1. Prophet时间序列预测框架概述
Prophet是Facebook开源的一种时间序列预测框架,旨在使时间序列分析更加容易和快速。Prophet可以处理具有多个季节性和突发事件的时间序列数据,并且在数据缺失或异常情况下仍然能够进行良好的预测。Prophet采用了一种基于加性模型的方法,将时间序列数据分解为趋势、季节性和假日三个部分,并为每个部分提供可调参数,以便用户进行更灵活的模型构建和调整。
Prophet的主要特点如下:
- 简单易用:Prophet的API简单易懂,对于初学者来说很容易上手。
- 灵活性:Prophet提供了多种参数和选项,使用户可以对模型进行微调。
- 能够处理多种季节性和突发事件:Prophet能够自适应处理多个季节性和突发事件,例如节假日等。
- 可解释性:Prophet提供了良好的可视化和解释工具,使用户能够更好地理解预测结果。
- 鲁棒性:Prophet能够处理数据缺失和异常情况,并能够产生合理的预测结果。
Prophet的应用范围非常广泛,包括销售预测、金融预测、电力负荷预测、交通预测等等。它已经成为了许多企业和数据科学家进行时间序列预测的首选框架之一。
2. prophet 算法原理及其论文
prophet 算法论文,主要是提出了一种模块化加性模型,可以进行模块自由组合,并提供了可理解的超参数配置。得益于时序预测问题的可视化和可优化方向分析成本低,从而能够让非专业分析者有能力自行用 prophet 进行机器学习和超参数优化。
2.1. 论文概况
以下是《Prophet算法:大规模预测》的概况:
- 简介
本章介绍了Prophet算法,该算法是一种基于时间序列分析的预测模型,可用于处理具有长期相关性的时间序列数据。它可以对未来一段时间内的趋势进行预测,并且可以在不同的时间尺度上进行预测。
- 数据预处理
在Prophet算法中,需要对输入的数据进行预处理,以便将其转换为适合模型训练的形式。预处理的过程包括缺失值填充、异常值处理、归一化等。
- 模型构建
Prophet算法的核心是建立一个包含多个变量的线性回归模型。该模型可以表示为:
y = β 0 + β 1 × d 1 + β 2 × d 2 + . . . + β p × d n + ε y = β_0 + β_1 × d_1 + β_2 × d_2 + ... + β_p × d_n + ε y=β0+β1×d1+β2×d2+...+βp×dn+ε
其中, y y y表示未来的观测值, d d d表示当前的观测值, n n n表示变量的数量, β β β表示回归系数, ε ε ε表示噪声项。该模型的参数可以通过最大似然估计来确定。
- 模型训练
Prophet算法的训练过程包括两个阶段:时序分解和参数学习。在时序分解阶段,需要将时间序列数据分解为不同的季节成分和趋势成分。在参数学习阶段,需要使用最小二乘法来估计回归系数。
- 模型评估
为了评估Prophet算法的预测性能,可以使用交叉验证和测试集来进行评估。交叉验证可以将数据集分成若干个子集,并在其中的一个子集上进行训练和测试。测试集可以用来评估模型的泛化能力。
