随便聊聊
哈喽,大家好,最近换了份工作,虽然后端技术栈是老了点,但是呢,这边的前端技术确是现在市面上最新的那一套技术:Vue3+Vite+TSX+Pina+Element-Plus+NativeUI。我本人主要是学后端的,确被拉去做前端。唉(人生无常,大肠包小肠!)
但是呢,最近经常听到同事们一直在聊雪花算法,下面来,我们来聊聊雪花算法,是的
分布式ID
聊之前先说一下什么是分布式ID,抛砖引玉
假设现在有一个订单系统被部署在了A、B两个节点上,那么如何在这两个节点上各自生成订单ID,且ID值不能重复呢?
即在分布式系统中,如何在各个不同的服务器上产生唯一的ID值?
通常有以下三种方案:
- 利用数据库的自增特性,不同节点直接使用相同数据库的自增ID;
- 利用UUID算法产生ID值;
- 使用雪花算法产生ID值
虽然Java提供了对UUID的支持,使用UUID.randomUUID()即可,但是由于UUID是一串随机的36位字符串,由32个数字和字母混合的字符串和4个“-”组成,长度过长且业务可读性差,无法有序递增,所以一般不用,更多使用的是雪花算法
由来
为什么叫雪花算法?
雪花算法的由来有两种说法:
- 第一种,Twitter使用scala语言开源了一种分布式id生成算法—SnowFlake算法,被翻译成了雪花算法;
- 第二种,因为自然界中并不存在两片完全一样的雪花的,每一片雪花都拥有自己漂亮独特的形状、独一无二。雪花算法也表示生成的ID如雪花般独一无二。
组成
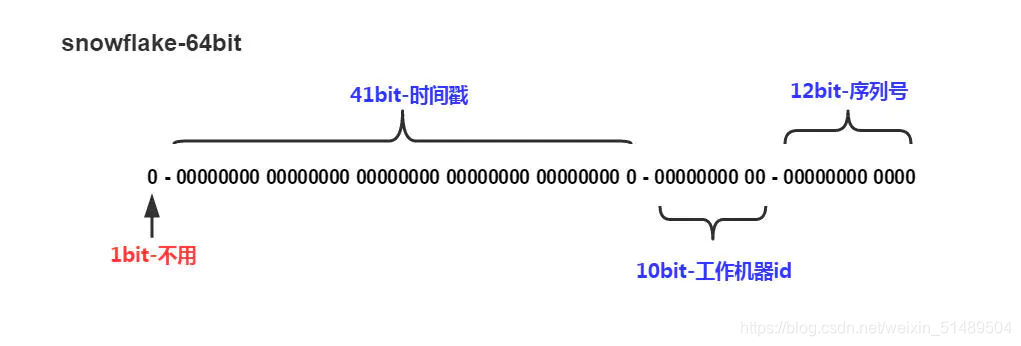
雪花算法生成的ID到底长啥样?
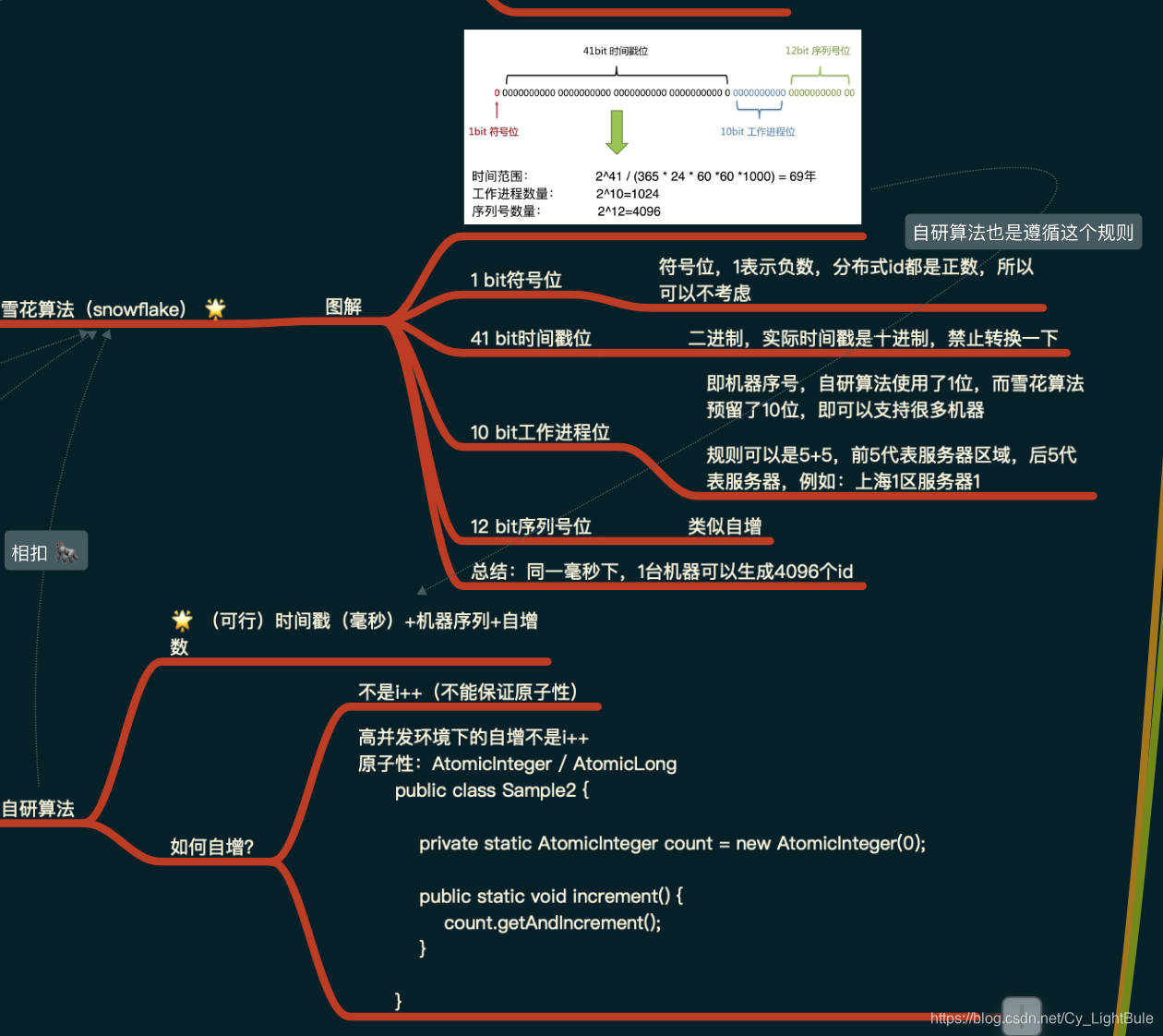
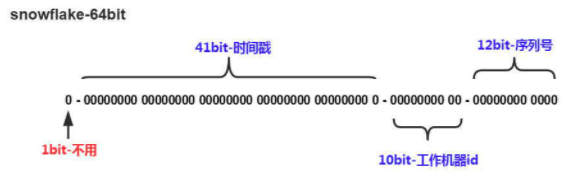
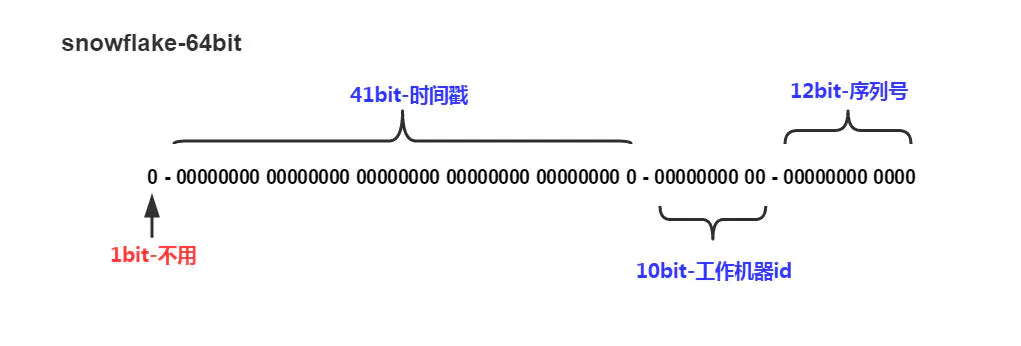
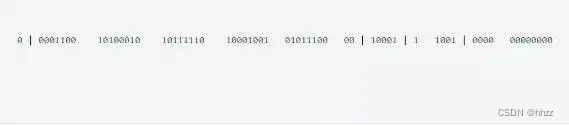
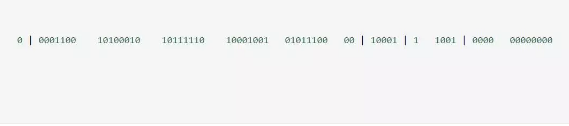
雪花算法生成的ID是一个64bit的long型的数字且按时间趋势递增。大致由首位无效符、时间戳差值、机器编码,序列号四部分组成。

如图:
- 首位无效符:第一个bit作为符号位,因为我们生成的都是正数,所以第一个bit统一都是0;
- 时间戳:占用41bit,精确到毫秒。41位最好可以表示2^41-1毫秒,转换成单位年为69年;
- 机器编码:占用10bit,其中高位5bit是数据中心ID,低位5bit是工作节点ID,最多可以容纳1024个节点;
- 序列号:占用12bit,每个节点每毫秒0开始不断累加,最多可以累加到4095,一共可以产生4096个ID
代码
/*** 雪花算法* @author Fang Ruichuan* @date 2022-11-28 21:24*/
