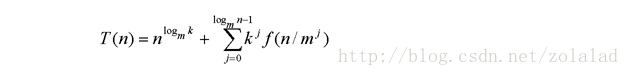【飞桨】【Paddlepaddle】【论文复现】BigGAN
- 用于高保真自然图像合成的大规模 GAN 训练
- LARGE SCALE GAN TRAINING FOR HIGH FIDELITY NATURAL IMAGE SYNTHESIS
- 1、BiagGAN的贡献
- 2.1背景
- 2.2具体措施与改变
- 2.2.1规模(scaling up)
- 2.2.2截断技巧(Truncation)
- 3、不稳定性分析
- 4、结论
- Reference:
用于高保真自然图像合成的大规模 GAN 训练
LARGE SCALE GAN TRAINING FOR HIGH FIDELITY NATURAL IMAGE SYNTHESIS
生成对抗网络(GANs, Goodfellow et al. (2014))能够训练输入的图片生成出新的样本图片(Generator),但传统的GANs在生成图片是会出现一些问题,例如模式崩塌,难以收敛等。并且传统GANs生成的图片不具备足够的精度和分辨率。BigGAN(A.Brock, et al 2018) 以最大规模培训了生成对抗网络,并研究了这种规模所特有的不稳定性。它将正交正则化应用于生成器使得它适用于简单的“截断技巧”,允许通过截断潜在空间来精确控制样本保真度和变化之间的权衡。BigGAN的 Inception Score(IS)为 166.3,Fréchet Inception Distance(FID)为 9.6,相比之前的最佳 (指论文发表时)IS 为 52.52,FID 为 18.65。
Paper链接:BigGAN.
Github:BigGAN-Pytorch.
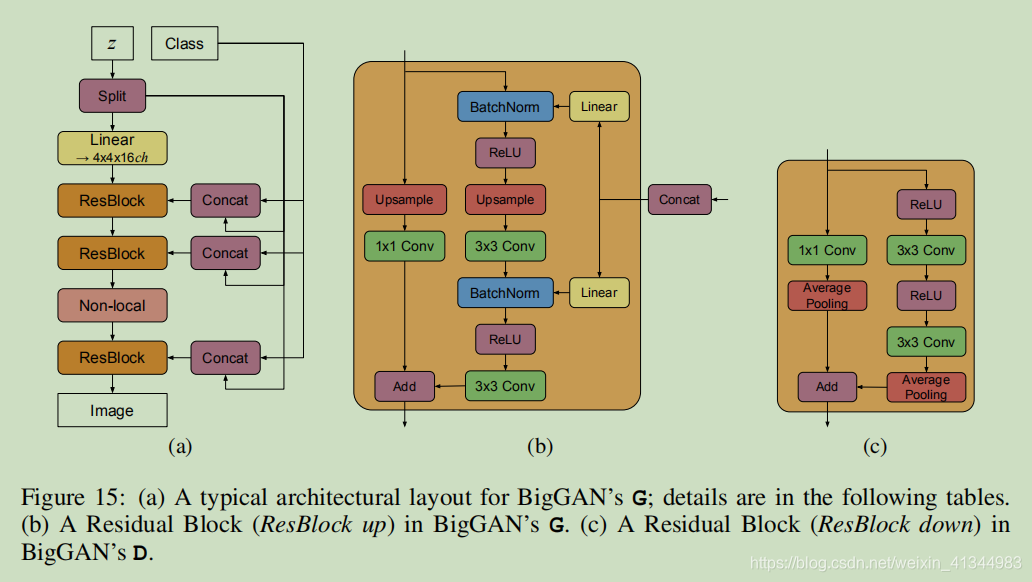
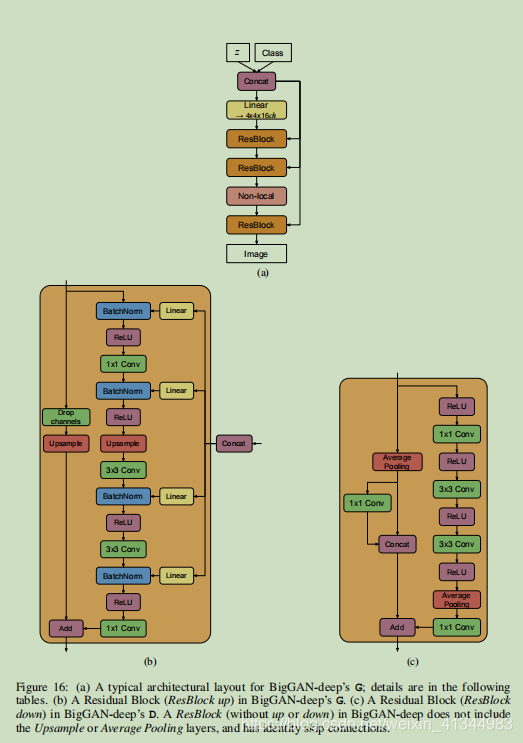
1、BiagGAN的贡献
- 证明了 GAN 从缩放中获益匪浅,并且与现有技术相比,训练模型的参数为 2 到 4 倍,batch size达到 8 倍。 我们介绍了两种简单的通用体系结构更改,可以提高可伸缩性,并修改正则化方案不断调节,从而显著提升性能;
- 作为我们修改的副作用,BIgGAn模型变得适合“截断技巧”,这是一种简单的采样技术,可以对样本种类和保真度之间的权衡进行明确、细粒度的控制;
- 我们发现特定于大规模 GAN 的不稳定性,并根据经验表征它们。 利用此分析的见解,我们证明新颖技术和现有技术的结合可以减少这些不稳定性,但完全的训练稳定性只能以极高的性能成本实现。
