1 前言
在深度学习领域,CNN分类网络的发展对其它计算机视觉任务如目标检测和语义分割都起到至关重要的作用,因为检测和分割模型通常是构建在CNN分类网络(称为backbone)之上。提到CNN分类网络,我们所熟知的是VGG,ResNet,Inception,DenseNet等模型,它们的效果已经被充分验证,而且被广泛应用在各类计算机视觉任务上。这里我们介绍一篇CVPR2017的文章SENet,它赢得了最后一届ImageNet 2017竞赛分类任务的冠军。重要的一点是SENet思路很简单,很容易扩展在已有网络结构中。
2 结构和原理
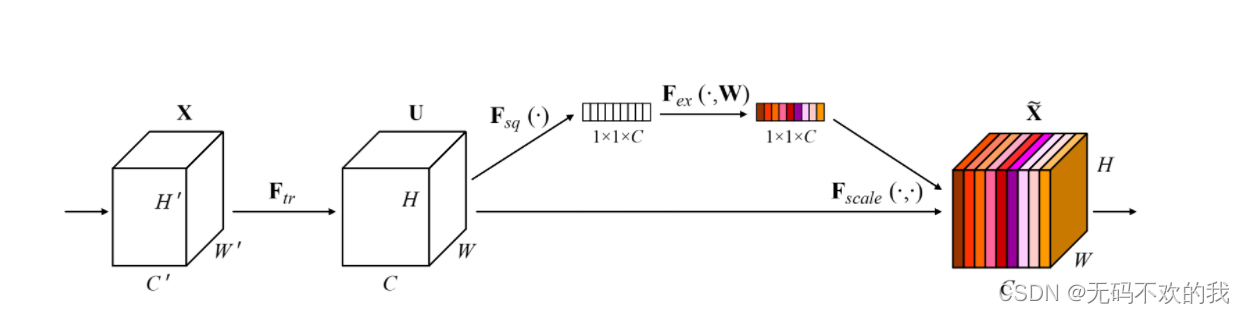
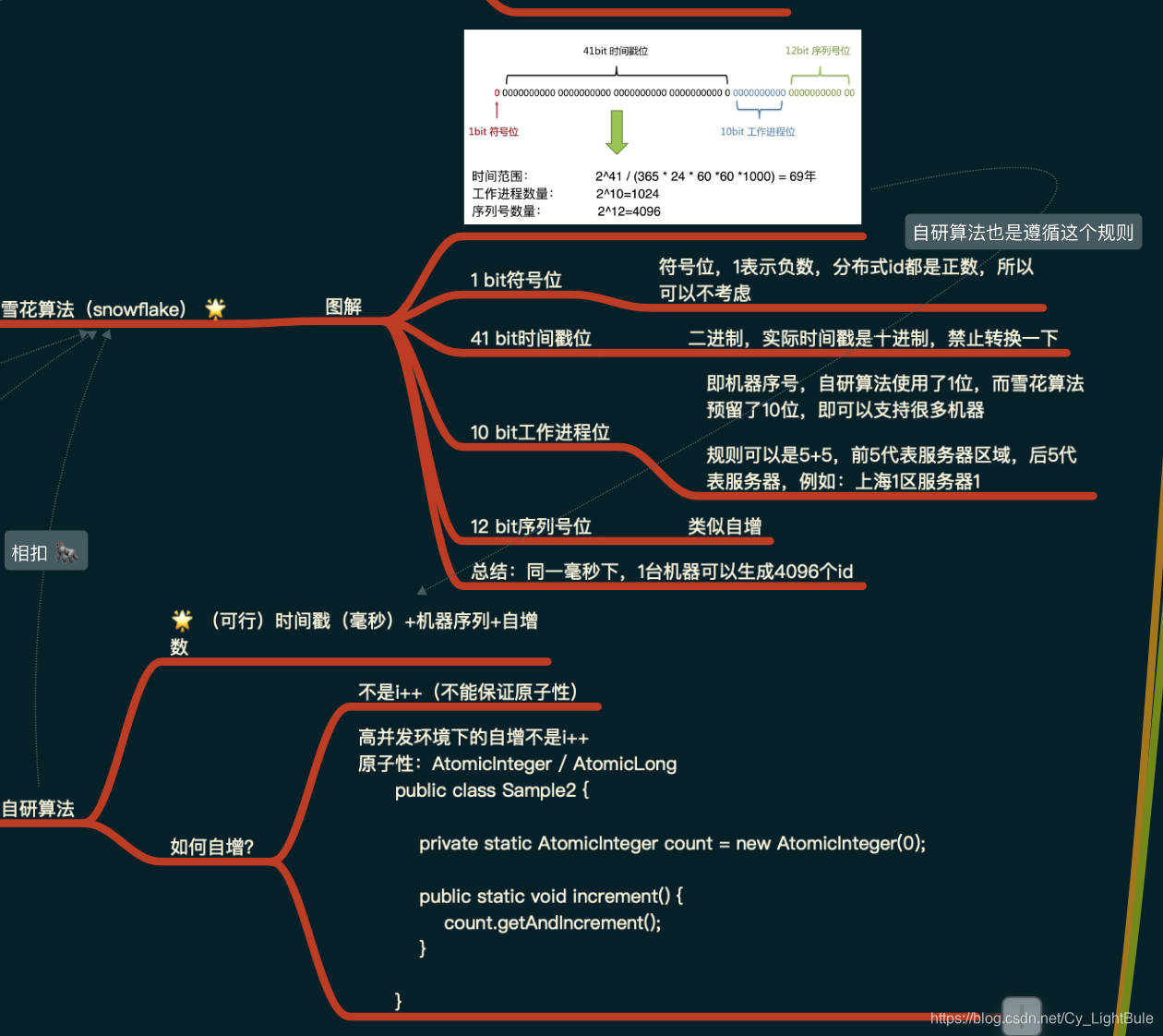
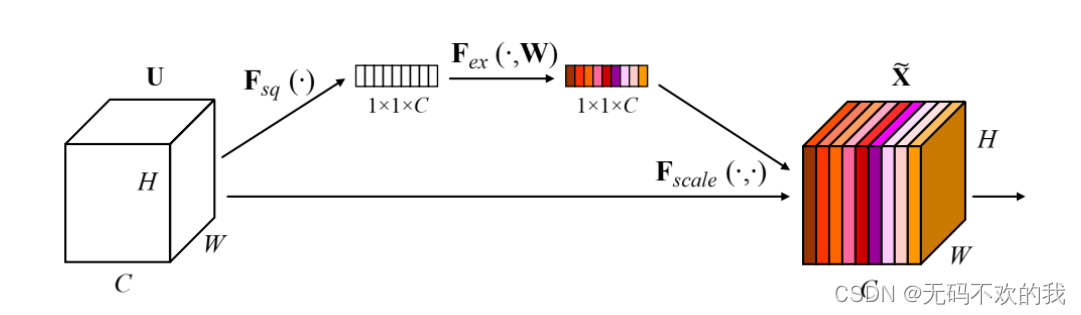
上图是SENet中的SE模块 (SE module ),图中的Ftr是传统的卷积结构,X和U是Ftr的输入(C’xH’xW’)和输出(CxHxW),这些都是以往结构中已存在的。SENet增加的部分是U后的结构:对U先做一个Global Average Pooling(图中的Fsq(.),作者称为Squeeze过程),输出的1x1xC数据再经过两级全连接(图中的Fex(.),作者称为Excitation过程),最后用sigmoid(论文中的self-gating mechanism)限制到[0,1]的范围,把这个值作为scale乘到U的C个通道上, 作为下一级的输入数据。这种结构的原理是想通过控制scale的大小,把重要的特征增强,不重要的特征减弱,从而让提取的特征指向性更强。下面来看下SENet的一些细节:先是Squeeze部分。GAP有很多算法,作者用了最简单的求平均的方法(公式1),将空间上所有点的信息都平均成了一个值。这么做是因为最终的scale是对整个通道作用的,这就得基于通道的整体信息来计算scale。另外作者要利用的是通道间的相关性,而不是空间分布中的相关性,用GAP屏蔽掉空间上的分布信息能让scale的计算更加准确。
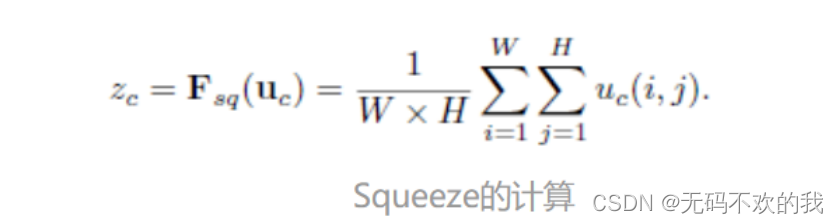
Excitation部分是用2个全连接来实现 ,第一个全连接把C个通道压缩成了C/r个通道来降低计算量(后面跟了RELU),第二个全连接再恢复回C个通道(后面跟了Sigmoid),r是指压缩的比例。作者尝试了r在各种取值下的性能 ,最后得出结论r=16时整体性能和计算量最平衡。
