SnowFlake雪花算法(Java版本)
- 一、SnowFlake算法
- 二、代码实现
- 三、应用场景
- 四、优缺点
- 五、分布式生成ID方式
一、SnowFlake算法
雪花算法(Snowflake)是twitter公司内部分布式项目采用的ID生成算法
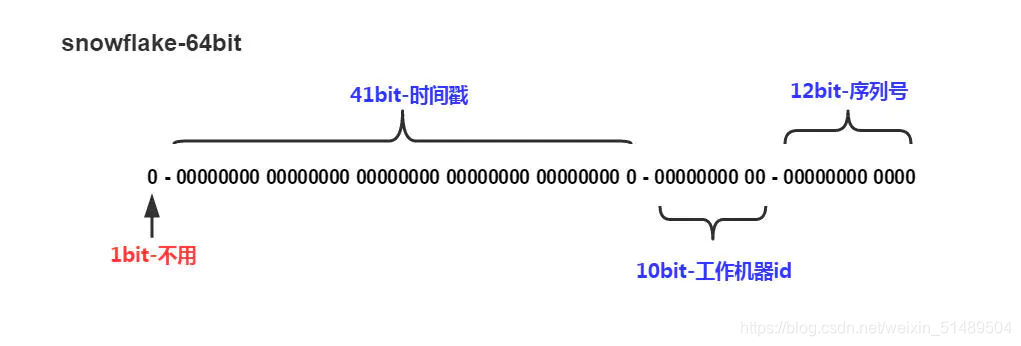
- Snowflake生成的是Long类型的ID,一个Long类型占8个字节,每个字节占8比特,也就是说一个Long类型占64个比特。
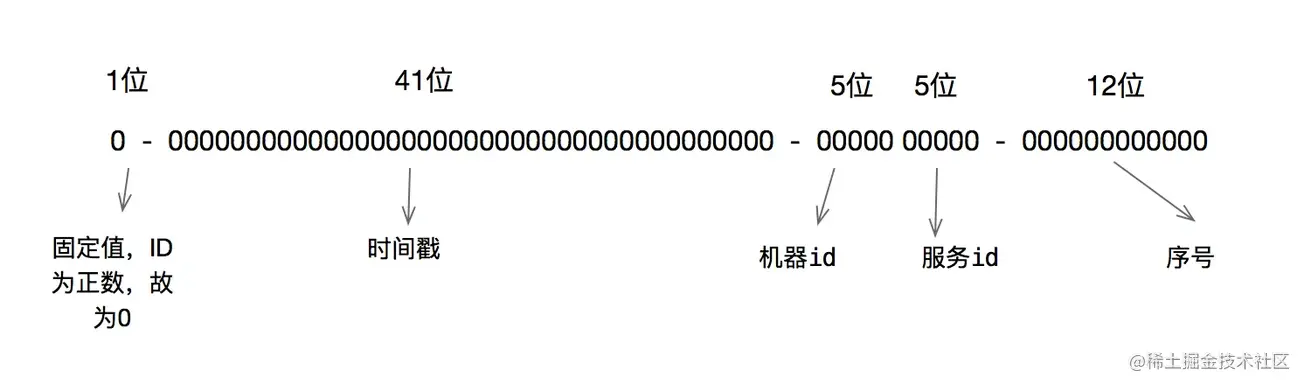
- Snowflake ID组成结构:正数位(占1比特)+ 时间戳(占41比特)+ 机器ID(占5比特)+ 数据中心(占5比特)+ 自增值(占12比特),总共64比特组成的一个Long类型。

- 第一位:占用1bit,Java中long的最高位是符号位代表正负,正数是0,负数是1,一般生成ID都为正数,所以默认为0。
- 时间戳:占用41bit,毫秒级的时间,不建议存当前时间戳,而是用(当前时间戳 - 固定开始时间戳)的差值,可以使产生的ID从更小的值开始;41位的时间戳可以使用69年,(1L << 41) / (1000L * 60 * 60 * 24 * 365) = 69年
- 工作机器id:占用10bit,最多可以容纳1024个节点(可以改造为5位工作中心+5位数据中心,具体如上图第二部分)
- 序列号:占用12bit,最多可以累加到4095。自增值支持同一毫秒内同一个节点可以生成4096个ID,这个值在同一毫秒同一节点上从0开始不断累加。(最大可以支持单节点差不多四百万的并发量)
SnowFlake可以保证:
所有生成的id按时间趋势递增
整个分布式系统内不会产生重复id(因为有datacenterId和workerId来做区分)
根据这个算法的逻辑,只需要将这个算法实现出来,封装为一个工具方法,那么各个业务应用可以直接使用该工具方法来获取分布式ID,只需保证每个业务应用有自己的工作机器id即可,而不需要单独去搭建一个获取分布式ID的应用。
二、代码实现
public class SnowFlake {// 因为二进制里第一个 bit 为如果是 1,那么都是负数,但是我们生成的 id 都是正数,所以第一个 bit 统一都是 0。/*** 机器ID 2进制5位*/private long workerId;/*** 机房ID 2进制5位*/private long datacenterId;/*** 代表一毫秒内生成的多个id的最新序号 12位,范围从0到4095*/private long sequence;/*** 设置一个时间初始值(这个用自己业务系统上线的时间) 2^41 - 1 差不多可以用69年*/private long twepoch = 1585644268888L;/*** 5位的机器id*/private long workerIdBits = 5L;/*** 5位的机房id*/private long datacenterIdBits = 5L;/*** 每毫秒内产生的id数 2 的 12次方*/private long sequenceBits = 12L;/*** 这个是二进制运算,就是5 bit最多只能有31个数字,也就是说机器id最多只能是32以内*/private long maxWorkerId = -1L ^ (-1L << workerIdBits);/*** 这个是一个意思,就是5 bit最多只能有31个数字,机房id最多只能是32以内*/private long maxDatacenterId = -1L ^ (-1L << datacenterIdBits);/*** 机器ID向左移12位*/private long workerIdShift = sequenceBits;/*** 机房ID向左移17位*/private