目录
一、Systemd概述
二、Systemd优势
2.1兼容性
2.2启动速度
2.3systemd 提供按需启动能力
2.4采用 linux 的 cgroups 跟踪和管理进程的生命周期
2.5启动挂载点和自动挂载的管理
2.6实现事务性依赖关系管理
2.7日志服务
2.8 依赖关系
2.9systemd 事务
三、unit(单元)
四、systemd和systemctl
一、Systemd概述
关于 systemd 的起源,首先要从 Linux 的 init 程序说起。Linux 系统在启动过程中,内核完成初始化以后,由内核第一个启动的程序便是 init 程序,路径为 /sbin/init(为一个软连接,链接到真实的 init 进程),其 PID 为1,它为系统里所有进程的“祖先”,Linux 中所有的进程都由 init 进程直接或间接进行创建并运行,init 进程以守护进程的方式存在,负责组织与运行系统的相关初始化工作,让系统进入定义好的运行模式,如命令行模式或图形界面模式。
init 程序的发展,大体上可分为三个阶段:sysvinit->upstart->systemd,根据 init 进程的发展特性,可以简单理解为如下:
sysvinit:init 系统通过 shell 脚本以串行的方式启动系统服务,下一个进程必须等待上一个进程启动完成后才能开始启动,因此系统启动的过程比较慢。
upstart:在 sysvinit 的基础上,把一些没有关联的程序并行启动,以提高启动的速度,但是存在依赖关系的程序仍然为串行启动。
systemd:通过套接字激活的机制,让所有无论有无依赖关系的程序全部并行启动,并且仅按照系统启动的需要启动相应的服务,最大化提高开机启动速度。
systemd 是 linux 系统中最新的初始化系统(init),它主要的设计目标是克服 sysvinit 固有的缺点,提高系统的启动速度。systemd 和 ubuntu 的 upstart 是竞争对手,但是时至今日 ubuntu 也采用了 systemd,所以 systemd 在竞争中胜出,大有一统天下的趋势。目前主流的系统中,systemd 的守护进程主要分为系统态(system)与用户态(user),可以在 ps -ef 中看到 systemd 的守护进程,如下:


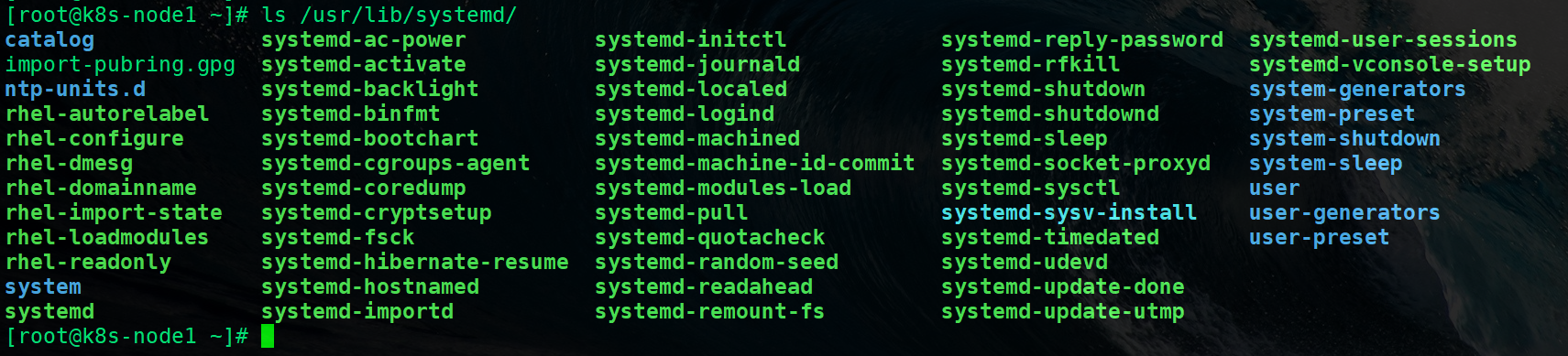
PID 为1的进程/sbin/init 即是 system 态的 systemd,它为一个软链接,指向真实的 systemd 路径,在操作系统中一般放在/usr/lib/systemd/目录:

systemd 为进程服务集合的总称,它包含许多的进程,负责控制、管理系统的资源,其中包括 systemd-login,负责用户登录相关信息的创建、修改与删除;systemd-sleep 控制系统的休眠、睡眠状态切换等等。在优麒麟操作系统下,它们主要集中在/usr/lib/systemd/文件目录
二、Systemd优势
2.1兼容性
systemd 提供了和 sysvinit 兼容的特性。系统中已经存在的服务和进程无需修改。这降低了系统向 systemd 迁移的成本,使得 systemd 替换现有初始化系统成为可能。
2.2启动速度
systemd 提供了比 upstart 更激进的并行启动能力,采用了 socket / D-Bus activation 等技术启动服务。一个显而易见的结果就是:更快的启动速度。为了减少系统启动时间,systemd 的目标是:
- 尽可能启动更少的进程
- 尽可能将更多进程并行启动
2.3systemd 提供按需启动能力
当 sysvinit 系统初始化的时候,它会将所有可能用到的后台服务进程全部启动运行。并且系统必须等待所有的服务都启动就绪之后,才允许用户登录。这种做法有两个缺点:首先是启动时间过长,其次是系统资源浪费。
某些服务很可能在很长一段时间内,甚至整个服务器运行期间都没有被使用过。比如 CUPS,打印服务在多数服务器上很少被真正使用到。您可能没有想到,在很多服务器上 SSHD 也是很少被真正访问到的。花费在启动这些服务上的时间是不必要的;同样,花费在这些服务上的系统资源也是一种浪费。