为什么要加全连接层呢?这是为了利用通道间的相关性来训练出真正的scale。一次mini-batch个样本的squeeze输出并不代表通道真实要调整的scale值,真实的scale要基于全部数据集来训练得出,而不是基于单个batch,所以后面要加个全连接层来进行训练。可以拿SE module 和下面3种错误的结构比较来进一步理解:
错误1:
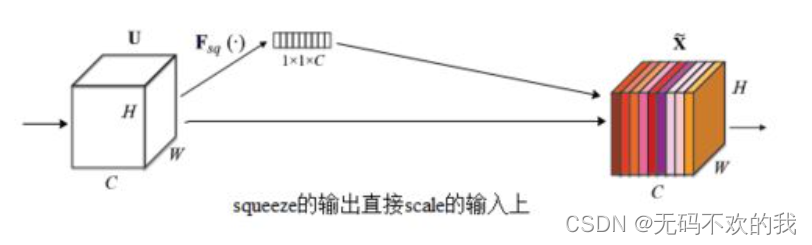
如下图所示,squeeze的输出直接scale到输入上,没有了全连接层,某个通道的调整值完全基于单个通道GAP的结果,事实上只有GAP的分支是完全没有反向计算、没有训练的过程的,就无法基于全部数据集来训练得出通道增强、减弱的规律。
错误2:
下图是经典的卷积结构,有人会说卷积训练出的权值就含有了scale的成分在里面,也利用了通道间的相关性,为啥还要多个SE module ?那是因为这种卷积有空间的成分在里面,为了排除空间上的干扰就得先用GAP压缩成一个点后再作卷积,压缩后因为没有了Height、Width的成分,这种卷积就是全连接了。

错误3:
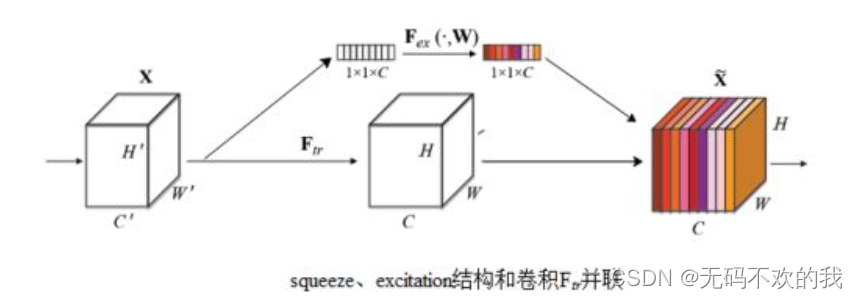
下图中,SE模块和传统的卷积间采用并联而不是串联的方式,这时SE利用的是X(即Ftr的输入)的相关性来计算scale,X和U(即Ftr的输出)的相关性是不同的,把根据X的相关性计算出的scale应用到U上明显不合适。
3 网络构建
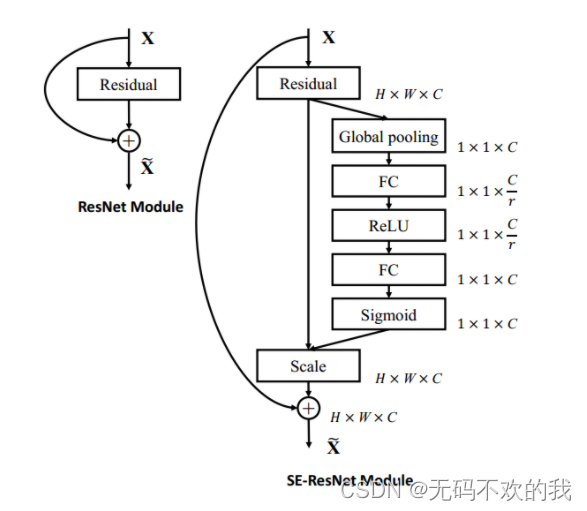
SE模块的灵活性在于它可以直接应用现有的网络结构中。这里以Inception和ResNet为例。对于Inception网络,没有残差结构,这里对整个Inception模块应用SE模块。对于ResNet,SE模块嵌入到残差结构中的残差学习分支中。具体如下图所示:
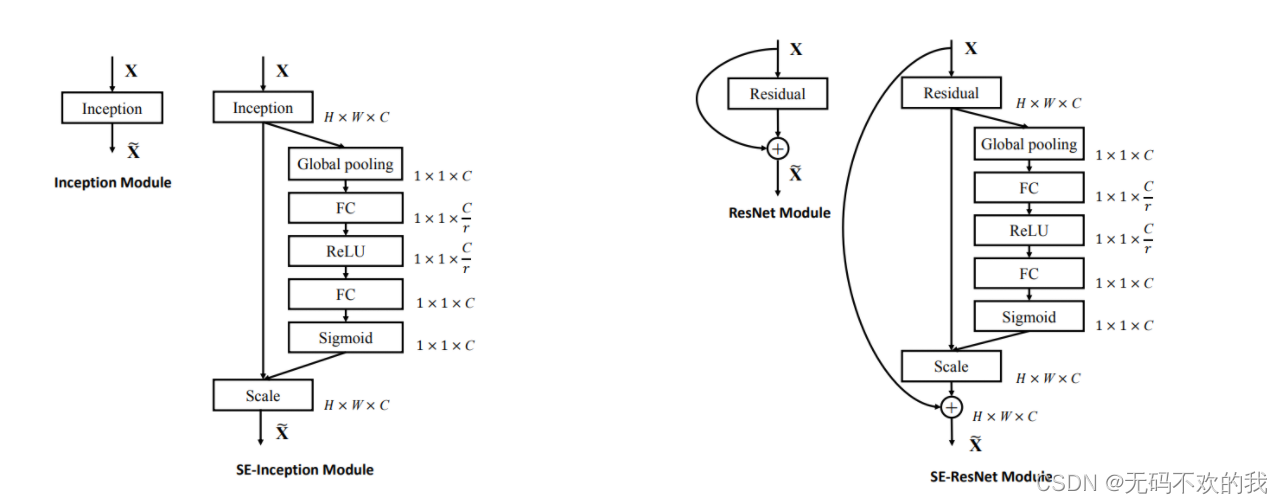
注意事项:
- r是指压缩的比例,根据论文中的实验,当r=16时整体性能和计算量最平衡。
- 根据原论文的说明,SE模块嵌入到残差结构中时,它的FC层不需要偏置,否则会影响通道之间的依赖性
- SE module也称为 SE Block,它们都是SE 模块。并且在后面的代码实现中,我们称其为SE layer,它们都指的是同一个内容。