- 应用案例
本章还提供了一些实际应用案例,展示了Prophet算法在不同领域的预测效果。这些案例包括股票价格、气温、销售额等。
- 结论与展望
本章总结了Prophet算法的主要特点和应用前景。未来,随着数据量的不断增加和预测需求的不断变化,Prophet算法将会得到更广泛的应用。
2.2. 原理概述
Prophet模型将时间序列分解为四个主要的成分:趋势、季节性、假日效应和噪声。其中,趋势是时间序列的长期变化趋势,季节性是周期性变化的模式,假日效应是指在特殊日期或时间段内的影响,噪声则是无法被预测的随机变化。
Prophet模型既可以使用加法模型,也可以使用乘法模型。
2.2.1. 加法模型
在Prophet模型的加法模型中,时间序列的预测值是趋势、季节性和假期效应的总和,即:
y ( t ) = g ( t ) + s ( t ) + h ( t ) + e ( t ) y(t)=g(t)+s(t)+h(t)+e(t) y(t)=g(t)+s(t)+h(t)+e(t)
其中,
- g ( t ) g(t) g(t)表示时间序列的趋势,
- s ( t ) s(t) s(t)表示时间序列的季节性,
- h ( t ) h(t) h(t)表示时间序列的假期效应,
- e ( t ) e(t) e(t)表示模型的误差项。在加法模型中,趋势、季节性和假期效应都是原始值,并且都被解释为相对于时间序列的平均水平的偏差。
2.2.2. 乘法模型
在Prophet模型的乘法模型中,时间序列的预测值是趋势、季节性和假期效应的乘积,即:
y ( t ) = g ( t ) ∗ s ( t ) ∗ h ( t ) ∗ e ( t ) y(t)=g(t)*s(t)*h(t)*e(t) y(t)=g(t)∗s(t)∗h(t)∗e(t)
其中,
- g ( t ) g(t) g(t)表示时间序列的趋势,
- s ( t ) s(t) s(t)表示时间序列的季节性,
- h ( t ) h(t) h(t)表示时间序列的假期效应,
- e ( t ) e(t) e(t)表示模型的误差项。在乘法模型中,趋势、季节性和假期效应都表示为百分比变化,并且都被解释为相对于时间序列的平均水平的偏差。
加法模型和乘法模型都有各自的优缺点,适用于不同类型的时间序列。通常情况下,加法模型适用于时间序列的趋势和季节性与数据规模无关的情况,例如气温和降雨量;而乘法模型适用于时间序列的趋势和季节性与数据规模相关的情况,例如商品销售量和股票价格。在使用Prophet模型进行时间序列预测时,需要根据具体情况选择合适的模型。
3. 安装
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple prophet
prophet自v1.1版本,需要在 Python 3.7及以上支持。
4. 快速开始
Prophet的输入始终是一个包含两列的数据帧:ds和y。
