一、为何要用雪花算法
1、问题产生的背景
现如今越来越多的公司都在用分布式、微服务,那么对应的就会针对不同的服务进行数据库拆分,然后当数据量上来的时候也会进行分表,那么随之而来的就是分表以后id的问题。
例如之前单体项目中一个表中的数据主键id都是自增的,mysql是利用autoincrement来实现自增,而oracle是利用序列来实现的,但是当单表数据量上来以后就要进行水平分表,阿里java开发建议是单表大于500w的时候就要分表,但是具体还是得看业务,如果索引用的号的话,单表千万的数据也是可以的。水平分表就是将一张表的数据分成多张表,那么问题就来了如果还是按照以前的自增来做主键id,那么就会出现id重复,这个时候就得考虑用什么方案来解决分布式id的问题了。
2、解决方案
2.1、数据库表
可以在某个库中专门维护一张表,然后每次无论哪个表需要自增id的时候都去查这个表的记录,然后用for update锁表,然后取到的值加一,然后返回以后把再把值记录到表中,但是这个方法适合并发量比较小的项目,因此每次都得锁表。
2.2、redis
因为redis是单线程的,可以在redis中维护一个键值对,然后哪个表需要直接去redis中取值然后加一,但是这个跟上面一样由于单线程都是对高并发的支持不高,只适合并发量小的项目。
2.3、uuid
可以使用uuid作为不重复主键id,但是uuid有个问题就是其是无序的字符串,如果使用uuid当做主键,那么主键索引就会失效。
2.4、雪花算法
雪花算法是解决分布式id的一个高效的方案,大部分互联网公司都在使用雪花算法,当然还有公司自己实现其他的方案。
二、雪花算法
1、原理

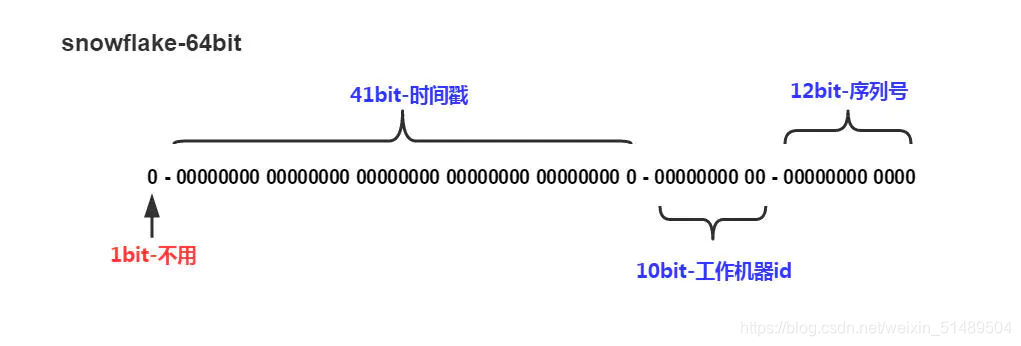
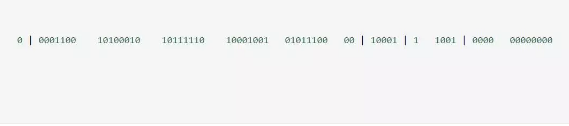
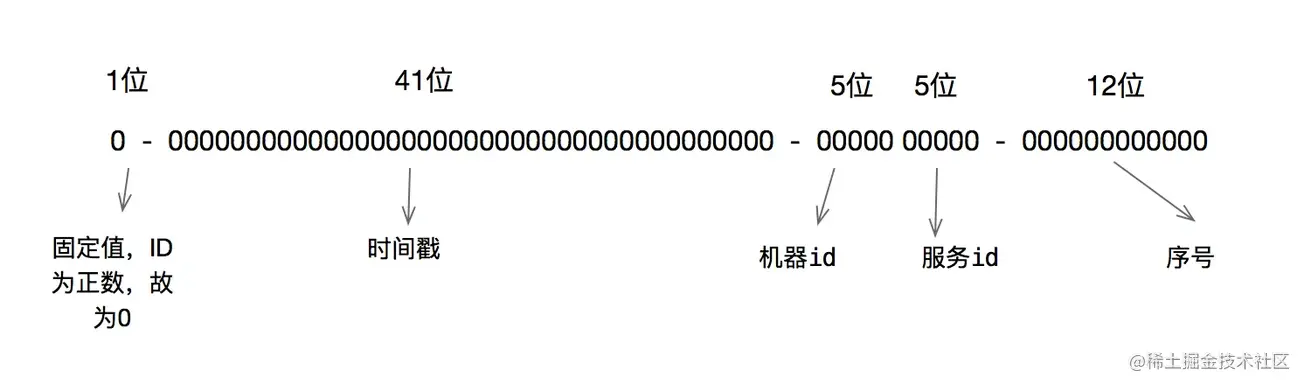
雪花算法就是使用64位long类型的数据存储id,最高位一位存储0或者1,0代表整数,1代表负数,一般都是0,所以最高位不变,41位存储毫秒级时间戳,10位存储机器码(包括5位datacenterId和5位workerId),12存储序列号。这样最大2的10次方的机器,也就是1024台机器,最多每毫秒每台机器产生2的12次方也就是4096个id。(下面有代码实现)
但是一般我们没有那么多台机器,所以我们也可以使用53位来存储id。为什么要用53位?
因为我们几乎都是跟web页面打交道,就需要跟js打交道,js支持最大的整型范围为53位,超过这个范围就会丢失精度,53之内可以直接由js读取,超过53位就需要转换成字符串才能保证js处理正确。53存储的话,32位存储秒级时间戳,5位存储机器码,16位存储序列化,这样每台机器每秒可以生产65536个不重复的id。
2、缺点
由于雪花算法严重依赖时间,所以当发生服务器时钟回拨的问题是会导致可能产生重复的id。当然几乎没有公司会修改服务器时间,修改以后会导致各种问题,公司宁愿新加一台服务器也不愿意修改服务器时间,但是不排除特殊情况。
如何解决时钟回拨的问题?可以对序列化的初始值设置步长,每次触发时钟回拨事件,则其初始步长就加1w,可以在下面代码的第85行来实现,将sequence的初始值设置为10000。
改文章内容选自mysql中雪花算法是什么意思 - MySQL数据库 - 亿速云 (yisu.com)
仅供学习和讨论参考,侵删