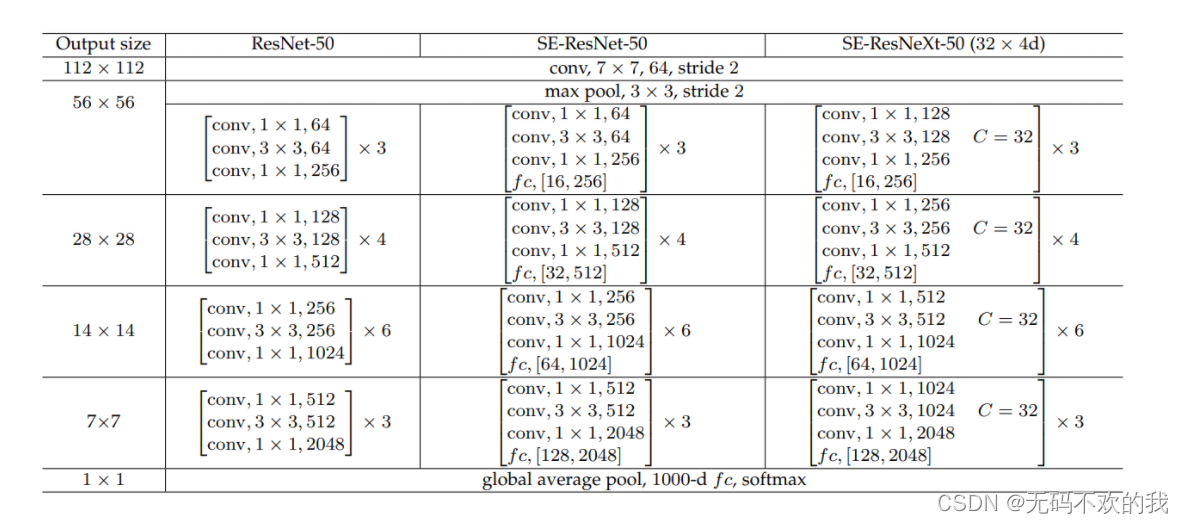
同样地,SE模块也可以应用在其它网络结构,如ResNetXt,Inception-ResNet,MobileNet和ShuffleNet中。这里给出SE-ResNet-50和SE-ResNetXt-50的具体结构,如下表所示:
对比结构图发现,仅需更改ResNet当中的每一个 残差块后面增加 一个SE module即可,即下面中的fc结构
增加了SE模块后,模型参数以及计算量都会增加,这里以SE-ResNet-50为例,对于模型参数增加量为:
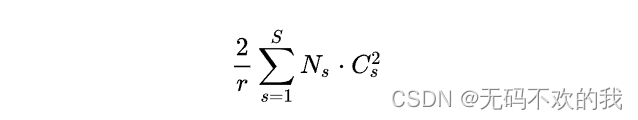
其中r为压缩比例,S表示stage数量, C s C_s Cs为第s个stage的通道数, N s N_s Ns为第s个stage的重复block量。当r=16时,SE-ResNet-50只增加了约10%的参数量。但计算量(GFLOPs)却增加不到1%。
注意事项:
FLOFS (floating point operations per second ,每秒浮点运算次数) 用于衡量硬件设备的运算速度
FLOFs (floating- point operations ,浮点运算次数) 用于衡量模型计算复杂度
4 模型效果
SE模块很容易嵌入到其它网络中,作者为了验证SE模块的作用,在其它流行网络如ResNet和VGG中引入SE模块,测试其在ImageNet上的效果,如下表所示:
其中original所对应两列数据是 之前的论文中给出的精度,re-implementation所对应两列数据是 本SENet论文作者复现之前的论文后给出的精度,SENet所对应两列数据是加入SE模块后得到的精度。
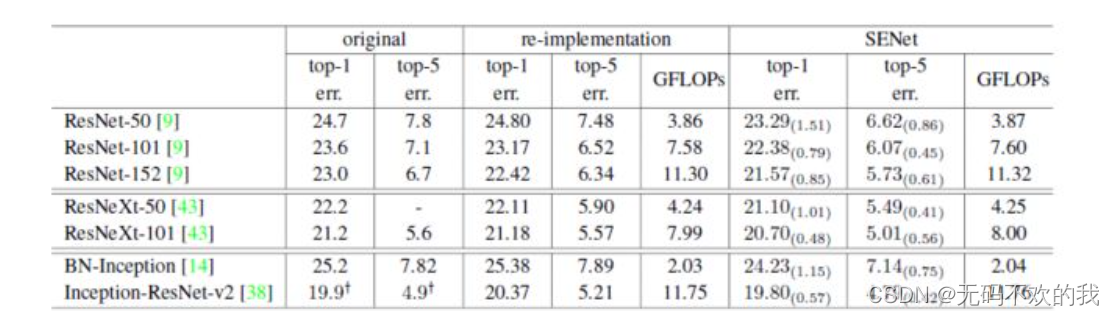
由上面分析可知,SENet复现之前的论文中,google系列复现的精度均比原始论文给出的差,resnet系列复现的精度与原始论文给出的结果差不多。
可以看到所有网络在加入SE模块后分类准确度均有一定的提升。此外,作者还测试了SE模块在轻量级网络MobileNet和ShuffleNet上的效果,如下表所示,可以看到也是有效果提升的。

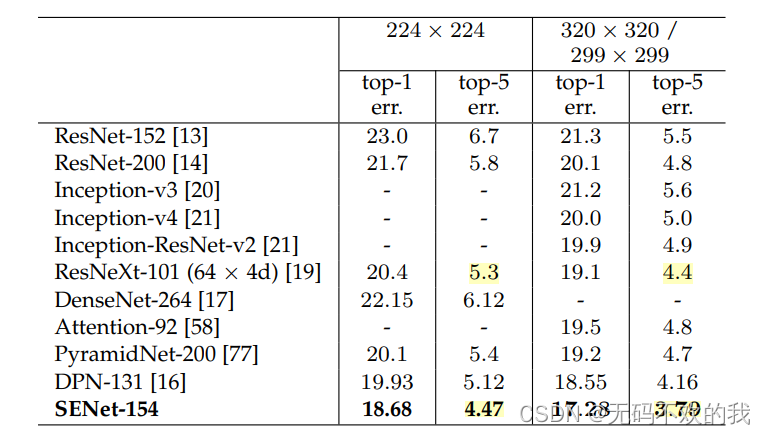
