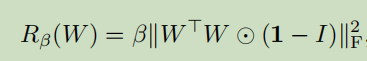URL:
https://arxiv.org/pdf/1809.11096.pdf
code:
https://github.com/AaronLeong/BigGAN-pytorch
https://tfhub.dev/s?q=biggan
TL;DR
号称具有划时代意义的BigGAN,由DeepMind团队在ICLR2019上发表,将精度作出了跨越式提升。
将Inception Score (IS,越大越好) 由之前最好的52.52提升到166.3,Frechet Inception Distance (FID,越小越好) 由之前最好的18.65提升到9.6。生成图例:
![[外链图片转存失败(img-OkJYVt6Y-1562840306406)(upload://8OhHtH2NbtQy0I6MTFn6GwEjJku.jpeg)]](https://img-blog.csdnimg.cn/20190711181849493.png)
Contribution
- 简单地使用了2-4倍参数量的参数,8倍的batchsize,就能够得到很大的性能提升。(对比于SAGAN)
- 通过设置truncation trick的不同阈值能够使生成器在多样性和稳定性之间作调整。
- 将现有的技术整合能够很好地提高模型稳定性,但是会降低性能。
Algorithm
![[外链图片转存失败(img-ZqqKUClo-1562840306409)(upload://j1CFXOrQFF5Fv6hghE43mJkEElH.png)]](https://img-blog.csdnimg.cn/20190711181904628.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3dhcGxlXzA4MjA=,size_16,color_FFFFFF,t_70)
从上面可以看到,仅提高batchsize和参数量(※处),也会有较明显的精度提升。
另外,上表中三个作者用到的能够进一步提升模型效能的方法:
① Shared:使用共享嵌入(shared embeddings ),在生成器的BN层中加入类别信息嵌入,将会大大的增加参数量,因此选择共享嵌入,也就是对每层的weighs和bias做投影,这样将会减少计算和内存的开销,将训练速度提升37%。
② Hier:使用分层的潜在空间(hierarchical latent space ),也就是在生成器网络的每一层都会被喂入噪声向量。分层空间增加了计算量和内存消耗,但是可以使得精度提升4%,训练速度加快18%。
③ Ortho:使用正交正则化(Orthogonal Regularization ),为了能够抵消过饱和问题(如下图),本文采用了约束生成器使其平滑的策略。
![[外链图片转存失败(img-iqKyj0gf-1562840306419)(upload://fr0tF5ex9vy8PF9CwwhwHVU4gAu.png)]](https://img-blog.csdnimg.cn/20190711181919424.png)
传统正交正则方法(Brock et al., 2017)已经被证明了有其局限性 (Miyato et al., 2018):
![[外链图片转存失败(img-rwAFZZFD-1562840306426)(upload://6ZoWL6V15KjBQcCopTB8TJCOOs1.png)]](https://img-blog.csdnimg.cn/20190711181929980.png)
作者提出了另一种方法:
![[外链图片转存失败(img-wHKLPzSy-1562840306427)(upload://pdXaFddhFAaFJjcSOdkRG3ntYPy.png)]](https://img-blog.csdnimg.cn/20190711181937939.png)
即把对角减1直接换成了消去,即放松了对截断的限制,提高了平滑性。实验证明在不使用该方法只有16%的模型能够适应截断,而加入了后这个数值达到了60%。
Model
![[外链图片转存失败(img-gRprpLG7-1562840306429)(upload://okRp25HBH3s5XywHCXylcYE2qxJ.png)]](https://img-blog.csdnimg.cn/20190711181949635.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3dhcGxlXzA4MjA=,size_16,color_FFFFFF,t_70)
上图a是模型生成器框架,其中的ResBlock如b所示。c是判别器的ResBlock。模型框架本身并没有很特殊的点。
※Negative Results (相当于发现的一些问题)
- double网络深度会影响精度。
- 在判别器上使用嵌入参数的方法,对参数的选择非常敏感,刚开始有助于训练,后续则很难优化。
- 使用WeightNorm替换BatchNorm会使得训练难以收敛,去掉BatchNorm只有Spectral Normalization也会使得难以收敛(BatchNorm在生成器里还是一个必要的存在)。
- 判别器中增加BatchNorm会使得训练难以收敛(一般用InstanceNorm)。
- 在128128的输入情况下,改变attention block对精度没提升,在256256输入的情况下,将attention block上移一级,会对精度有提升。
- 相比采用33的卷积核,采用55的卷积核会使精度有略微提升,而7*7则不会。
- 使用膨胀卷积会降低精度。
- 将生成器中的最近邻插值换为双线性插值会使得精度降低。
- 在共享嵌入中使用权值衰减(weight decay),当该衰减值较大(10-6 )会损失精度,较小(10-8 )会起不到作用,不能阻止梯度爆炸。
- 在类别嵌入中,使用多层感知机(MLP)并不比线性投影(linear projections)好。
- 梯度归一化截断会使得训练不平稳。
Thoughts
本文可以说是对以往关于GAN工作的一个大型总结,并提出了一些优化模型的算法(如共享嵌入等)。这些总结出来的trick都可能在未来GAN的发展中祈祷标杆的作用。
另外,能够将BatchSize随便调到2048也是需要一定实力基础才能做出来的操作,github上一些其他人的实现都是将BatchSize调回了64。