systemd 可以提供按需启动的能力,只有在某个服务被真正请求的时候才启动它。当该服务结束,systemd 可以关闭它,等待下次需要时再次启动它。
这有点类似于以前系统中的 inetd,并且有很多文章介绍如何把过去 inetd 管理的服务迁移到 systemd。
2.4采用 linux 的 cgroups 跟踪和管理进程的生命周期
systemd 利用了 Linux 内核的特性即 cgroups 来完成跟踪的任务。当停止服务时,通过查询 cgroups ,systemd 可以确保找到所有的相关进程,从而干净地停止服务。
cgroups 已经出现了很久,它主要用来实现系统资源配额管理。cgroups 提供了类似文件系统的接口,使用方便。当进程创建子进程时,子进程会继承父进程的 cgroups 。因此无论服务如何启动新的子进程,所有的这些相关进程都会属于同一个 cgroups ,systemd 只需要简单地遍历指定的 cgroups 即可正确地找到所有的相关进程,将它们一一停止即可。
2.5启动挂载点和自动挂载的管理
传统的 linux 系统中,用户可以用 /etc/fstab 文件来维护固定的文件系统挂载点。这些挂载点在系统启动过程中被自动挂载,一旦启动过程结束,这些挂载点就会确保存在。这些挂载点都是对系统运行至关重要的文件系统,比如 HOME 目录。和 sysvinit 一样,Systemd 管理这些挂载点,以便能够在系统启动时自动挂载它们。systemd 还兼容 /etc/fstab 文件,您可以继续使用该文件管理挂载点。
有时候用户还需要动态挂载点,比如打算访问 DVD 或者 NFS 共享的内容时,才临时执行挂载以便访问其中的内容,而不访问光盘时该挂载点被取消(umount),以便节约资源。传统地,人们依赖 autofs 服务来实现这种功能。
systemd 内建了自动挂载服务,无需另外安装 autofs 服务,可以直接使用 systemd 提供的自动挂载管理能力来实现 autofs 的功能。
2.6实现事务性依赖关系管理
系统启动过程是由很多的独立工作共同组成的,这些工作之间可能存在依赖关系,比如挂载一个 NFS 文件系统必须依赖网络能够正常工作。systemd 虽然能够最大限度地并发执行很多有依赖关系的工作,但是类似"挂载 NFS"和"启动网络"这样的工作还是存在天生的先后依赖关系,无法并发执行。对于这些任务,systemd 维护一个"事务一致性"的概念,保证所有相关的服务都可以正常启动而不会出现互相依赖,以至于死锁的情况。
2.7日志服务
systemd 自带日志服务 journald,该日志服务的设计初衷是克服现有的 syslog 服务的缺点。比如:
- syslog 不安全,消息的内容无法验证。每一个本地进程都可以声称自己是 Apache PID 4711,而 syslog 也就相信并保存到磁盘上。
- 数据没有严格的格式,非常随意。自动化的日志分析器需要分析人类语言字符串来识别消息。一方面此类分析困难低效;此外日志格式的变化会导致分析代码需要更新甚至重写。
systemd journal 用二进制格式保存所有日志信息,用户使用 journalctl 命令来查看日志信息。无需自己编写复杂脆弱的字符串分析处理程序。
systemd journal 的优点如下:
简单性:代码少,依赖少,抽象开销最小。
零维护:日志是除错和监控系统的核心功能,因此它自己不能再产生问题。举例说,自动管理磁盘空间,避免由于日志的不断产生而将磁盘空间耗尽。
移植性:日志文件应该在所有类型的 Linux 系统上可用,无论它使用的何种 CPU 或者字节序。
性能:添加和浏览日志非常快。
最小资源占用:日志数据文件需要较小。
统一化:各种不同的日志存储技术应该统一起来,将所有的可记录事件保存在同一个数据存储中。所以日志内容的全局上下文都会被保存并且可供日后查询。例如一条固件记录后通常会跟随一条内核记录,最终还会有一条用户态记录。重要的是当保存到硬盘上时这三者之间的关系不会丢失。syslog 将不同的信息保存到不同的文件中,分析的时候很难确定哪些条目是相关的。
扩展性:日志的适用范围很广,从嵌入式设备到超级计算机集群都可以满足需求。
安全性:日志文件是可以验证的,让无法检测的修改不再可能。