最终作者采用了一系列的SENet进行集成,在ImageNet测试集上的top-5 error为2.251%,赢得了2017年竞赛的冠军。其中最关键的模型是SENet-154,其建立在ResNeXt模型基础上,效果如下表所示:
5 代码实现
下面我们来实现SE-ResNet的代码,它其实与ResNet的代码基本是相同的,只是在每一个 残差块后面增加 一个SE module即可,其它完全一样
5.1 SE模块的实现
# SE模块在 这里称为 SE layer
class SELayer(nn.Module):def __init__(self, channel, reduction=16):super(SELayer, self).__init__()self.avg_pool = nn.AdaptiveAvgPool2d(1) # 这里的参数1 表示经过全局平均池化后,特征图变成1x1大小self.fc = nn.Sequential(nn.Linear(channel, channel // reduction, bias=False),nn.ReLU(inplace=True),nn.Linear(channel // reduction, channel, bias=False),nn.Sigmoid())def forward(self, x):b, c, _, _ = x.size()# self.avg_pool(x)输出的尺寸是[b,c,1,1],由于全连接层的输入必须是二维向量,所以这里需要进行vie()操作:[b,c,1,1]——>[b,c]y = self.avg_pool(x).view(b, c) #经过全连接层后再重新将二维张量变成四维张量,以便于后续的卷积操作y = self.fc(y).view(b, c, 1, 1) return x * y.expand_as(x)
5.2 将SE模块嵌入残差模块
在讲ResNet时,我们知道,它的残差模块包含两种类型:BasicBlock(基础模块)和Bottleneck(瓶颈模块),如下图所示
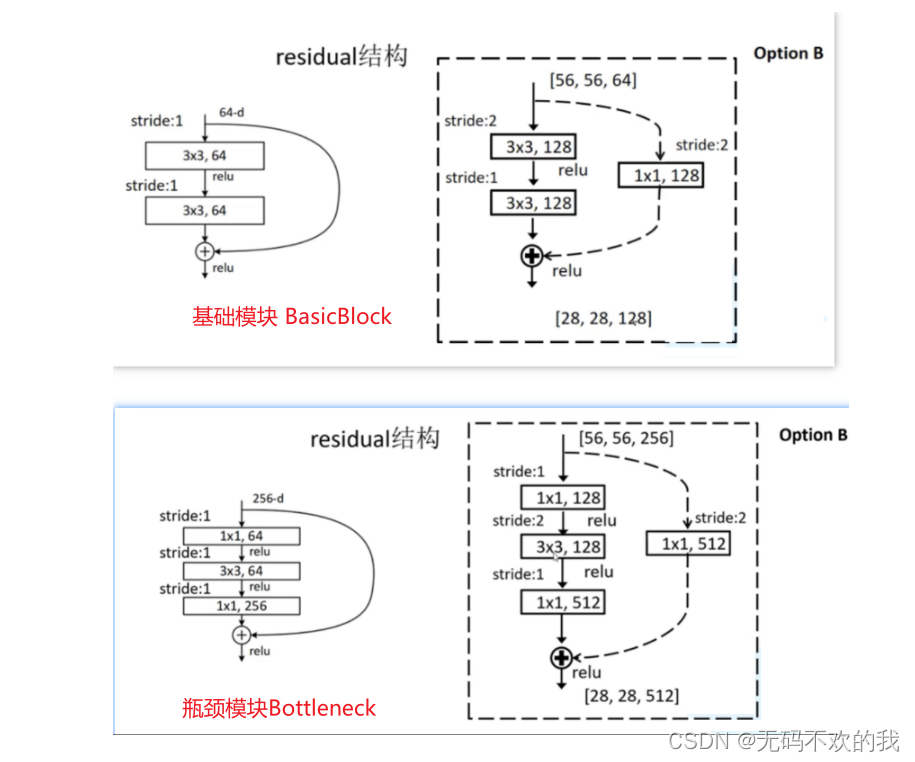
这里我们将SE模块分别嵌入ResNet的BasicBlock和Bottleneck中,得到 SEBasicBlock和SEBottleneck,分别用于构建SE-ResNet18/34和SE-ResNet50/101/150代码如下所示:
def conv3x3(in_planes, out_planes, stride=1):return nn.Conv2d(in_planes, out_planes, kernel_size=3, stride=stride, padding=1, bias=False)class SEBasicBlock(nn.Module):expansion = 1def __init__(self, inplanes, planes, stride=1, downsample=None, *, reduction=16):# 参数列表里的 * 星号,标志着位置参数的就此终结,之后的那些参数,都只能以关键字形式来指定。super(SEBasicBlock, self).__init__()self.conv1 = conv3x3(inplanes, planes, stride)self.bn1 = nn.BatchNorm2d(planes)self.relu = nn.ReLU(inplace=True)self.conv2 = conv3x3(planes, planes, 1)self.bn2 = nn.BatchNorm2d(planes)self.se = SELayer(planes, reduction)self.downsample = downsampleself.stride = stridedef forward(self, x):residual = xout = self.conv1(x)out = self.bn1(out)out = self.relu(out)out = self.conv2(out)out = self.bn2(out)out = self.se(out)if self.downsample is not None:residual = self.downsample(x)out += residualout = self.relu(out)return outclass SEBottleneck(nn.Module):expansion = 4def __init__(self, inplanes, planes, stride=1, downsample=None, *, reduction=16):# 参数列表里的 * 星号,标志着位置参数的就此终结,之后的那些参数,都只能以关键字形式来指定。