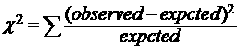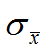关联规则的概念
1、关联规则概念
借用一个引例来介绍关联规则挖掘[1]。
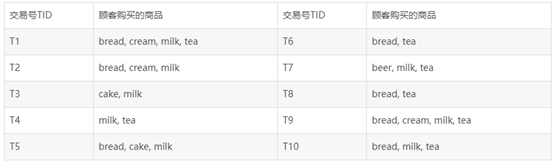
某超市销售记录
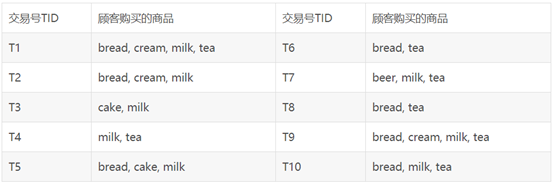
定义一:设I={i1,i2,…,im},是m个不同的项目的集合,每个ik称为一个项目。项目的集合I称为项集。其元素的个数称为项集的长度,长度为k的项集称为k-项集。引例中每个商品就是一个项目,项集为I={bread, beer, cake,cream, milk, tea},I的长度为6。
定义二:每笔交易T是项集I的一个子集。对应每一个交易有一个唯一标识交易号,记作TID。交易全体构成了交易数据库D,|D|等于D中交易的个数。引例中包含10笔交易,因此|D|=10。
定义三:对于项集X,设定count(X⊆T)为交易集D中包含X的交易的数量,则项集X的支持度为:
support(X)=count(X⊆T)/|D|
引例中X={bread, milk}出现在T1,T2,T5,T9和T10中,所以支持度为0.5。
定义四:最小支持度是项集的最小支持阀值,记为SUPmin,代表了用户关心的关联规则的最低重要性。支持度不小于SUPmin 的项集称为频繁集,长度为k的频繁集称为k-频繁集。如果设定SUPmin为0.3,引例中{bread, milk}的支持度是0.5,所以是2-频繁集。
定义五:关联规则是一个蕴含式:
R:X⇒Y
其中X⊂I,Y⊂I,并且X∩Y=⌀。表示项集X在某一交易中出现,则导致Y以某一概率也会出现。用户关心的关联规则,可以用两个标准来衡量:支持度和可信度。
定义六:关联规则R的支持度是交易集同时包含X和Y的交易数与|D|之比。即:
support(X⇒Y)=count(X⋃Y)/|D|
支持度反映了X、Y同时出现的概率。关联规则的支持度等于频繁集的支持度。
定义七:对于关联规则R,可信度是指包含X和Y的交易数与包含X的交易数之比。即:
confidence(X⇒Y)=support(X⇒Y)/support(X)
可信度反映了如果交易中包含X,则交易包含Y的概率。一般来说,只有支持度和可信度较高的关联规则才是用户感兴趣的。
定义八:设定关联规则的最小支持度和最小可信度为SUPmin和CONFmin。规则R的支持度和可信度均不小于SUPmin和CONFmin ,则称为强关联规则。关联规则挖掘的目的就是找出强关联规则,从而指导商家的决策。
2 、 Apriori 关联规则的算法
1 算法简介
在数据挖掘领域,Apriori算法是挖掘关联规则的经典算法。Apriori算法采用的是自底向上的方法,从1-频繁集开始,逐步找出高阶频繁集。
它的基本流程是:第一次扫描交易数据库D时,产生1-频繁集。在此基础上经过连接、修剪产生2-频繁集。以此类推,直到无法产生更高阶的频繁集为止。在第k次循环中,也就是产生k-频繁集的时候,首先产生k-候选集,k-候选集中每一个项集都是对两个只有一个项不同的属于k-1频繁集的项集连接产生的,k-候选集经过筛选后产生k-频繁集。
2 理论基础
首先来看一个频繁集的性质。
定理:如果项目集X是频繁集,那么它的非空子集都是频繁集。
根据定理,已知一个k-频繁集的项集X,X的所有k-1阶子集都肯定是频繁集,也就肯定可以找到两个k-1频繁集的项集,它们只有一项不同,且连接后等于X。这证明了通过连接k-1频繁集产生的k-候选集覆盖了k-频繁集。同时,如果k-候选集中的项集Y,包含有某个k-1阶子集不属于k-1频繁集,那么Y就不可能是频繁集,应该从候选集中裁剪掉。Apriori算法就是利用了频繁集的这个性质。
4.1 产生1-频繁集
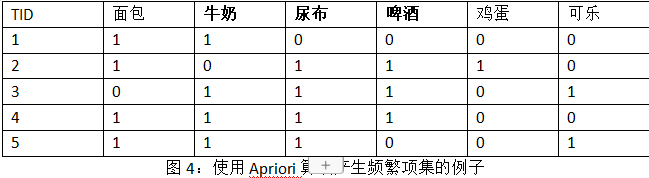
扫描交易数据库,统计得各个项目出现的次数,bread是7次,cream是3次,milk是8次,tea是7次,cake是2次,beer是1次。容易知道1-频繁集包括{bread},{cream},{ milk},{ tea}。
4.2 产生2-频繁集
对1-频繁集进行连接,得到候选集为{bread,cream},{bread,milk},{bread,tea},{cream,milk}, {cream,tea},{milk,tea}。扫描交易数据库,得到它们的支持度分别为0.3,0.5,0.5,0.3,0.2,0.5。于是得到2-频繁集是{bread,cream},{bread,milk},{bread,tea},{cream,milk} ,{milk,tea}。
4.3 产生3-频繁集
对2-频繁集进行连接,并删掉其中包含有子集不是频繁集的项集(比如{bread,cream,tea}有子集{cream,tea}不是频繁集,所以删去),得到的候选集是{bread,cream,milk},{bread,milk,tea}。扫描交易数据库,它们的支持度是0.3,0.3。因此3-频繁集为{bread,cream,milk},{bread,milk,tea}。
4.4 产生4-频繁集
对3-频繁集进行连接,候选集为空,因此4-频繁集为空,算法结束。最终产生了所有的频繁集{bread},{cream},{ milk},{ tea},{bread,cream},{bread,milk},{bread,tea},{cream,milk} ,{milk,tea},{bread,cream,milk},{bread,milk,tea}。
6 优化
,{cream,milk} ,{milk,tea},{bread,cream,milk},{bread,milk,tea}。
6 优化
Apriori算法的缺陷是需要多次扫描数据库,而且可能产生非常大的候选集,降低了算法的性能。因此有不少关于Apriori算法的优化方法,其中一个是基于数据分割的优化方法。首先把大容量的数据库从逻辑上分为几个互不相交的块,每块都应用Apriori算法产生局部的频繁集,然后测试它们的支持度来得到最终的全局频繁集。这种方法减少了候选集对内存的负担,而且支持并行挖掘。