在了解了 systemd 的种种优势之后让我们开始认识它的一些基本概念。
2.8 依赖关系
虽然 systemd 将大量的启动工作解除了依赖,使得它们可以并发启动。但还是存在有些任务,它们之间存在天生的依赖,不能用"套接字激活"(socket activation)、D-Bus activation 和 autofs 三大方法来解除依赖。比如:挂载必须等待挂载点在文件系统中被创建;挂载也必须等待相应的物理设备就绪。为了解决这类依赖问题,systemd 的配置单元之间可以彼此定义依赖关系。Systemd 用配置单元定义文件中的关键字来描述配置单元之间的依赖关系。比如:unit A 依赖 unit B,可以在 unit B 的定义中用"require A"来表示。这样 systemd 就会保证先启动 A 再启动 B。
2.9systemd 事务
systemd 能保证事务完整性。Systemd 的事务概念和数据库中的有所不同,主要是为了保证多个依赖的配置单元之间没有环形引用。比如存在 unit A、B、C,假如它们的依赖关系如下(此图来自互联网):
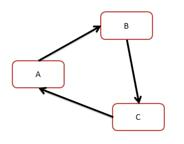
存在循环依赖,那么 systemd 将无法启动任意一个服务。此时 systemd 将会尝试解决这个问题,因为配置单元之间的依赖关系有两种:required 是强依赖;want 则是弱依赖,systemd 将去掉 wants 关键字指定的依赖看看是否能打破循环。如果无法修复,systemd 会报错。systemd 能够自动检测和修复这类配置错误,从而极大地减轻了管理员的排错负担。
三、unit(单元)
系统初始化需要做的事情非常多。需要启动后台服务,比如启动 ssh 服务;需要做配置工作,比如挂载文件系统。这个过程中的每一步都被 systemd 抽象为一个配置单元,即 unit。可以认为一个服务是一个配置单元,一个挂载点是一个配置单元,一个交换分区的配置是一个配置单元等等。systemd 将配置单元归纳为以下一些不同的类型。然而,systemd 正在快速发展,新功能不断增加。所以配置单元类型可能在不久的将来继续增加。下面是一些常见的 unit 类型:
service :代表一个后台服务进程,比如 MySQLd。这是最常用的一类。
socket :此类配置单元封装系统和互联网中的一个套接字 。当下,systemd 支持流式、数据报和 连续包的 AF_INET、AF_INET6、AF_UNIX socket 。每一个套接字配置单元都有一个相应的服务配置单元 。相应的服务在第一个"连接"进入套接字时就会启动(例如:nscd.socket 在有新连接后便启动 nscd.service)。
device :此类配置单元封装一个存在于 Linux 设备树中的设备。每一个使用 udev 规则标记的设备都将会在 systemd 中作为一个设备配置单元出现。
mount :此类配置单元封装文件系统结构层次中的一个挂载点。Systemd 将对这个挂载点进行监控和管理。比如可以在启动时自动将其挂载;可以在某些条件下自动卸载。Systemd 会将 /etc/fstab 中的条目都转换为挂载点,并在开机时处理。
automount :此类配置单元封装系统结构层次中的一个自挂载点。每一个自挂载配置单元对应一个挂载配置单元 ,当该自动挂载点被访问时,systemd 执行挂载点中定义的挂载行为。
swap:和挂载配置单元类似,交换配置单元用来管理交换分区。用户可以用交换配置单元来定义系统中的交换分区,可以让这些交换分区在启动时被激活。
target :此类配置单元为其他配置单元进行逻辑分组。它们本身实际上并不做什么,只是引用其他配置单元而已。这样便可以对配置单元做一个统一的控制。这样就可以实现大家都已经非常熟悉的运行级别概念。比如想让系统进入图形化模式,需要运行许多服务和配置命令,这些操作都由一个个的配置单元表示,将所有这些配置单元组合为一个目标(target),就表示需要将这些配置单元全部执行一遍以便进入目标所代表的系统运行状态。 (例如:multi-user.target 相当于在传统使用 SysV 的系统中运行级别 5)