super(SEBottleneck, self).__init__()self.conv1 = nn.Conv2d(inplanes, planes, kernel_size=1, bias=False)self.bn1 = nn.BatchNorm2d(planes)self.conv2 = nn.Conv2d(planes, planes, kernel_size=3, stride=stride,padding=1, bias=False)self.bn2 = nn.BatchNorm2d(planes)self.conv3 = nn.Conv2d(planes, planes * 4, kernel_size=1, bias=False)self.bn3 = nn.BatchNorm2d(planes * 4)self.relu = nn.ReLU(inplace=True)self.se = SELayer(planes * 4, reduction)self.downsample = downsampleself.stride = stridedef forward(self, x):residual = xout = self.conv1(x)out = self.bn1(out)out = self.relu(out)out = self.conv2(out)out = self.bn2(out)out = self.relu(out)out = self.conv3(out)out = self.bn3(out)out = self.se(out)if self.downsample is not None:residual = self.downsample(x)out += residualout = self.relu(out)return out
5.3 SE-ResNet网络搭建
这一步的代码和ResNet网络搭建完全相同,所以这里直接使用pytorch官方实现的ResNet网络搭建代码
from torchvision.models import ResNet
5.4 构建不同层网络
- se_resnet -18
def se_resnet18(num_classes=1_000):model = ResNet(SEBasicBlock, [2, 2, 2, 2], num_classes=num_classes)return model
