dpkg与centos中的rpm相似,被用于安装,卸载及查询deb包信息。下面简单介绍基础命令。
已有安装包:test.deb。
安装命令:
dpkg -i test.deb 安装test.deb软件包
dpkg -c test.deb #查看test.deb软件包中包含的文件结构
安装后查询命令:
dpkg -I test查看已安装的test.deb软件包的详细信息,包括软件名称、版本等
dpkg -L test #查看已安装test.deb软件包安装的所有文件
dpkg -s test #查看test.deb软件包的详细信息
dpkg -S filepath#查看某个文件属于哪个deb包
dpkg-query -S filepath #查看某个文件属于哪个deb包
dpkg -X test.deb directory#提取deb包中的文件
dpkg -e test.deb directory #提取deb包的控制信息
更新软件包命令:
dpkg -update-avail test.deb
卸载命令:
dpkg -r test #卸载test.deb软件包 (保留配置信息)
dpkg -P test #卸载test.deb软件包 (包括配置信息)
注:dpkg命令无法自动解决依赖关系。
如何获得命令属于的包
有时候,一个包里面包含非常多的命令,比如coreutils,包含很多有用的命令工具,如果我们看到一个命令,比如ls,应该如果知道他属于哪个包呢?
/bin$ which ls -l
/bin/ls
/bin$ dpkg-query -S /bin/ls
coreutils: /bin/ls
如何获得包源码
最直接的做法,搜索引擎找这个包,可以找到
www.gnu.org/software/coreutils
再进到网站去下载对应的源码,但是其实apt命令已经帮我们实现了这个路径。
$ apt source coreutils
dpkg编译:
- deb源码包由以下文件组成:.debian.tar.xz 文件 .dsc文件和.tar.gz文件。
得到这三个文件之后,执行dpkg-source -x xxx.dsc,可生成源码目录 xz -d xx.debian.tar.xz生成xx.debian.tar,tar -xvf xx.debian.tar可生成补丁文件。
路径为:debian/patches/- 编译包:
dpkg-buildpackage -us -uc//dpkg-buildpackage -b -rfakeroot -us -uc - 安装包:
dpkg -i 包名.deb
使用apt-get 安装以下工具:dh-make ,devscripts。
使用apt-get install dh-make 将安装 debhelper dh-make html2text三个包。
使用apt-get install devscripts ,这个是使用debuild所需要的。
问题1:
dpkg-source: 错误: can’t build with source format ‘3.0 (quilt)’: no upstream tarball found at …/caja_1.24.0.orig.tar.{bz2,gz,lzma,xz}
rm ./debian/source/format
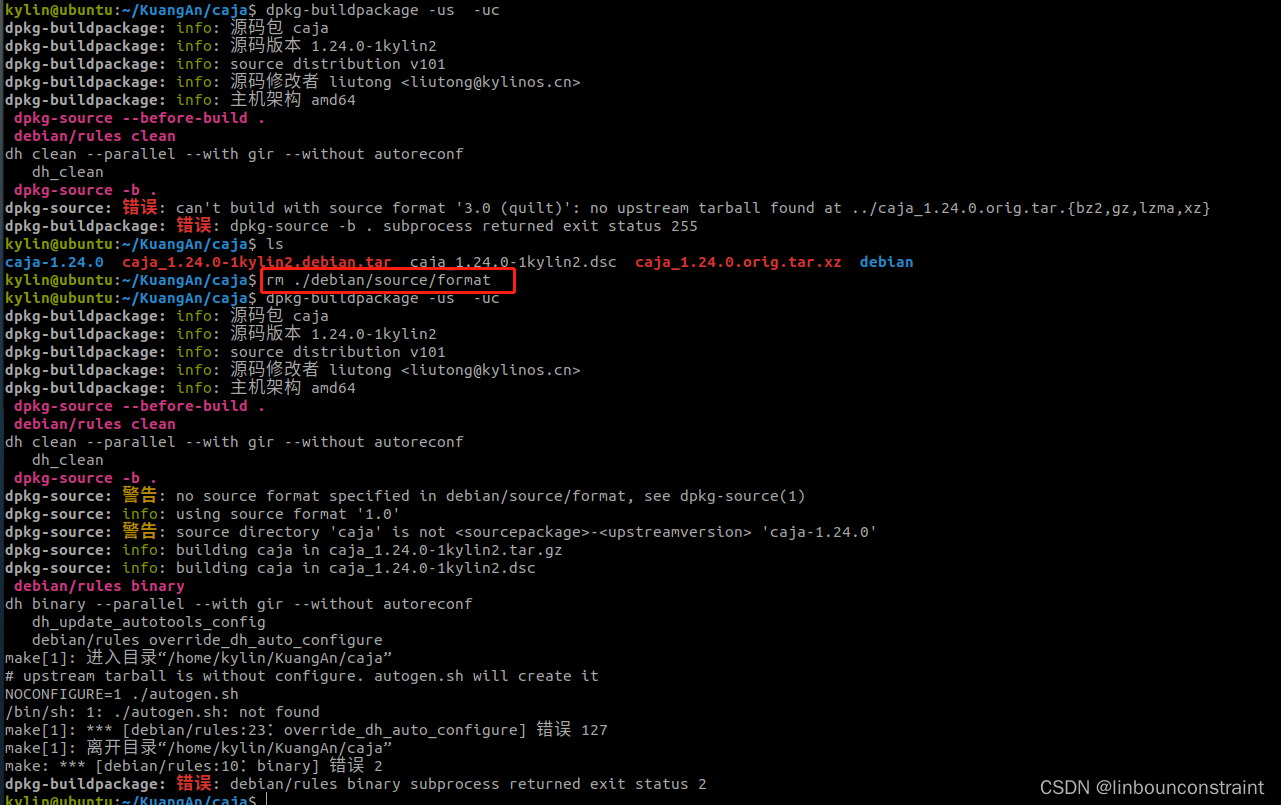
quilt改为native
vim debian/source/format
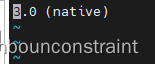
可以把format文件中的quilt改为native,否则在未添加quilt的patch文件之前修改代码文件构建源码包会报错(quilt表示上游包,native表示自建包):