Spark大数据开发技术简介
- 轻量级的内存集群计算平台
文章目录
- Spark大数据开发技术简介
- 历史沿革
- Spark的优点
- 对比
- Apache Spark堆栈中的不同组件
- 基本原理
- 架构组成
- 部署和体系结构
- Spark运行模式
- 页面

历史沿革
- Apache Spark是一个围绕速度、易用性和复杂分析构建的大数据处理框架
- 最初在2009年由加州大学伯克利分校的AMPLab开发,并于2010年成为Apache的开源项目之一,与Hadoop和Storm等其他大数据和MapReduce技术相比,Spark有如下优势:
- Spark提供了一个全面、统一的框架用于管理各种有着不同性质(文本数据、图表数据等)的数据集和数据源(批量数据或实时的流数据)的大数据处理的需求
- 官方资料介绍Spark可以将Hadoop集群中的应用在内存中的运行速度提升100倍,甚至能够将应用在磁盘上的运行速度提升10倍
Spark的优点
传统MapReduce的不足
- 在整个过程中,中间结果会借助磁盘传递,因此大量的Map-Reduced作业都受限于IO。

对比
| Spark | Hadoop | Storm | |
|---|---|---|---|
| 处理模型 | Batch + Stream | Batch | Stream |
| 实时性 | 较快 | 慢 | 快 |
| 容错性 | 好 | 一般 | 较好 |
| 实现语言 | Scala | Java | Java + Clojure |
| 存储介质 | 内存 + 磁盘 | 磁盘 | 内存 |
| 生态环境 | 较好 | 好 | 较差 |
| 适用场景 | 机器学习 | 离线数据分析 | 实时消息流 |
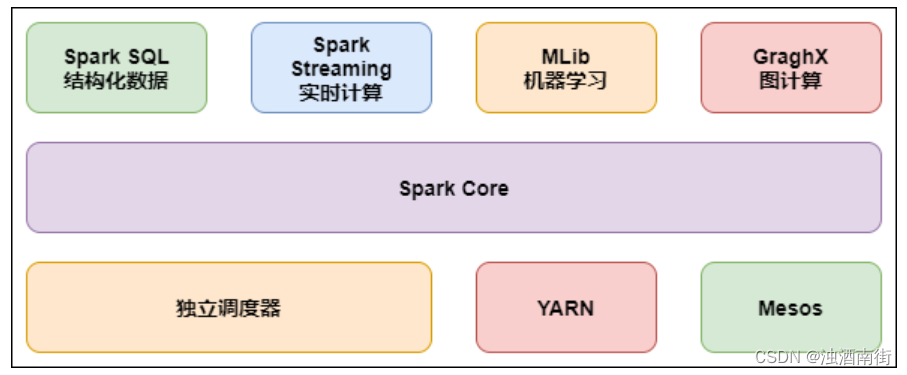
Apache Spark堆栈中的不同组件