long datacenterIdShift = sequenceBits + workerIdBits;/***时间戳向左移22位*/private long timestampLeftShift = sequenceBits + workerIdBits + datacenterIdBits;/*** 生成序列的掩码,这里为4095 (0b111111111111=0xfff=4095)*/private long sequenceMask = -1L ^ (-1L << sequenceBits);/*** 上次生成ID的时间截,记录产生时间毫秒数,判断是否是同1毫秒*/private long lastTimestamp = -1L;/*** 构造函数* @param workerId* @param datacenterId* @param sequence*/public SnowFlake(long workerId, long datacenterId, long sequence){// 检查机房id和机器id是否超过最大值,不能小于0if (workerId>maxWorkerId||workerId<0){throw new IllegalArgumentException(String.format("worker Id can't be greater than %d or less than 0",maxWorkerId));}if (datacenterId>maxDatacenterId||datacenterId<0){throw new IllegalArgumentException(String.format("datacenter Id can't be greater than %d or less than 0",maxDatacenterId));}this.workerId=workerId;this.datacenterId=datacenterId;this.sequence=sequence;}/*** 这个是核心方法,通过调用nextId()方法,让当前这台机器上的snowflake算法程序生成一个全局唯一的id* @return*/public synchronized long nextId(){// 获取当前的时间戳,单位是毫秒long timestamp=timeGen();//如果当前时间小于上一次ID生成的时间戳,说明系统时钟回退过这个时候应当抛出异常if (timestamp<lastTimestamp){System.err.printf("clock is moving backwards. Rejecting requests until %d.",lastTimestamp);throw new RuntimeException(String.format("Clock moved backwards. Refusing to generate id for %d milliseconds",lastTimestamp-timestamp));}// 下面是说假设在同一个毫秒内,又发送了一个请求生成一个id// 这个时候就得把seqence序号给递增1,最多就是4096if (lastTimestamp == timestamp) {// 这个意思是说一个毫秒内最多只能有4096个数字,无论你传递多少进来,//这个位运算保证始终就是在4096这个范围内,避免你自己传递个sequence超过了4096这个范围sequence = (sequence + 1) & sequenceMask;//当某一毫秒的时间,产生的id数 超过4095,系统会进入等待,直到下一毫秒,系统继续产生IDif (sequence == 0) {// 阻塞到下一个毫秒,获得新的时间戳timestamp = tilNextMillis(lastTimestamp);}}else{ // 时间戳改变,毫秒内序列重置sequence=0;}//上次生成ID的时间截lastTimestamp=timestamp;// 这儿就是最核心的二进制位运算操作,生成一个64bit的id// 先将当前时间戳左移,放到41 bit那儿;将机房id左移放到5 bit那儿;将机器id左移放到5 bit那儿;将序号放最后12 bit// 最后拼接起来成一个64 bit的二进制数字,转换成10进制就是个long型return ((timestamp-twepoch)<<timestampLeftShift)|(datacenterId<<datacenterIdShift)|(workerId<<workerIdShift)|sequence;}/*** 当某一毫秒的时间,产生的id数 超过4095,系统会进入等待,直到下一毫秒,系统继续产生ID* @param lastTimestamp 上次生成ID的时间截* @return 当前时间戳*/private long tilNextMillis(long lastTimestamp) {long timestamp=timeGen();while(timestamp<=lastTimestamp){timestamp=timeGen();}return timestamp;}/*** 获取当前时间戳* @return 当前时间(毫秒)*/private long timeGen() {return System.currentTimeMillis();}/*** main 测试类* @param args*/public static void main(String[] args) {SnowFlake worker=new SnowFlake(1,1,1);for (int i=0;i<22;i++){System.out.println(worker.nextId());}}
}
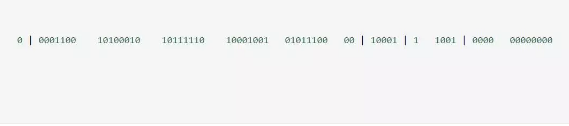
产生的唯一序列ID:
309845423537917952
309845423542112256
309845423542112257
309845423542112258
309845423542112259
309845423542112260
309845423542112261
309845423542112262
309845423542112263
309845423542112264
309845423542112265
309845423542112266
309845423542112267
309845423542112268
309845423542112269
309845423542112270
309845423542112271
309845423542112272
309845423542112273
309845423542112274
309845423542112275
309845423542112276
三、应用场景
1.数据库表主键:很多DBA在大型生产应用禁用auto_increment的ID,这时可以选snowflake替代。
2.TraceId:分布式系统追踪,希望用一个ID贯穿所有子系统来追踪分布式交互过程。也有系统产生一个Exception,我们需要对Exception编号等。
3. 摇一摇/抢红包ID:摇一摇的特点是活动促销的时候,短时间内访问特别大,需要一个高性能的ID生成器。
四、优缺点
优点:
- ID在内存生成,不依赖于数据库,高性能高可用。
- 每秒可生成几百万ID,容量大
- 由于ID呈趋势递增,插入数据库后,使用索引的时候性能较高。
缺点:
- 依赖于系统时钟的一致性,如果某台机器的系统时钟回拨,有可能造成ID冲突或者ID乱序。
- 同一台机器的系统时间回拨过,那么有可能出现ID重复的情况
五、分布式生成ID方式
- UUID
