本文是对vim各种命令的使用介绍,旨在让大家快速学习掌握

什么是vim
vim是Linux环境下一款功能强大、高度可定制的文本编辑工具
vim的工作模式
一般分为6种
- 普通模式用vim打开一个文件时默认模式,也叫命令模式,允许用户通过各种命令浏览代码、滚屏等操作。
- 插入模式:也可以叫做编辑模式,在普通模式下敲击 i 、a 或 o 就进入插入模式,允许用户通过键盘输入、编辑。
- 命令行模式:在普通模式下,先输入冒号:,接着输入命令,就可以通过配置命令对vim进行配置了,如改变颜色主题、显示行号等,这些配置命令也可以保存到/etc/vim/vimrc配置文件中,每次打开默认配置执行。
- 可视化模式:在普通模式下敲击前盘上的 v 键,就进入可视化模式,然后移动光标就可以选中一块文本,常用来完成文本的复制、粘贴、删除等操作。
- 替换模式:如果我们想修改某个字符,不需要先进入插入模式,删除,然后再输入新的字符,直接在普通模式下,敲击R键就可以直接替换。
- EX模式:类似于命令行模式,可以一次运行多个命令
vim的各种工作模式可以通过不同的键进行切换,用户统一使用ESC键返回到普通模式
命令的介绍使用
光标移动命令
单个字符移动:
h: 向左移动
l: 向右移动
j: 向下移动
k: 向上移动
xh: 向左移动x个字符距离单词移动:
w: 将光标移动到下一个单词的开头
b: 将光标移动到前一个单词的开头
e: 将光标移动到下一个单词的词末
E: 移动到单词的结尾(忽略标点符号)
ge: 将光标移动到上一个单词的词末
2w: 指定移动的次数行移动:
$: 将光标移动到当前行的行尾
0: 将光标移动到当前行的行首
^: 将光标移动到当前行的第一个非空字符(行首和当前行非空字符不是一个位置)
2|: 移到当前行的第2列
fx: 将光标移动到当前行的第一个字符x上
3fx: 将光标移动到航前行的第3个字符x上
tx: 将光标移动到目标字符x的前一个字符上
fx和tx可以通过;和,进行重复移动,一个是正向重复,一个是反向重复
%: 用于符号间的移动,它会在一对()、[]、{}之间跳跃文本块移动:
(: 移到当前句子的开头
): 移到下一个句子的开头
{: 移到当前一段的开头
}: 移到下一段的开头
[[: 移到当前这一节的开头
]]: 移到下一节的开头在屏幕中移动
xG: 跳转到指定的第x行,G移动到文件按末尾,``(2次单引号)返回到跳转前的位置
gg: 移动到文件开头
x%: 移动到文件中间,就使用50%
H: 移动到home
M: 移动到屏幕中间
L: 移动到一屏末尾
ctrl+G: 查看当前的位置状态
滚屏与跳转
半屏滚动: ctrl+u/ctrl+d
全屏滚动: ctrl+f/ctrl+b定位光标的位置