- se_resnet -34
def se_resnet18(num_classes=1_000):model = ResNet(SEBasicBlock, [3, 4, 6, 3], num_classes=num_classes)return model
- se_resnet -50
def se_resnet18(num_classes=1_000,pretrained=False):model = ResNet(SEBottleneck, [3, 4, 6, 3], num_classes=num_classes)return model
- se_resnet -101
def se_resnet18(num_classes=1_000):model = ResNet(SEBottleneck, [3, 4, 23, 3], num_classes=num_classes)return model
- se_resnet -152
def se_resnet18(num_classes=1_000):model = ResNet(SEBottleneck, [3, 8, 36, 3], num_classes=num_classes)return model
5.5 实例化se_resnet -50
se_resnet50_model = se_resnet50()fake_data = torch.randn((2, 3, 224, 224)) outputs = se_resnet50_model(fake_data)print(outputs.shape)#输出结果torch.Size([2, 1000])
参考:
https://zhuanlan.zhihu.com/p/32702350
https://zhuanlan.zhihu.com/p/65459972


![[ 注意力机制 ] 经典网络模型1——SENet 详解与复现](https://img-blog.csdnimg.cn/76f92bb7921e4293800b75d7dcdde90f.png?x-oss-process=image/watermark,type_d3F5LXplbmhlaQ,shadow_50,text_Q1NETiBASG9yaXpvbiBNYXg=,size_14,color_FFFFFF,t_70,g_se,x_16#pic_center)