目录
- Systemd
- systemd架构
- systemd 系统管理
- 管理系统
- 查看启动耗时
- 查看当前主机的信息
- Unit 资源
- 查看当前系统的所有 Unit
- 查看系统状态和单个 Unit 的状态
- Unit 管理
- 依赖关系
- Unit 配置文件
- 查看配置文件的内容
- Target
- target(Systemd) 与 runlevel(SysVinit)对应关系
- 与传统/sbin/init进程的区别
- 日志管理
Systemd
在计算机启动时,BootLoader装载上真正的根文件系统后执行/sbin/init进程,而现下Systemd(系统管理守护进程)取替了传统的SysV init成为主流的 init 替代进程。最开始以GNU GPL协议授权开发,现在已转为使用GNU LGPL协议,它是如今讨论最热烈的引导和服务管理程序,Linux系统启动过程中init进程部分将交给systemd处理。
systemd架构

systemd 系统管理
systemd是一组命令,涉及到系统管理的方方面面。
管理系统
# 重启系统
$ sudo systemctl reboot# 关闭系统,切断电源
$ sudo systemctl poweroff# CPU停止工作
$ sudo systemctl halt# 暂停系统
$ sudo systemctl suspend# 让系统进入冬眠状态
$ sudo systemctl hibernate# 让系统进入交互式休眠状态
$ sudo systemctl hybrid-sleep# 启动进入救援状态(单用户状态)
$ sudo systemctl rescue
查看启动耗时
# 查看启动耗时
$ systemd-analyze # 查看每个服务的启动耗时
$ systemd-analyze blame# 图形化显示每个服务启动的时间轴,结果保存至init.png
systemd-analyze plot > init.png# 显示瀑布状的启动过程流
$ systemd-analyze critical-chain# 显示指定服务的启动流
$ systemd-analyze critical-chain atd.service
查看当前主机的信息
# 显示当前主机的信息
$ hostnamectl# 设置主机名。
$ sudo hostnamectl set-hostname <name>
其他命令如 timectl、loginctl、localctl 可自行查阅。
Unit 资源
Systemd 可以管理所有系统资源。不同的资源统称为 Unit(单位)。Unit 一共分成12种:
Service unit:系统服务
Target unit:多个 Unit 构成的一个组
Device Unit:硬件设备
Mount Unit:文件系统的挂载点
Automount Unit:自动挂载点
Path Unit:文件或路径
Scope Unit:不是由 Systemd 启动的外部进程
Slice Unit:进程组
Snapshot Unit:Systemd 快照,可以切回某个快照
Socket Unit:进程间通信的 socket
Swap Unit:swap 文件
Timer Unit:定时器
查看当前系统的所有 Unit
# 列出正在运行的 Unit
$ systemctl list-units# 列出所有Unit,包括没有找到配置文件的或者启动失败的
$ systemctl list-units --all# 列出所有没有运行的 Unit
$ systemctl list-units --all --state=inactive# 列出所有加载失败的 Unit
$ systemctl list-units --failed# 列出所有正在运行的、类型为 service 的 Unit
$ systemctl list-units --type=service
查看系统状态和单个 Unit 的状态
# 显示系统状态
$ systemctl status# 显示单个 Unit 的状态
$ sysystemctl status bluetooth.service# 显示远程主机的某个 Unit 的状态
$ systemctl -H root@rhel7.example.com status httpd.service
Unit 管理
# 立即启动一个服务
$ sudo systemctl start apache.service# 立即停止一个服务
$ sudo systemctl stop apache.service# 重启一个服务
$ sudo systemctl restart apache.service# 杀死一个服务的所有子进程
$ sudo systemctl kill apache.service# 重新加载一个服务的配置文件
$ sudo systemctl reload apache.service# 重载所有修改过的配置文件
$ sudo systemctl daemon-reload# 显示某个 Unit 的所有底层参数
$ systemctl show httpd.service# 显示某个 Unit 的指定属性的值
$ systemctl show -p CPUShares httpd.service# 设置某个 Unit 的指定属性
$ sudo systemctl set-property httpd.service CPUShares=500
依赖关系
Unit 之间存在依赖关系:A 依赖于 B,就意味着 Systemd 在启动 A 的时候,同时会去启动 B。
# 列出一个 Unit 的所有依赖
$ systemctl list-dependencies --all nginx.service
Unit 配置文件
每一个 Unit 都有一个配置文件,告诉 Systemd 怎么启动这个 Unit 。Systemd 默认从目录 /etc/systemd/system/ 读取配置文件。但是,里面存放的大部分文件都是符号链接,指向目录 /usr/lib/systemd/system/,真正的配置文件存放在那个目录。
systemctl enable 命令用于在上面两个目录之间,建立符号链接关系。如果配置文件里面设置了开机启动,systemctl enable 命令相当于激活开机启动。与之对应的,systemctl disable 命令用于在两个目录之间,撤销符号链接关系,相当于撤销开机启动。
配置文件的后缀名,就是该 Unit 的种类,比如 sshd.socket 。如果省略,Systemd 默认后缀名为 .service,所以 sshd 会被理解成 sshd.service 。
查看配置文件的内容
可以看到,配置文件分成几个区块。每个区块的第一行,是用方括号表示的区别名,比如[Unit]。注意,配置文件的区块名和字段名,都是大小写敏感的。每个区块内部是一些等号连接的键值对。