UUID(Universally Unique Identifier)的标准型式包含32个16进制数字,以连字号分为五段,形式为8-4-4-4-12的36个字符。示例:5f26d8c0-6e09-43cf-9300-6fda1d11985c
- 优点:
性能非常高,本地生成,没有网络消耗;实现了唯一性。 - 缺点:
1.无序,无法预测它的生成顺序,不能生成递增有序数字。
2.主键,ID作为主键时在特定环境中会存在一些问题。例如在做DB主键的场景下,UUID就非常不适用。MySQL官方有明确的建议主键要尽量越短越好。
3.索引,B+树索引的分裂。分布式id作为主键,而主键包含索引,mysql的索引是通过B+树实现的,每一次新的UUID数据的插入,为了查询优化,都会对索引底层的B+树进行修改,又因为UUID是无序的,所以每一次UUID数据的插入会对主键底层的B+树进行很大的修改,这样会导致一些中间节点断裂,也会创造出很多不饱和的节点,这样大大降低了数据库的插入操作。
UUID只能保证全局唯一性,不满足后面的趋势递增,单调递增
- 数据库主键自增
在分布式里面,数据库的自增ID机制主要原理是:数据库自增ID和mysql数据库的replace into实现的。
这里replace into跟insert功能类似,不同点在于:replace into首先尝试插入数据列表中,如果发现表中已经存在此行数据(根据主键或唯一索引判断)则先删除,再插入;否则则可以直接插入新数据。
replace into的含义是插入一条记录,如果表中唯一索引的值遇到冲突,则替换老数据。
- 优点:
实现了唯一性、趋势递增。 - 缺点(集群情况):
1.系统水平拓展比较困难,比如定义好了步长和机器台数之后,如果需要新添加机器怎么做?假设现在 只有一台机器发号是1,2,3,4,5(步长=1),这时候需要扩容一台新机器:将第二台机器的初值设置的比第一台多很多。当扩容机器达到100台呢?就会出现初值设置会非常大。
2.数据库压力还是很大,每次获取id都得读写一次数据库,非常影响性能,不符合分布式ID系统低延迟、高QPS的硬性要求。
我们每次插入的时候,发现都会把原来的数据给替换,并且ID也会增加
这就满足了:递增性、单调性、唯一性
在分布式情况下,并且并发量不多的情况,可以使用这种方案来解决,获得一个全局的唯一ID
- Redis
-
单机版
因为Redis是单线程的,天生就能够保证原子性,可以使用原子操作INCR和INCRBY来实现。 -
集群分布式
Redis集群可以获取更高的吞吐量。
注意:
在Redis集群情况下,同样和MySQL一样需要设置不同的增长步长,同时key一定要设置有效期,可以使用Redis集群来获取更高的吞吐量。 -
假如一个集群有Redis,可以初始化每台Redis的值分别为1,2,3,4,5,然后步长都是5:
各个Redis生成的ID为:
A:1,6,11,16,21
B:2,7,12,17,22
C:3,8,13,18,23
D:4,9,14,19,24
E:5,10,15,20,25
缺点:需要额外配置和维护Redis集群等工作才能获得id,比较麻烦。
- 雪花算法
- 优点
1.毫秒数在高维,自增序列在低位,整个ID都是趋势递增的
2.不依赖数据库等第三方系统,以服务的方式部署,稳定性更高,生成ID的性能也是非常高的
3.可以根据自身业务特性分配bit位,非常灵活 - 缺点
1.依赖机器时钟,如果机器时钟回拨,会导致重复ID生成
2.在单机上是递增的,但由于涉及到分布式环境,每台机器上的时钟不可能完全同步,有时候会出现不是全局递增的情况,此缺点可以认为无所谓,一般分布式ID只要求趋势递增,并不会严格要求递增,90%的需求只要求趋势递增。
其它补充:
为了解决时钟回拨问题,导致ID重复,后面有人专门提出了解决的方案
- UidGenerator - 百度开源的分布式唯一ID生成器
- Leaf - 美团点评分布式ID生成系统
参考:
参考一
参考二
参考三