zz: 将光标置于屏幕的中间
zt: 将光标移动到屏幕的顶部
zb: 将光标移动到屏幕的底部设置跳转标记
mx,my,mz设置三个位置
`x,`y,`z跳转到设置
文本插入操作
i: 在当前光标的前面插入字符
a: 在当前光标的后面追加字符
o: 在当前光标的下一行行首插入字符
I: 在一行的开头添加文本
A: 在一行的结尾处添加文本
O: 在光标当前行的上一行插入文本
s: 删除当前光标处的字符并进入到插入模式
S: 删除光标所在处的行,并进入到插入模式
u: 撤销修改
文本删除操作
字符删除
x: 删除当前光标所在处的字符
X: 删除当前光标左边的字符单词删除
dw: 删除一个单词(从光标处到空格)
daw: 无论光标在什么位置,删除光标所在的整个单词(包括空白字符)
diw: 删除整个单词文本,但是保留空格字符不删除
d2w: 删除从当前光标开始处的2个单词
d$: 删除从光标到一行末尾的整个文本
d0: 删除从光标到一行开头的所有单词
dl: 删除当前光标处的字符=x
dh: 删除当前光标左边的字符=X行删除
dd: 删除当前光标处的一整行=D
5dd: 删除从光标开始处的5行代码
dgg: 删除从光标到文本开头
dG: 删除从光标到文本结尾行合并
J: 删除一个分行符,将当前行与下一行合并
文本复制、剪切与粘贴
y: 复制,p:粘贴
yw: 复制一个单词
y2w: 复制2个单词
y$: 复制从当前光标到行结尾的所有单词
y0: 复制从当前光标到行首的所有单词
yy: 复制一整行
2yy: 复制从当前光标所在行开始的2行复制文本块1.首先进入visual模式:v2.移动光标选择文本3.复制与粘贴的操作
文本的修改与替换
cw: 删除从光标处到单词结尾的文本并进入到插入模式
cb: 删除从光标处到单词开头的文本并进入到插入模式
cc: 删除一整行并进入到插入模式
~: 修改光标下字符的大小写
r: 替换当前光标下的字符
R: 进入到替换模式
xp: 交换光标和下一个字符文本的查找与替换
/string 正向查找
?string 反向查找设置高亮显示:set hls*按键将当前光标处的单词高亮显示,使用n浏览下一个查找高亮的结果
:s/old/new 将当前行的第一个字符串old替换为new
:s/old/new/g 将当前行的所有字符串old替换为new
:90s/old/new/g 将指定行的所有字符串old替换为new
:90,93s/old/new/g 将指定范围的行的所有字符串old替换为new
:%s/old/new/g 将文本中所有的字符串old替换为new
:%s/old/new/gc 依次替换每个字符串关键字
:%s/^struct/int/g 将所有以struct开头的字符串替换为int撤销修改、重做与保存
