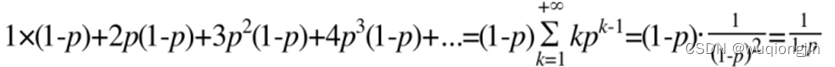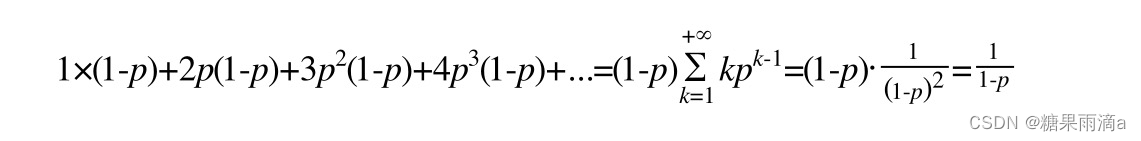一、SkipList 简介
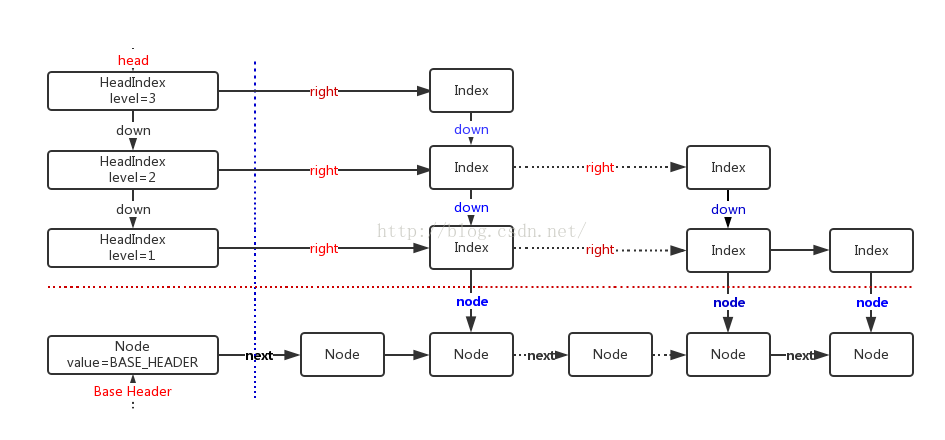
SkipList(5.0) 是zset的底层实现之一,它的数据结构定义如下:
/* ZSETs use a specialized version of Skiplists */
typedef struct zskiplistNode {sds ele; //成员对象double score; //分值struct zskiplistNode *backward; //后退指针//层struct zskiplistLevel {struct zskiplistNode *forward; //前进指针unsigned long span; //跨度} level[];
} zskiplistNode;typedef struct zskiplist {struct zskiplistNode *header, *tail; //头结点,尾节点unsigned long length; //跳表长度int level; //当前最大层高
} zskiplist;typedef struct zset {dict *dict; //跳表中的所有键值对zskiplist *zsl;
} zset;
注意以下几点:
- header指向头结点,头结点的层高始终为64层
- level保存跳表中节点层数最高值,但是
不计算头结点的层高 - length保存跳表中节点个数,但是
不包括头结点 - tail指向尾节点
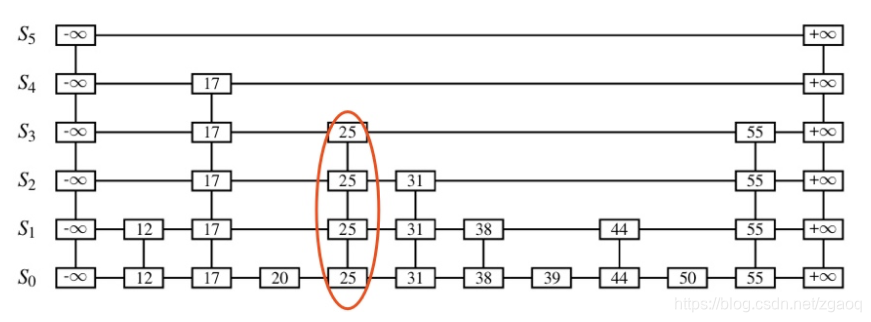
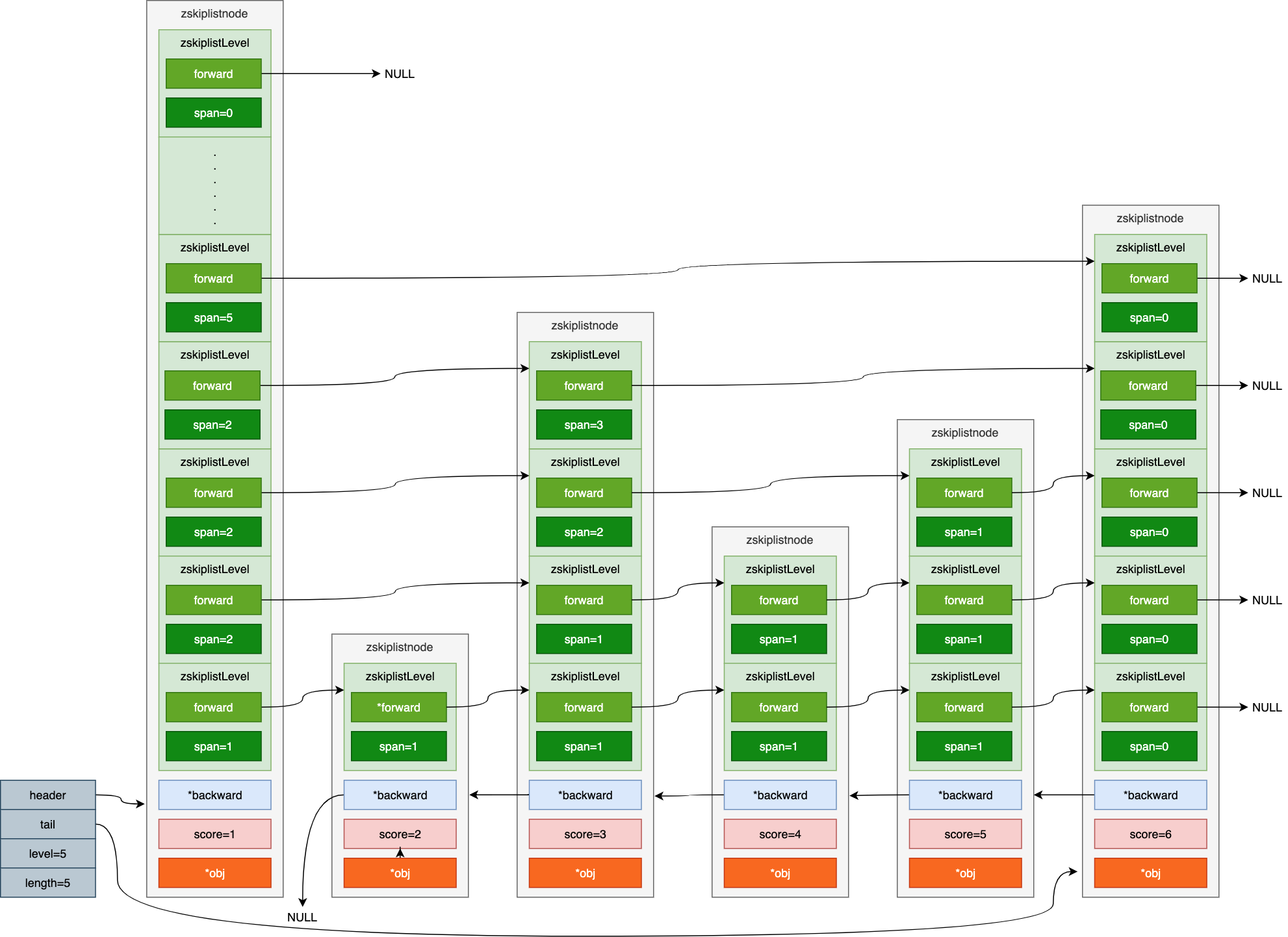
下面看一个具体的例子:
1. 查找过程
具体代码可以见:src/t_zset.c
假设要找score为5的元素。
(1)首先从头结点的最高层(也就是64层)开始查找,但是由于头指针中保存了当前跳表的最高层数,所以直接从头结点的level层开始查找即可。如果zkiplistLevel的forward为NULL,则继续向下。
(2)直到头结点中第5层的zskiplistLevel的forward不为空,它指向了第6个节点的第5层,但是这个节点的score为6,大于5,所以还要从头结点向低层继续查找。