- ds(日期戳)列应为Pandas所期望的格式,理想情况下,YYYY-MM-DD表示日期,YYYY-MM-DD HH:MM:SS表示时间戳。
- y列必须是数字,并且表示我们希望预测的度量。
import pandas as pd
from prophet import Prophet
from prophet.plot import add_changepoints_to_plot
import numpy as np# 读取数据源 df,略
live_df = df[['recordtime','live']].copy()
按Prophet规则,输入数据列名转换为ds和y。
live_df = live_df.rename(columns={'recordtime':'ds','live':'y'})
定义节假日:
# 定义节假日
chinese_holiday = pd.DataFrame({'holiday': 'Lunar_festivals','ds': pd.to_datetime(['2023-01-21', '2023-01-22', '2023-01-23','2023-01-24', '2023-01-25', '2023-01-26','2023-01-27', '2023-04-05', '2023-06-22','2023-06-23', '2023-06-24', '2023-09-29','2023-09-30']),'lower_window': 0,'upper_window': 1,
})
china_holiday = pd.DataFrame({'holiday': 'china','ds': pd.to_datetime(['2023-01-01', '2023-01-02', '2023-05-01','2023-05-02', '2023-05-03', '2023-10-01','2023-10-02', '2023-10-03', '2023-10-04','2023-10-05', '2023-10-06']),'lower_window': 0,'upper_window': 1,
})
holidays = pd.concat((chinese_holiday, china_holiday))
内置假日:
可以使用add_country_holidays方法(Python)使用特定于国家/地区的内置假日集合。指定了国家名称,然后除了通过上述假日参数指定的任何假日外,还将包括该国家的主要假日。
我们通过实例化一个新的Prophet对象来拟合模型。将任何预测程序的设置传递给构造函数。然后,您调用其fit方法并传入历史数据框。拟合应该需要1-5秒的时间。
model = Prophet(holidays=holidays)
model.fit(live_df)