u: 撤销上一步的操作。
Ctrl+r: 将原来的插销重做一遍
:U 恢复一整行原来的面貌(文件打开时的文本状态)
:q 若文件没有修改,直接退出
:q! 文件已经被修改,放弃修改退出
:wq 文件已经被修改,保存修改并退出
:e! 放弃修改,重新回到文件打开时的状态编辑多个文件
文件和缓冲区的区别
文件是保存在磁盘上的,而打开的文件的文件是在内存中,
在内存中有一个缓冲区,用来存放打开的文件。
vim每次打开文件时都会创建一个缓冲区,vim支持打开多个文件
:buffers 查看缓冲区列表==ls
:buffer N 根据缓冲区列表的编号跳转到指定缓冲区
:bnext/bprev 遍历缓冲区列表
:bfirst/blast 分别调到缓冲区列表的开头和结尾
:write 将缓冲区的修改保存到磁盘上
:edit! e! 放弃缓冲区的修改,恢复到文件打开时的状态
:edit file 编辑另一个文件
:wnext 保存当前缓冲区的修改并跳转到缓冲区列表中的下一个文件
:set autowrite标签页与折叠栏
标签页的新建:tabedit file/tab split
标签页的切换: tabn/tabp
按键:gt/gT
标签页的关闭tabclose
关闭当前的标签页: tabonly
创建一个折叠zf200G:将光标和200行之间的代码折叠起来
折叠的打开与关闭za: 打开和关闭折叠zr/zm: 一层一层地打开和关闭折叠zR/zM: 分别打开和关闭所有的折叠
折叠键的光标移动zj: 跳转到下一个折叠处zk: 跳转到上一个折叠处
删除折叠zd: 删除光标下的折叠zD: 删除光标下的折叠以及嵌套的折叠zE: 删除所有的折叠标签创建的折叠当退出vim之后就失效了。多窗口操作
分割窗口split/vsplit filename
窗口间跳转ctrl+w hjklctrl+w w
移动窗口ctrl+w HJKL
调整窗口尺寸ctrl+w +/- 调整窗口的高度ctrl+w </> 调整窗口的宽度ctrl+w = 所有的窗口设置相同的尺寸:resize n将当前窗口尺寸调整为N行
关闭窗口close: 关闭一个窗口qall: 退出所有窗口qall!: 放弃修改,退出所有窗口wqall: 保存并退出所有窗口wall: 保存所有窗口
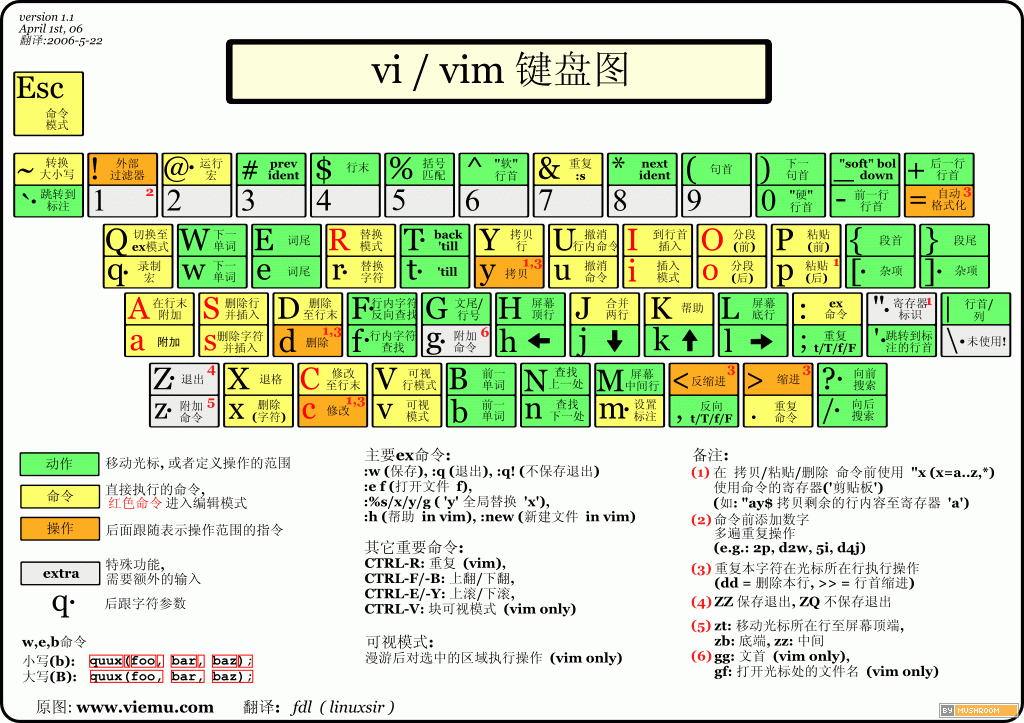
vim的命令就介绍这些,多多支持






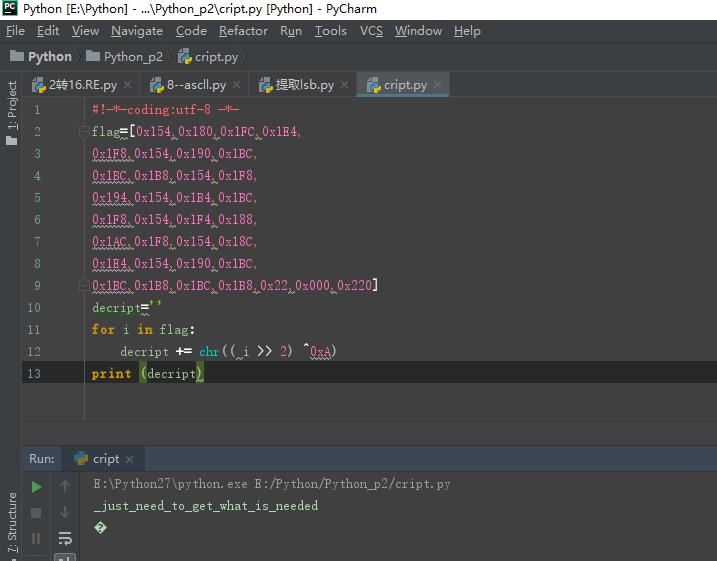
![[SWPUCTF 2021 新生赛]re2](https://img-blog.csdnimg.cn/f8f1ebefff4645c69ca58cd8d65f8741.png)