(3)头结点中第4层的zskiplistLevel的forward指向第3个节点的第4层,这个节点的score为3,小于5,并且第一个节点的span=2,这个span的作用就是用来累加并计算最终目标节点的排名的。继续从这个节点的forward向后遍历。它的forward指向第6个节点的第4层,这个节点的score为6,大于5,所以还要从前一个score为3的节点向低层继续查找。
(4)第3个节点第3层的zskiplistLevel的forward指向第5个节点的第3层,而它的score正好为5,查找成功。并且第3个节点的span=2,再加上原来的span=2等于4,所以目标节点5的排名是4。

结合代码来看:
unsigned long zslGetRank(zskiplist *zsl, double score, sds ele) {zskiplistNode *x;unsigned long rank = 0;int i;// 从头结点开始x = zsl->header;// 从最高层开始,向下for (i = zsl->level-1; i >= 0; i--) {while (x->level[i].forward && // 如果forward指针不为空(x->level[i].forward->score < score || // 并且如果下一个节点的分数小于目标分数或者(下一个节点的分数等于目标分数并且元素值不同)(x->level[i].forward->score == score &&sdscmp(x->level[i].forward->ele,ele) <= 0))) { rank += x->level[i].span; // rank值加上当前第i层级该位置x节点的span值x = x->level[i].forward; // 切换到该层的下一个节点}/* x might be equal to zsl->header, so test if obj is non-NULL */if (x->ele && sdscmp(x->ele,ele) == 0) {return rank;}}return 0;
}
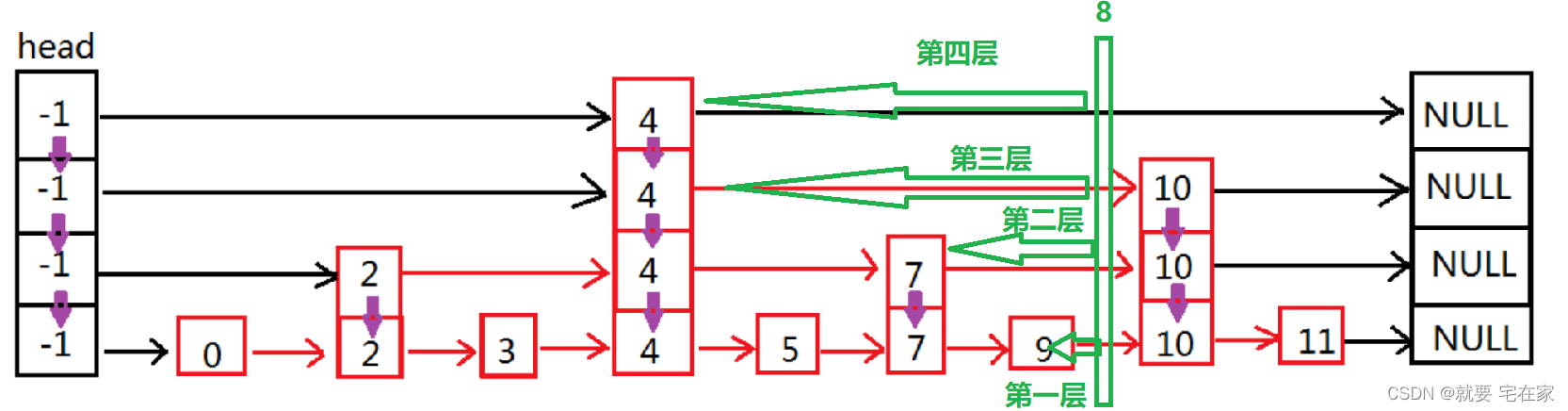
2. 插入过程
(1)首先,插入结点时,都会随机为新的节点分配一个小于64的层数,并且层数越小概率越大,层数越高概率越小。
(2)查找到小于待插入score的分数值中最大的那个节点,如果score相等,则通过value比较。
(3)在找到的节点后面插入新的节点。同时更新前面节点的跨度和跳表最大层高。
(4)更新新节点的各层的forward以及backward指针。
/* * 插入过程*/