[Unit]区块通常是配置文件的第一个区块,用来定义 Unit 的元数据,以及配置与其他 Unit 的关系。
[Install]通常是配置文件的最后一个区块,用来定义如何启动,以及是否开机启动。
[Service]区块用来 Service 的配置,只有 Service 类型的 Unit 才有这个区块。
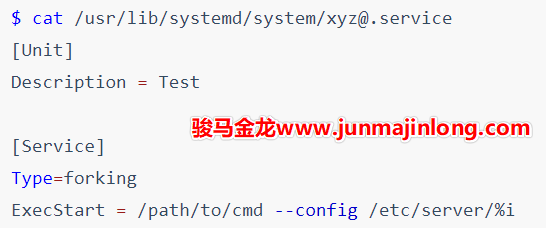
$ systemctl cat atd.service[Unit]
Description=ATD daemon[Service]
Type=forking
ExecStart=/usr/bin/atd[Install]
WantedBy=multi-user.target
Target
启动计算机的时候,需要启动大量的 Unit。如果每一次启动,都要一一写明本次启动需要哪些 Unit,显然非常不方便。Systemd 的解决方案就是 Target。可以说,Target 就是一个 Unit 组,包含许多相关的 Unit 。启动某个 Target 的时候,Systemd 就会启动里面所有的 Unit。传统的 init 启动模式里面,有 RunLevel 的概念,跟 Target 的作用很类似。不同的是,RunLevel 是互斥的,不可能多个 RunLevel 同时启动,但是多个 Target 可以同时启动。
# 查看当前系统的所有 Target
$ systemctl list-unit-files --type=target# 查看一个 Target 包含的所有 Unit
$ systemctl list-dependencies multi-user.target# 查看启动时的默认 Target
$ systemctl get-default# 设置启动时的默认 Target
$ sudo systemctl set-default multi-user.target# 切换 Target 时,默认不关闭前一个 Target 启动的进程,
# systemctl isolate 命令改变这种行为,
# 关闭前一个 Target 里面所有不属于后一个 Target 的进程
$ sudo systemctl isolate multi-user.target
target(Systemd) 与 runlevel(SysVinit)对应关系
| runlevel | target | 链接向 | 含义 |
|---|---|---|---|
| 0 | runlevel0.target | poweroff.target | 关闭系统 |
| 1 | runlevel1.target | rescue.target | 单用户模式 |
| 2 | runlevel2.target | multi-user.target | 非图形化,用户可以通过多个控制台或网络登录 |
| 3 | runlevel3.target | multi-user.target | 用户定义/域特定运行级别,默认等同于 2 |
| 4 | runlevel4.target | multi-user.target | 用户定义/域特定运行级别,默认等同于 2 |
| 5 | runlevel5.target | graphical.target | 多用户,图形化。通常为所有运行级别 3 的服务外加图形化登录 |
| 6 | runlevel6.target | reboot.target | 重启 |
与传统/sbin/init进程的区别
(1)默认的 RunLevel(在/etc/inittab文件设置)现在被默认的 Target 取代,位置是/etc/systemd/system/default.target,通常符号链接到graphical.target(图形界面)或者multi-user.target(多用户命令行)。(2)启动脚本的位置,以前是/etc/init.d目录,符号链接到不同的 RunLevel 目录 (比如/etc/rc3.d、/etc/rc5.d等),现在则存放在/lib/systemd/system和/etc/systemd/system目录。(3)配置文件的位置,以前init进程的配置文件是/etc/inittab,各种服务的配置文件存放在/etc/sysconfig目录。现在的配置文件主要存放在/lib/systemd目录,在/etc/systemd目录里面的修改可以覆盖原始设置。
日志管理
Systemd 统一管理所有 Unit 的启动日志。带来的好处就是,可以只用 journalctl 一个命令,查看所有日志(内核日志和应用日志)。日志的配置文件是 /etc/systemd/journald.conf 。
# 查看所有日志(默认情况下 ,只保存本次启动的日志)
$ sudo journalctl# 查看内核日志(不显示应用日志)
$ sudo journalctl -k# 查看系统本次启动的日志
$ sudo journalctl -b
$ sudo journalctl -b -0# 查看指定时间的日志
$ sudo journalctl --since="2012-10-30 18:17:16"
$ sudo journalctl --since "20 min ago"
$ sudo journalctl --since yesterday
$ sudo journalctl --since "2015-01-10" --until "2015-01-11 03:00"
$ sudo journalctl --since 09:00 --until "1 hour ago"# 查看指定服务的日志
$ sudo journalctl /usr/lib/systemd/systemd# 查看指定进程的日志
$ sudo journalctl _PID=1# 查看指定用户的日志
$ sudo journalctl _UID=33 --since today# 查看某个路径的脚本的日志
$ sudo journalctl /usr/bin/bash# 查看某个 Unit 的日志
$ sudo journalctl -u nginx.service
$ sudo journalctl -u nginx.service --since today# 以 JSON 格式(多行)输出,可读性更好
$ sudo journalctl -b -u nginx.serviceqq-o json-pretty
内容参考:Systemd 入门教程:命令篇 - 阮一峰的网络日志 (ruanyifeng.com)

![[2020.1.10]systemd介绍](https://img-blog.csdnimg.cn/20210412223013437.png)