在一个包含列ds的dataframe上进行预测,该列包含需要进行预测的日期。您可以使用helper方法Prophet.make_future_dataframe()来获得扩展到未来指定时间(例如本文中指定48个时间点周期,间隔30分钟)的dataframe。默认情况下,它还将包括历史数据中的日期,因此我们将看到模型的拟合情况。
future = model.make_future_dataframe( periods=48, freq='30min', include_history=False)
future.tail(48)
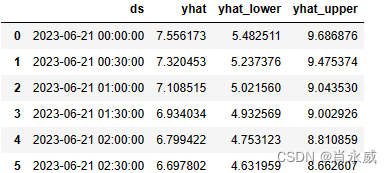
预测方法将为未来每一行分配一个名为yhat的预测值。如果您传入历史日期,它将提供样本内拟合。这里的forecast对象是一个包含预测值(列yhat)以及组件和不确定性区间列的新dataframe。
forecast = m.predict(future)
forecast[['ds', 'yhat', 'yhat_lower', 'yhat_upper']].tail(48)
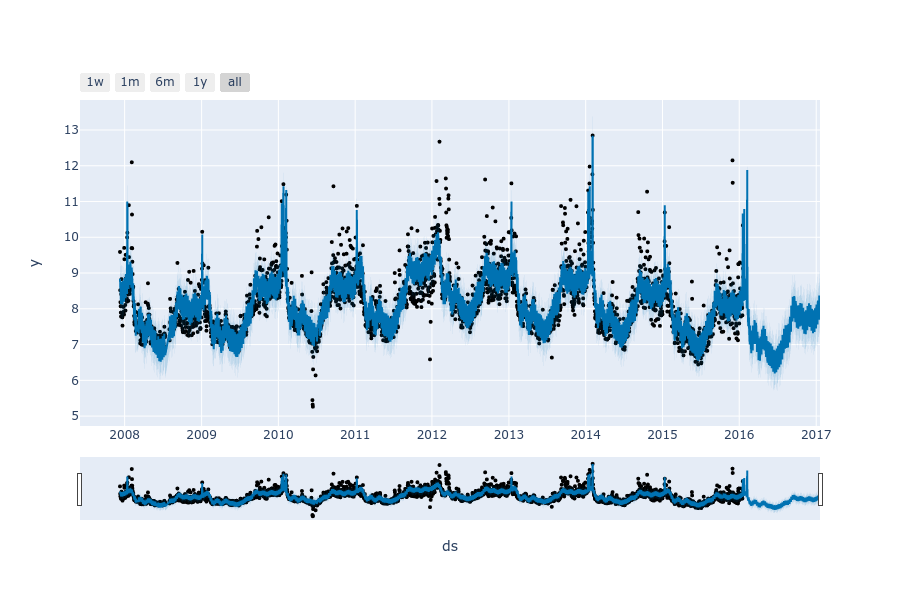
可以通过调用Prophet.plot方法并传入预测数据帧来绘制预测图。
fig1 = model.plot(ff)
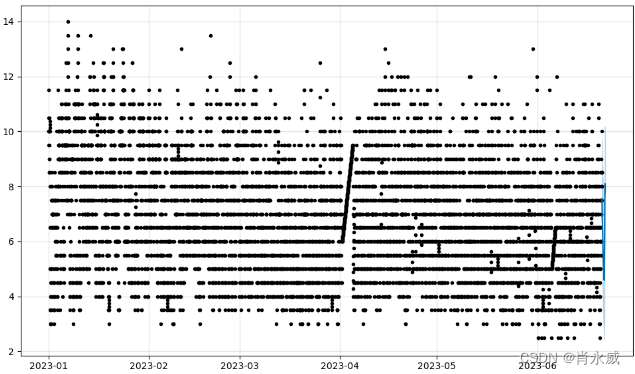
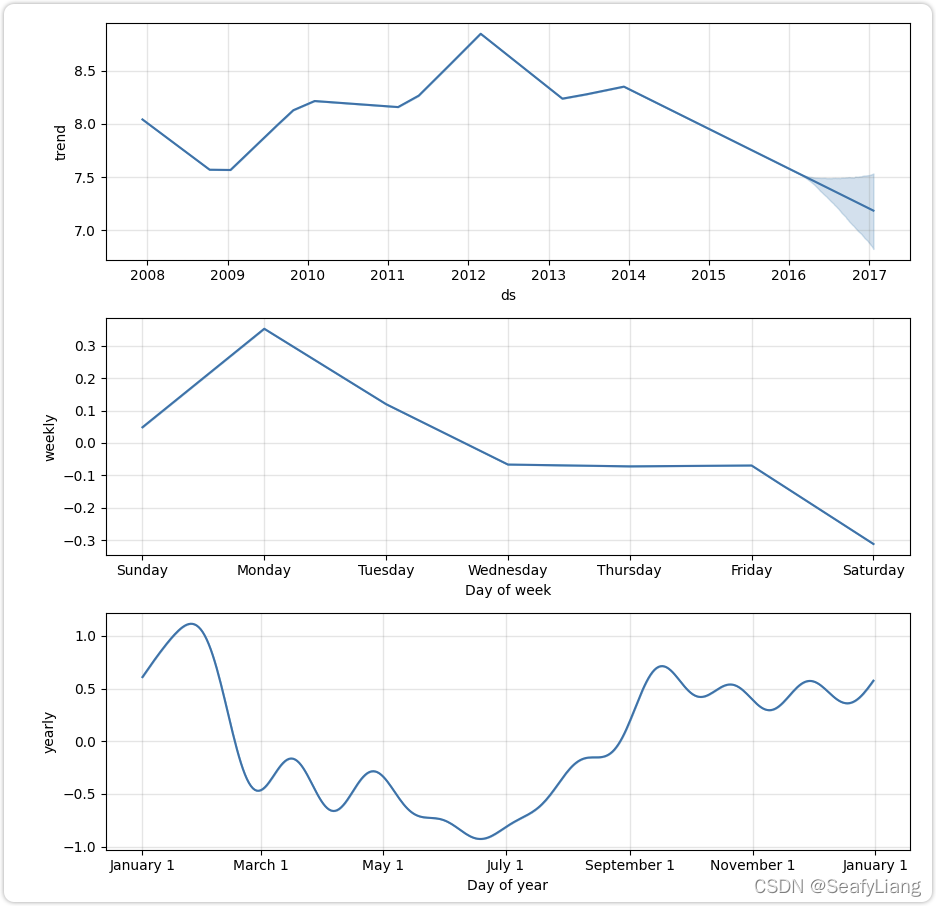
如果您想查看预测组件,可以使用Prophet.plot_components方法。默认情况下,您将看到时间序列的趋势、年度季节性和每周季节性。如果你包括假期,你也会在这里看到。
fig = model.plot_components(forecast)
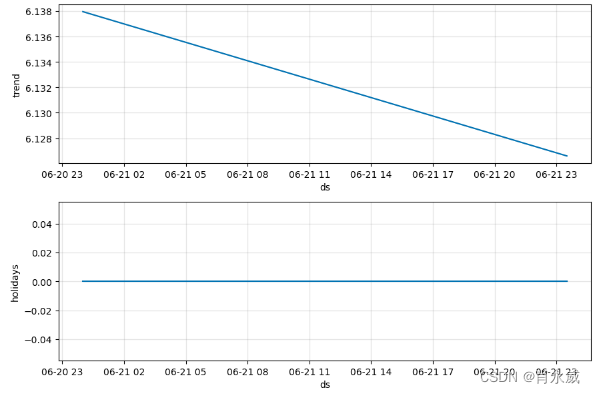
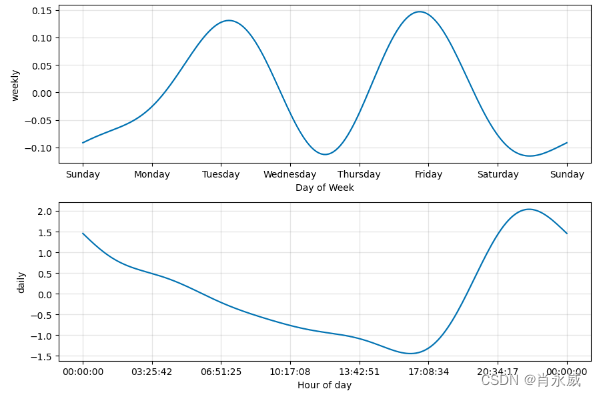
其中, 趋势参数。
| 参数 | 描述 |
|---|---|
| growth | 是指模型的趋势函数,目前取值有2种,linear和logistic |
| changepoints | 是指一个特殊的日期,在这个日期,模型的趋势将发生改变。而changepoints是指潜在changepoint的所有日期,如果不指明则模型将自动识别。 |
| n_changepoints | 最大的Changepoint的数量。如果changepoints不为None,则本参数不生效。 |
| changepoint_range | 是指changepoint在历史数据中出现的时间范围,与n_changeponits配合使用,changepoint_range决定了changepoint能出现在离当前时间最近的时间点,changepont_range越大,changepoint可以出现的距离现在越近。当指定changepoints时,本参数不生效 |
| changepoint_prior_scale | 设定自动突变点选择的灵活性,值越大越容易出现changepoint |