timer:定时器配置单元用来定时触发用户定义的操作,这类配置单元取代了 atd、crond 等传统的定时服务。
snapshot :与 target 配置单元相似,快照是一组配置单元。它保存了系统当前的运行状态。
path:文件系统中的一个文件或目录。
scope:用于 cgroups,表示从 systemd 外部创建的进程。
slice:用于 cgroups,表示一组按层级排列的单位。slice 并不包含进程,但会组建一个层级,并将 scope 和 service 都放置其中。
每个配置单元都有一个对应的配置文件,系统管理员的任务就是编写和维护这些不同的配置文件,比如一个 MySQL 服务对应一个 mysql.service 文件。这种配置文件的语法非常简单,用户不需要再编写和维护复杂的系统脚本了。
下面是 docker.service
[root@k8s-master ~]# cat /usr/lib/systemd/system/docker.service
[Unit]
Description=Docker Application Container Engine
Documentation=https://docs.docker.com
BindsTo=containerd.service
After=network-online.target firewalld.service containerd.service
Wants=network-online.target
Requires=docker.socket[Service]
Type=notify
# the default is not to use systemd for cgroups because the delegate issues still
# exists and systemd currently does not support the cgroup feature set required
# for containers run by docker
ExecStart=/usr/bin/dockerd -H fd:// --containerd=/run/containerd/containerd.sock
ExecReload=/bin/kill -s HUP $MAINPID
TimeoutSec=0
RestartSec=2
Restart=always# Note that StartLimit* options were moved from "Service" to "Unit" in systemd 229.
# Both the old, and new location are accepted by systemd 229 and up, so using the old location
# to make them work for either version of systemd.
StartLimitBurst=3# Note that StartLimitInterval was renamed to StartLimitIntervalSec in systemd 230.
# Both the old, and new name are accepted by systemd 230 and up, so using the old name to make
# this option work for either version of systemd.
StartLimitInterval=60s# Having non-zero Limit*s causes performance problems due to accounting overhead
# in the kernel. We recommend using cgroups to do container-local accounting.
LimitNOFILE=infinity
LimitNPROC=infinity
LimitCORE=infinity# Comment TasksMax if your systemd version does not supports it.