2.1背景
生成对抗网络(GAN)涉及生成器(G)和鉴别器(D)网络,其目的分别是将随机噪声映射到样本并区分实际和生成的样本。正式地,GAN 目标,其原始形式表述为以下两个玩家最小 - 最大问题(minmax-game)找到纳什均衡的问题:
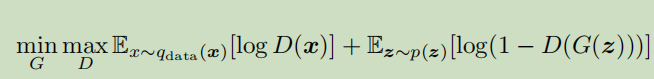
2.2具体措施与改变
BigGAN对batch_size(批量大小)、channels(通道数)、shared(是否加入共享嵌入)、Hier.(hierarchie latent space即分层潜在空间)、orthogonal(是否正交化)进行改变调优。
2.2.1规模(scaling up)
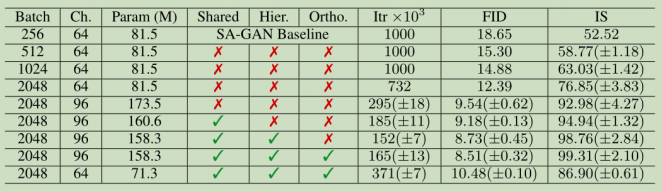
1、首先增加baseline(基线GANs)的batch_size。表 1 的第 1-4 行表明,简单地将批量大小增加 8 倍,使现有技术 IS 提高了 46%。我们推测这是每批次覆盖更多模式的结果,为两个网络提供更好的梯度。这种缩放的一个值得注意的副作用是我们的模型在更少的迭代中达到更好
的最终性能,但变得不稳定并且经历完全的训练崩溃。
2、将每层中的宽度(通道数)增加 50%,大约两倍于两个模型中的参数数量。这导致IS 进一步提高 21%,我们认为这是由于模型的容量相对于数据集的复杂性而增加。加倍深度似乎不会对 ImageNet 模型产生相同的影响,反而会降低性能。
3.用于 G 中的条件 BatchNorm 图层的类嵌入 c 包含大量权重。我们选择使用共享嵌入,而不是为每个嵌入分别设置一个层,这个嵌入会线性投影到每个层的增益和偏差(Perez et al.2018)。这降低了计算和内存成本,并将训练速度(达到给定性能所需的迭代次数)提高了 37%。接下来,我们采用分层潜在空间的变体,其中噪声向量 z 被馈送到 G 的多个层而不仅仅是初始层。这种设计背后的直觉是允许 G 使用潜在空间直接影响不同分辨率和层次结构级别的特征。对于我们的架构,通过将 z 分成每个分辨率的一个块,并将每个块连接到条件向量 c,可以很容易地实现这一
点,条件向量 c 被投射到 BatchNorm 的增益和偏差。以前的工作(Goodfellow et al.2014; Denton et al.2015)已经考虑了这个概念的变体;我们的贡献是对此设计的一个小修改。分层延迟可以提高内存和计算成本(主要通过降低第一个线性层的参数预算),提供约 4%的适度性能提升,
并将训练速度提高 18%。
