 最大取值计算,计算机中负数表示为他的补码
MAX_WORKER_ID = -1^(-1 << WORKER_ID_BITS) # 2**5 -1 =31
MAX_DATACENTER_ID = -1 ^(-1 << DATACENTER_ID_BITS)# 移位偏移计算
WORKER_ID_SHIFT = SEQUENCE_BITS
DATACENTER_ID_SHIFT = SEQUENCE_BITS + WORKER_ID_BITS
TIMESTAMP_LEFT_SHIFT = SEQUENCE_BITS + WORKER_ID_BITS + DATACENTER_ID_BITS# X序号循环掩码
SEQUENCE_MASK = -1^(-1 << SEQUENCE_BITS)# Twitter 元年时间戳
TWEPOCH = 1288834974657logger = logging.getLogger('雪花算法')class IdWorker(object):'''用于生成IDS.'''def __init__(self,datacenter_id,worker_id,sequence=0):'''初始化方法:param datacenter_id:数据id:param worker_id:机器id:param sequence:序列码'''if worker_id > MAX_WORKER_ID or worker_id <0:raise ValueError('worker_id 值越界')if datacenter_id >MAX_DATACENTER_ID or datacenter_id < 0:raise ValueError('datacenter_id 值越界')self.worker_id = worker_idself.datacenter_id = datacenter_idself.sequence = sequenceself.last_timestamp = -1 # 上次计算的时间戳def _gen_timestamp(self):'''生成整数时间戳。:return:'''return int(time.time()*1000)def get_id(self):'''获取新的ID.:return:'''# 获取当前时间戳timestamp = self._gen_timestamp()# 时钟回拨的情况if timestamp < self.last_timestamp:logging.error('clock is moving backwards. Rejecting requests util {}'.format(self.last_timestamp))raise InvalidSystemClockif timestamp == self.last_timestamp:# 同一毫秒的处理。self.sequence = (self.sequence+1) & SEQUENCE_MASKif self.sequence == 0:timestamp =self._til_next_millis(self.last_timestamp)else:self.sequence = 0self.last_timestamp =timestampnew_id = (((timestamp - TWEPOCH) << TIMESTAMP_LEFT_SHIFT)|(self.datacenter_id << DATACENTER_ID_SHIFT)|(self.worker_id << WORKER_ID_SHIFT))|self.sequencereturn new_iddef _til_next_millis(self,last_timestamp):'''等到下一毫秒。:param last_timestamp::return:'''timestamp = self._gen_timestamp()while timestamp <= last_timestamp:timestamp = self._gen_timestamp()return timestampif __name__ == '__main__':worker = IdWorker(1,2,0)print(worker.get_id())
2.3 第三方包的使用
pip install pysnowflake
启动服务
snowflake_start_server --worker=1

编写程序,获取id
from snowflake import clientprint(client.get_guid())

继续努力,终成大器!