# Only systemd 226 and above support this option.
TasksMax=infinity# set delegate yes so that systemd does not reset the cgroups of docker containers
Delegate=yes# kill only the docker process, not all processes in the cgroup
KillMode=process[Install]
WantedBy=multi-user.target- Unit 段:此部分所有 Unit 文件通用,用来定义 Unit 的元数据、配置以及与其他 Unit 的关系,Description 描述 Unit 文件信息,Documentation 表示指定服务的文档,Condition 表示服务启动的条件,有些 Unit 还包含 wants、before、after、require 字段,这些表示服务的一个依赖关系。
- Install 段:此部分所有 Unit 文件通用,通常指定运行目标的 target,使得服务在系统启动时自动运行。Wantedby、RequiredBy 与 Unit 段 Wants 字段类似,表示依赖关系,Alias 字段表示启动运行时使用的别名。
- service 段:服务(Service)类型的 Unit 文件特有的字段,用于定义服务的具体管理和执行动作。其中包括 Type 字段,定义进程的行为,例如使用 fork()启动,使用 dbus 启动等等;ExecStart、ExecStartPre、ExecStartPos、ExecReload、ExecStop 分别表示启动当前服务执行的命令、启动当前服务之前执行的命令、启动当前服务之后启动的命令、重启当前服务时执行的命令、停止当前服务时执行的命令。以上图为例,启动蓝牙服务所需要执行的命令为/usr/lib/bluetooth/bluetoothd。
对于systemd的所有详细启动顺序情况,我们可以使用systemd本身自带的systemd-anlyze,它是一个分析启动性能的工具,
[root@k8s-master1 ~]# systemd-analyze --help
systemd-analyze [OPTIONS...] {COMMAND} ...Profile systemd, show unit dependencies, check unit files.