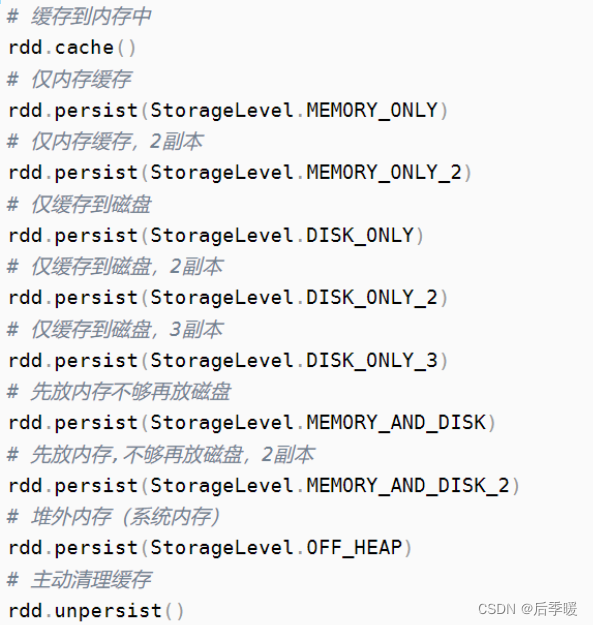
基本原理
-
Spark Core
包含Spark的基本功能;尤其是定义RDD的API、操作以及这两者上的动作。其他Spark的库都是构建在RDD和Spark Core之上的 -
Spark SQL
提供通过Apache Hive的SQL变体Hive查询语言(HiveQL)与Spark进行交互的API。每个数据库表被当做一个RDD,Spark SQL查询被转换为Spark操作。 -
Spark Streaming
对实时数据流进行处理和控制。Spark Streaming允许程序能够像普通RDD一样处理实时数据 -
Mllib
一个常用机器学习算法库,算法被实现为对RDD的Spark操作。这个库包含可扩展的学习算法,比如分类、回归等需要对大量数据集进行迭代的操作。 -
GraphX
控制图、并行图操作和计算的一组算法和工具的集合。GraphX扩展了RDD API,包含控制图、创建子图、访问路径上所有顶点的操作
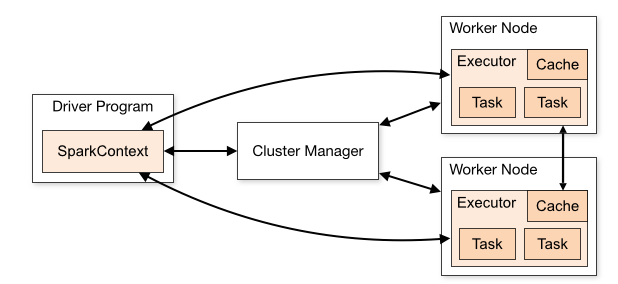
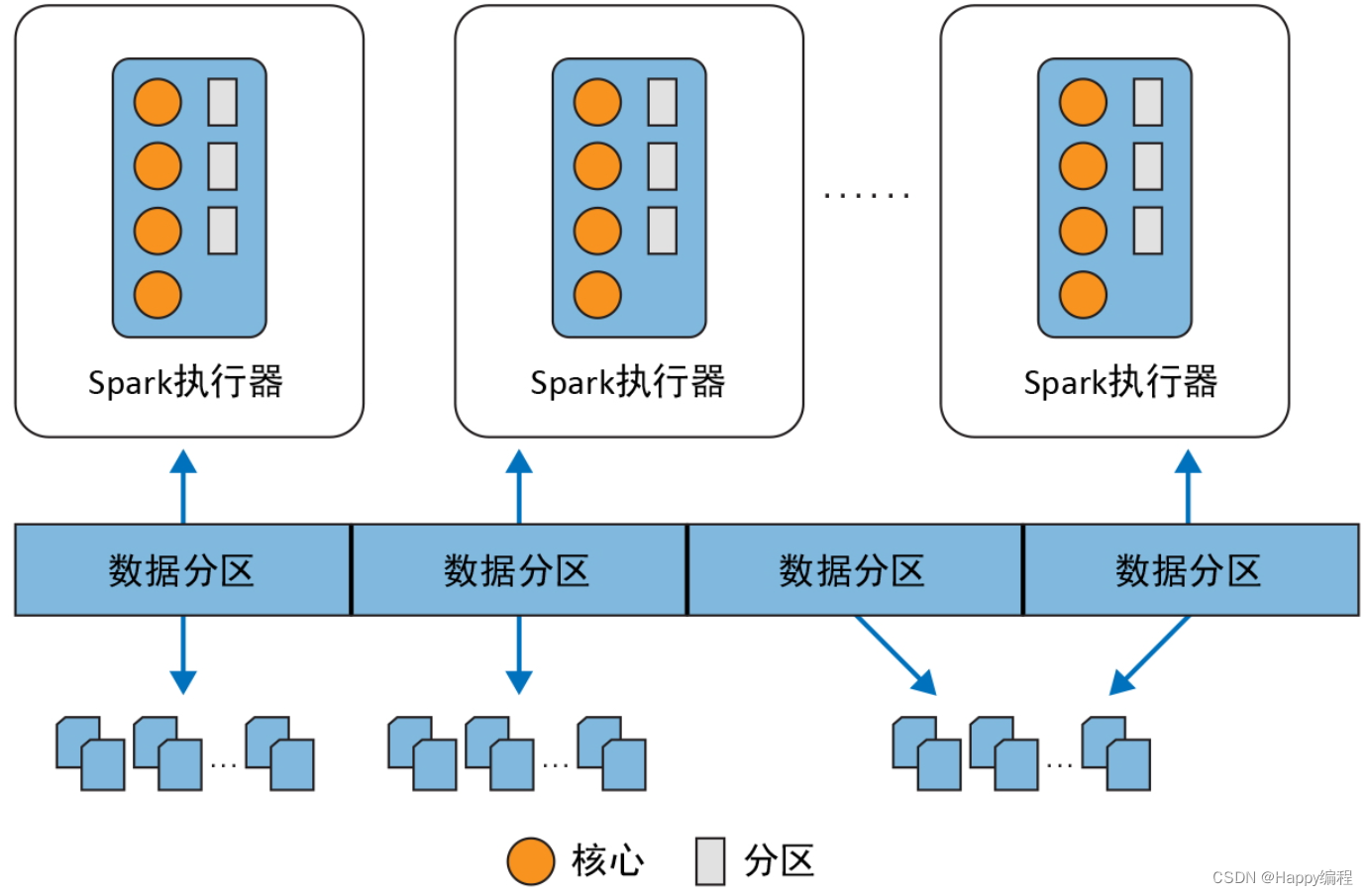
架构组成
-
Cluster Manager
在standalone模式中即为Master主节点,控制整个集群,监控worker。在YARN模式中为资源管理器 -
Worker节点
从节点,负责控制计算节点,启动Executor或者Driver。

部署和体系结构
Spark运行模式
- 本地模式(Local Mode)
该模式被称为Local[N]模式,是用单机的多个线程来模拟Spark分布式计算,直接运行在本地,便于调试,通常用来验证开发出来的应用程序逻辑上有没有问题。
例子:(在spark安装目录的examples\jars下运行)
spark-submit --class org.apache.spark.examples.SparkPi --master local spark-examples*.jar 10
- 独立集群运行模式(Standalone)
Standalone模式使用Spark自带的资源调度框架
采用Master/Slaves的典型架构,选用ZooKeeper来实现Master的HA
当使用spark-submit工具提交Job或者在Eclipse、IDEA等开发平台上使用: new SparkConf
.setManager (“spark://master:7077”) 方式运行Spark任务时,Driver是运行在本地Client端上的
框架结构如下:


- Spark on Yarn

页面