public class SnowFlake {private long workerId;private long dataCenterId;// 每毫秒生产的序列号之从0开始递增private long sequence = 0L;// 1288834974657L是1970-01-01 00:00:00到2010年11月04日01:42:54所经过的毫秒数;// 因为现在二十一世纪的某一时刻减去1288834974657L的值,正好在2^41内。// 因此1288834974657L实际上就是为了让时间戳正好在2^41内而凑出来的。// 简言之,1288834974657L(即1970-01-01 00:00:00),就是在计算时间戳时用到的“起始时间”。private long twePoch = 1288834974657L;private long workerIdBits = 5L;private long datacenterIdBits = 5L;private long maxWorkerId = -1L ^ (-1L << workerIdBits);private long maxDatacenterId = -1L ^ (-1L << datacenterIdBits);private long sequenceBits = 12L;private long workerIdShift = sequenceBits;private long datacenterIdShift = sequenceBits + workerIdBits;private long timestampLeftShift = sequenceBits + workerIdBits + datacenterIdBits;private long sequenceMask = -1L ^ (-1L << sequenceBits);private long lastTimestamp = -1L;public SnowFlake(long datacenterId, long workerId) {if ((datacenterId > maxDatacenterId || datacenterId < 0)|| (workerId > maxWorkerId || workerId < 0)) {throw new IllegalArgumentException("datacenterId/workerId值非法");}this.dataCenterId = datacenterId;this.workerId = workerId;}// 通过SnowFlake生成id的核心算法public synchronized long nextId() {long timestamp = Clock.systemUTC().millis();if (timestamp < lastTimestamp) {throw new RuntimeException("时间戳值非法");}// 如果此次生成id的时间戳,与上次的时间戳相同,就通过机器码和序列号区// 分id值(机器码已通过构造方法传入)if (lastTimestamp == timestamp) {/*下一条语句的作用是:通过位运算保证sequence不会超出序列号所能容纳的最大值。例如,本程序产生的12位sequence值依次是:1、2、3、4、...、4094、4095(4095是2的12次方的最大值,也是本sequence的最大值)那么此时如果再增加一个sequence值(即sequence + 1),下条语句就会使sequence恢复到0。即如果sequence==0,就表示sequence已满。