-h --help Show this help--version Show package version--no-pager Do not pipe output into a pager--system Operate on system systemd instance-H --host=[USER@]HOST Operate on remote host-M --machine=CONTAINER Operate on local container--order Show only order in the graph--require Show only requirement in the graph--from-pattern=GLOB Show only origins in the graph--to-pattern=GLOB Show only destinations in the graph--fuzz=SECONDS Also print also services which finished SECONDSearlier than the latest in the branch--man[=BOOL] Do [not] check for existence of man pagesCommands:time Print time spent in the kernelblame Print list of running units ordered by time to initcritical-chain Print a tree of the time critical chain of unitsplot Output SVG graphic showing service initializationdot Output dependency graph in dot(1) formatset-log-level LEVEL Set logging threshold for systemddump Output state serialization of service managerverify FILE... Check unit files for correctness
系统启动时间
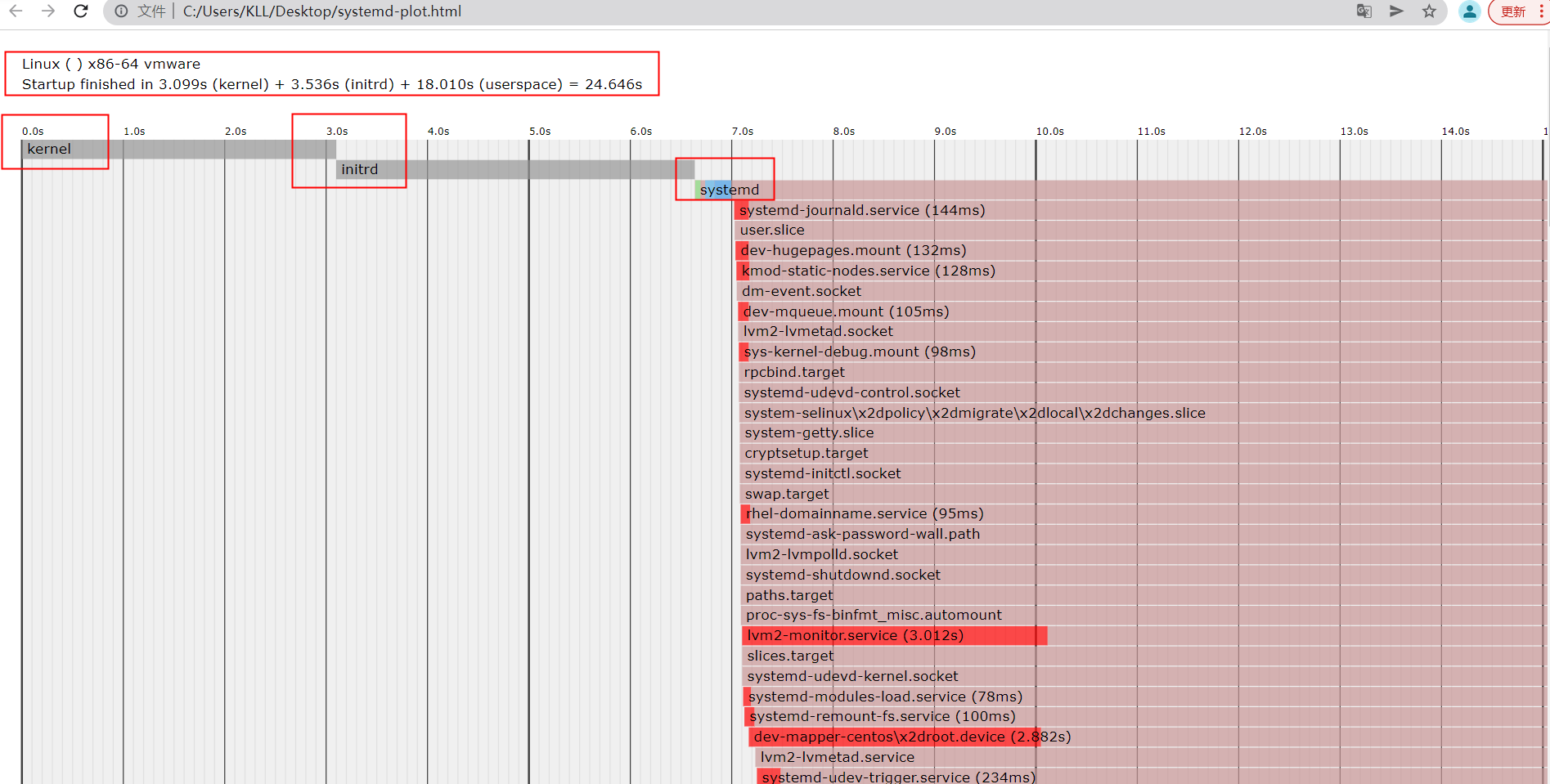
[root@k8s-master ~]# systemd-analyze
Startup finished in 3.099s (kernel) + 3.536s (initrd) + 18.010s (userspace) = 24.646s
[root@k8s-master ~]# 打印上次开机时的所有服务,并显示服务耗时
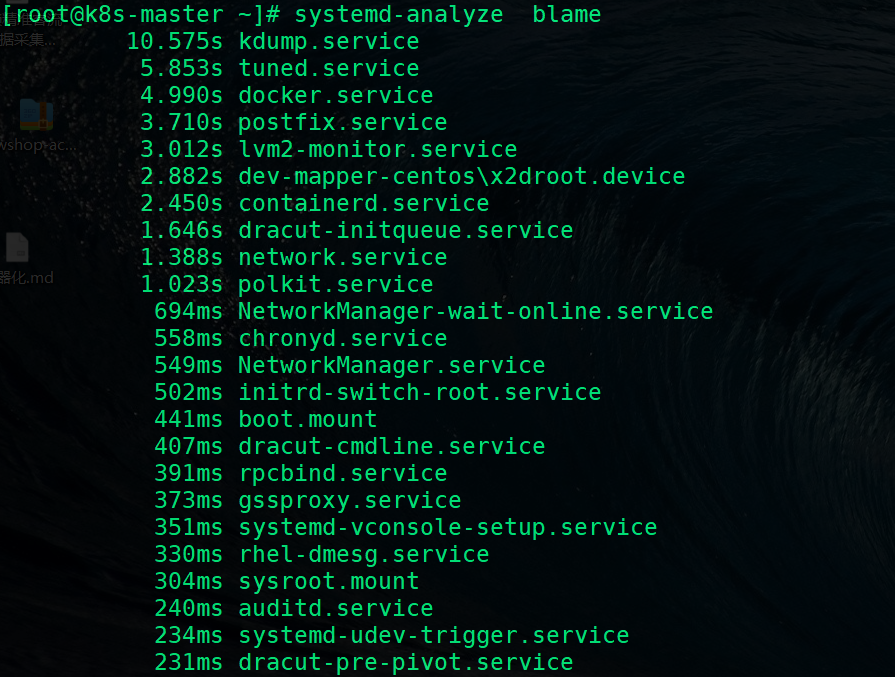
给出的树形关键路径就是该unit的最长耗时路径.