zskiplistNode *zslInsert(zskiplist *zsl, double score, sds ele) {zskiplistNode *update[ZSKIPLIST_MAXLEVEL], *x;unsigned int rank[ZSKIPLIST_MAXLEVEL];int i, level;serverAssert(!isnan(score));x = zsl->header;for (i = zsl->level-1; i >= 0; i--) {/* store rank that is crossed to reach the insert position */rank[i] = i == (zsl->level-1) ? 0 : rank[i+1];while (x->level[i].forward &&(x->level[i].forward->score < score ||(x->level[i].forward->score == score &&sdscmp(x->level[i].forward->ele,ele) < 0))){rank[i] += x->level[i].span;x = x->level[i].forward;}//在i层找到合适的位置之后赋值给update[i]update[i] = x;}//随机为新的节点分配一个小于64的层数,并且层数越小概率越大,层数越高概率越小。level = zslRandomLevel();if (level > zsl->level) {//如果leveld大于当前最高层级,在leveld到zsl->levelzh之间再插入新的层级。for (i = zsl->level; i < level; i++) {rank[i] = 0;update[i] = zsl->header;update[i]->level[i].span = zsl->length;}zsl->level = level;}// 创建新的节点x = zslCreateNode(level,score,ele);for (i = 0; i < level; i++) {// 对于x节点的每一层更,更新它的forward指针和span值x->level[i].forward = update[i]->level[i].forward;update[i]->level[i].forward = x;x->level[i].span = update[i]->level[i].span - (rank[0] - rank[i]);update[i]->level[i].span = (rank[0] - rank[i]) + 1;}/* increment span for untouched levels */for (i = level; i < zsl->level; i++) {update[i]->level[i].span++;}x->backward = (update[0] == zsl->header) ? NULL : update[0];if (x->level[0].forward)x->level[0].forward->backward = x;elsezsl->tail = x;zsl->length++;return x;
}/* * 返回一个随机的层级*/
int zslRandomLevel(void) {int level = 1;while ((random()&0xFFFF) < (ZSKIPLIST_P * 0xFFFF))level += 1;return (level<ZSKIPLIST_MAXLEVEL) ? level : ZSKIPLIST_MAXLEVEL;
}
3. 删除过程
(1)找到待删除的节点,删除节点,更新前面节点的跨度和跳表最大层高。
(2)更新新节点的各层的forward以及backward指针。
4. 修改过程
Redis中的做法比较简单,先找到待修改的节点,直接删除,然后插入修改后的新的节点。
二、SkipList与平衡树、哈希表的比较
1. 和哈希表的比较
SkipList和各种平衡树(如AVL、红黑树等)的元素是有序排列的,而哈希表不是有序的。因此,在哈希表上只能做单个key的查找,不适宜做范围查找。所谓范围查找,指的是查找那些大小在指定的两个值之间的所有节点。
2. 和平衡树的比较
在做范围查找的时候,平衡树比skiplist操作要复杂。在平衡树上,我们找到指定范围的小值之后,还需要以中序遍历的顺序继续寻找其它不超过大值的节点。如果不对平衡树进行一定的改造,这里的中序遍历并不容易实现。而在skiplist上进行范围查找就非常简单,只需要在找到小值之后,对第1层链表进行若干步的遍历就可以实现。
平衡树的插入和删除操作可能引发子树的调整,逻辑复杂,而skiplist的插入和删除只需要修改相邻节点的指针,操作简单又快速。
从内存占用上来说,skiplist比平衡树更灵活一些。一般来说,平衡树每个节点包含2个指针(分别指向左右子树),而skiplist每个节点包含的指针数目平均为1/(1-p),具体取决于参数p的大小。如果像Redis里的实现一样,取p=1/4,那么平均每个节点包含1.33个指针,比平衡树更有优势。
查找单个key,skiplist和平衡树的时间复杂度都为O(log n),大体相当;而哈希表在保持较低的哈希值冲突概率的前提下,查找时间复杂度接近O(1),性能更高一些。所以我们平常使用的各种Map或dictionary结构,大都是基于哈希表实现的。
从算法实现难度上来比较,skiplist比平衡树要简单得多。
THE END.