2.2.2截断技巧(Truncation)
与需要通过其潜在反向传播的模型不同,GAN 可以使用任意先验 p(z),但绝大多数先前的工作选择从 N(0,I)或 U[-1,1]。我们质疑这种选择的最优性,并探索了不同的替代方案。值得注意的是,我们的最佳结果来自于使用与训练中使用的不同的潜在分布进行抽样。采用用z~N(0,I)训练的模型和从截断的正常值(其中超出范围的值被重新采样以落入该范围内)的样本 z 立即实现对 IS 和 FID(两个针对生成图片质量的评价指标) 的提升。我们将其称为截断技巧:通过重新调整幅度高于所选阈值的值来截断 z矢量导致单个样品质量的改善,但代价是整体样品品种的减少。
对于许多模型而言,由不同采样引起的分布,相比在训练中看到的会不一样,很容易造成一些麻烦。我们的一些较大模型不适合截断,在馈送截断噪声时会产生饱和伪影。为了抵消这种情况,我们试图通过将 G 调节为平滑来强制实现截断的适应性,以便 z 的整个空间映射到良好的输出样本。为此,我们转向正交正则化(Brock et al.2017),它直接强制正交性条件,我们发现最好的版本从正则化中删除了对角项,并且目标是最小化滤波器之间的成对余弦相似性,但不限制它们的范数:
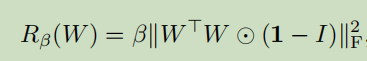
其中 1 表示一个矩阵,其中所有元素都设置为 1。我们扫描β值并选择为 1e-4,从而找到足够小的额外正则化,以提高我们的模型易于截断的可能性。 在表 1 中,我们观察到没有正交正则化时,只有 16%的模型适合截断,而有正交正则化训练时则有 60%。
3、不稳定性分析
稳定性不仅仅来自 G 或 D,而是来自他们通过对抗性训练过程的相互作用。 虽然他们的不良症状调节可用于追踪和识别不稳定性,但确保合理的调节是训练所必需的,但不足以防止最终的训练崩溃。 可以通过强烈约束 D 来强制实现稳定性,但这样做会导致性能上的巨大成本。 使用现有技术,可以通过放松这种调节并允许在训练的后期阶段发生塌陷来实现更好的最终性能,此时模型经过充分训练以获得良好的结果。
4、结论
BigGAN已经证明,对于多个类别的自然图像进行训练而训练的生成对抗网络在保真度和生成样本的多样性方面都非常有利于扩大规模。 因此,我们的模型在 ImageNet GAN 模型中创造了新的性能水平,大大提高了现有技术水平。 我们还对大规模 GAN 的训练行为进行了分析,并根据其权重的奇异值表征了它们的稳定性,并讨论了稳定性和性能之间的相互作用。
Reference:
1、本文摘自G-lab.
2、百度AIstudio的课程非常棒!百度AI复现论文课程连接.