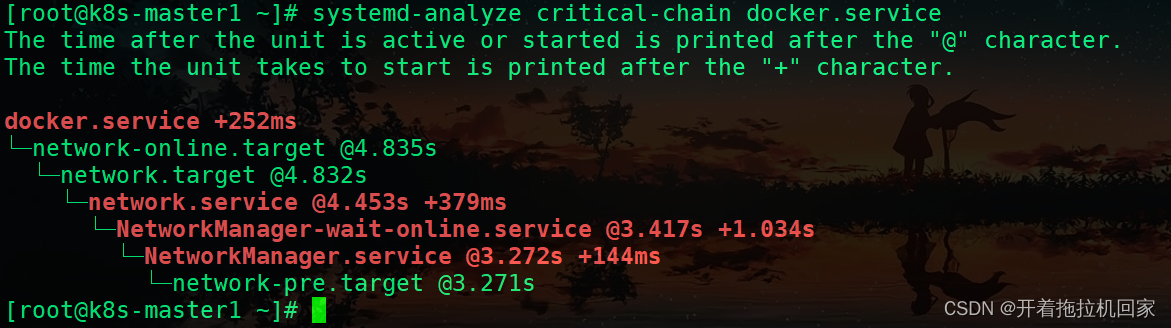
systemd-analyze plot > boot.svg
详细的systemd启动流程,直到graphical.target. 将boot.svg拖入浏览器显示如下
四、systemd和systemctl
提到systemctl就一定需要知道systemd,因为Linux 服务管理有两种方式service和systemctl。而systemd是Linux系统最新的初始化系统(init),作用是提高系统的启动速度,尽可能启动较少的进程,尽可能更多进程并发启动,systemd对应的进程管理命令就是systemctl。值得一提的是,systemctl命令兼容了service哦。
这里咱们梳理一下systemd这个启动服务管理机制有哪些好处(也就是使用systemctl相关命令的好处啦)。
平行处理所有服务,加速开机流程:旧的init启动脚本(System V的那个)是“一项一项任务依序启动”的模式,因此不相依的服务也是得要一个一个的等待。而systemd可以让所有的服务同时启动,毕竟目前我们的硬件主机系统与操作系统几乎都支持多核心架构,因此你会发现到,系统启动的速度变快了;
一经请求就响应的on-demand启动方式:systemd仅有一只systemd服务搭配systemctl指令进行处理,无须其他额外的指令来支持。不像systemV还要init,chkconfig,service...等等指令。此外,systemd由于常驻内存,因此任何请求(on-demand)都可以立即处理后续的daemon启动的任务;
服务关联性的自我检查:由于systemd可以自行进行服务关联性的检查,因此如果B服务的启动前提是A服务,那当你在没有启动A服务的情况下仅手动启动B服务时,systemd会自动帮你启动A服务;
根据daemon功能分类:systemd旗下管理的服务非常多,为了理清所有服务的功能,因此,首先systemd先定义所有的服务为一个服务单位(这里单位叫“unit”,挺重要的,后面详细说),并将该unit分类到不同的服务类型(type)中。systemd将服务单位(unit)区分为service,socket,target,path,snapshot,timer等多种不同的类型(type);
将多个daemons集合成为一个群组:systemd将许多的功能集合成为一个所谓的target项目,这个项目主要用于设计操作环境的创建,所以集合了许多的daemons(执行某个target就是执行多个daemon);
向下兼容容旧有的init服务脚本:基本上,systemd是可以兼容init的启动脚本,因此,旧的init启动脚本也能够通过systemd来管理,当然了,这里仅限于不使用systemd的某些高级功能;
————————————————
reference:
干货分享 | Systemd 技术原理&实践(上) - 知乎
关于 systemd 的初步理解_Linux教程_Linux公社-Linux系统门户网站




![[2020.1.10]systemd介绍](https://img-blog.csdnimg.cn/20210412223013437.png)