关于预测组件和图像分析,将在后续博文中展开。
5. 总结
5.1. 非专业开发人员容易快速入门
Prophet使用起来,比较简便,屏蔽了很多时序模型的统计学知识点。
5.2. 速度快
速度快有两个含义,一是应用入手快,二是模型拟合速度快。
5.3. Prophet和statsmodels中的ARMA对比
Prophet和statsmodels都是时间序列预测的工具,但它们的设计思路略有不同。Prophet是一种基于加性模型的预测方法,而statsmodels则是一个更加通用的时间序列分析库,提供了多种建模方法,包括ARMA、ARIMA、VAR等。下面是它们之间的一些比较:
-
适用性:Prophet旨在解决商业和社会需求中的时间序列问题,例如销售预测、天气预测等。而statsmodels是一个更加通用的时间序列分析工具,适用于广泛的统计分析问题。
-
精度:Prophet的设计使其能够在短时间内生成精确的预测结果。相反,statsmodels可能需要更多的参数调整和模型测试来生成准确的预测结果。
-
灵活性:Prophet的设计让它非常易于使用,但这也导致了一定的限制。Prophet只能用于时间序列预测,无法进行其他类型的时间序列分析。相反,statsmodels提供了更多的灵活性和可扩展性,用户可以通过自定义模型和拟合方法来解决不同类型的问题。
-
可解释性:Prophet的输出包含了详细的组成部分和分解结果,使用户能够更好地理解模型预测的基础。相反,statsmodels的输出可能需要更多的统计知识才能理解。
总之,Prophet和statsmodels各有优点,在不同的场景下可能会更适合使用其中的一种。如果您需要进行商业或社会需求的时间序列预测,或者您不熟悉时间序列分析的统计知识,那么Prophet是一个不错的选择。如果您需要进行更加通用的时间序列分析,或者您需要自定义模型和拟合方法来解决特定问题,那么statsmodels可能更适合您的需求。
参考:
数学人生. Facebook 时间序列预测算法 Prophet 的研究. 知乎. 2018.12
恒沙数. 容易上手的时间序列分析2:Prophet模型. 知乎. 2022.07
郭飞. 【读论文】prophet. 2019.10
悟乙己. python | prophet的案例实践:趋势检验、突变点检验等. CSDN博客. 2022.07
福禄网络研发团队.怎么训练出一个NB的Prophet模型. 博客园 2020.07
muzhen. prophet 论文阅读笔记. 知乎. 2022.12
模型视角. 时间序列预测Prophet模型及Python实现. 知乎. 2023.03
数学人生. Facebook 时间序列预测算法 Prophet 的研究. 知乎. 2018.12
https://facebook.github.io/prophet/docs/quick_start.html#python-api
https://github.com/facebook/prophet