*/sequence = (sequence + 1) & sequenceMask;// 如果sequencce已满,就无法再通过sequence区分id值:因此需要切换到if (sequence == 0) {timestamp = tilNextMillis(lastTimestamp);}} else {// 如果此次生成id的时间戳,与上次的时间戳不同,就已经可以根据时间戳区分id值sequence = 0L;}// 更新最近一次次生成id的时间戳lastTimestamp = timestamp;/**** 假设此刻的值是(二进制表示):* 41位时间戳的值是:00101011110101011101011101010101111101011* 5位datacenterId(机器码的前5位)的值是:01101* 5位workerId(机器码的后5位)的值是:11001* sequence的值是:01001* 那么最终生成的id值,就需要:* 1.将41位时间戳左移动22位(即移动到snowflake值中时间戳应该出现的位置);* 2.将5位datacenterId向左移动17位,并将5位workerId向左移动12位* (即移动到snowflake值中机器码应该出现的位置);* 3.sequence本来就在最低位,因此不需要移动。* 以下<<和|运算,实际就是将时间戳、机器码和序列号移动到snowflake中相应的位置。* @return long*/return ((timestamp - twePoch) << timestampLeftShift)| (dataCenterId << datacenterIdShift) | (workerId << workerIdShift)| sequence;}private long tilNextMillis(long lastTimestamp) {long timestamp = Clock.systemUTC().millis();// 如果当时时刻的时间戳 <= 上一次生成id的时间戳,就重新生成当前时间;// 即确保当前时刻的时间戳,与上一次的时间戳不会重复while (timestamp <= lastTimestamp) {timestamp = Clock.systemUTC().millis();}return timestamp;}// 测试1秒能够生成的id个数public static void generateIdsInOneSecond() {SnowFlake idWorker = new SnowFlake(1, 1);long start = Clock.systemUTC().millis();int i = 0;for (; Clock.systemUTC().millis() - start < 1000; i++) {idWorker.nextId();}long end = Clock.systemUTC().millis();System.out.println("耗时:" + (end - start));System.out.println("生成id个数:" + i);}public static void main(String[] args) {generateIdsInOneSecond();}
}
测试结果:
耗时:1000
生成id个数:4082481