相关文章



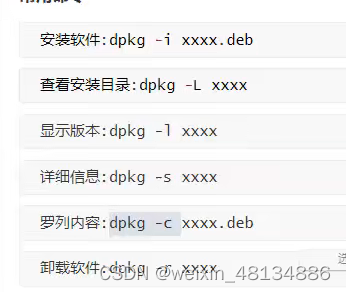
dpkg制作deb包详解
1 deb包文件结构 deb 软件包里面的结构,它具有DEBIAN和软件具体安装目录(如etc, usr, opt, tmp等)。在DEBIAN目录中至少必须包括control文件,还有可能postinst(postinstallation)、postrm(postremove)、preinst(preinstallation)、…


大数据生态和Spark简介
一、大数据时代
1.第三次信息化浪潮:根据IBM前首席执行官郭士纳的观点,IT领域每隔十五年就会迎来一次重大变革。 2.数据产生方式的变革促成大数据时代的来临: ①存储设备容量不断增加 ②CPU处理能力大幅提升 ③网络带宽不断增加 等等&#…
Spark大数据计算引擎介绍
本文内容参考《Spark与Hadoop大数据分析》[美]文卡特安卡姆 著;《大数据架构详解 从数据获取到深度学习》 朱洁 罗华霖 著。
大数据生态的两个主要部分是Hadoop软件框架和Spark内存级计算引擎。Hadoop包含四个项目:Hadoop common,HDFS&#…

大数据之spark_spark简介
什么是Spark
Spark是一种快速、通用、可扩展的大数据分析引擎,2009年诞生于加州大学伯克利分校AMPLab,2010年开源,2013年6月成为Apache孵化项目,2014年2月成为Apache的顶级项目,2014年5月发布spark1.0,201…
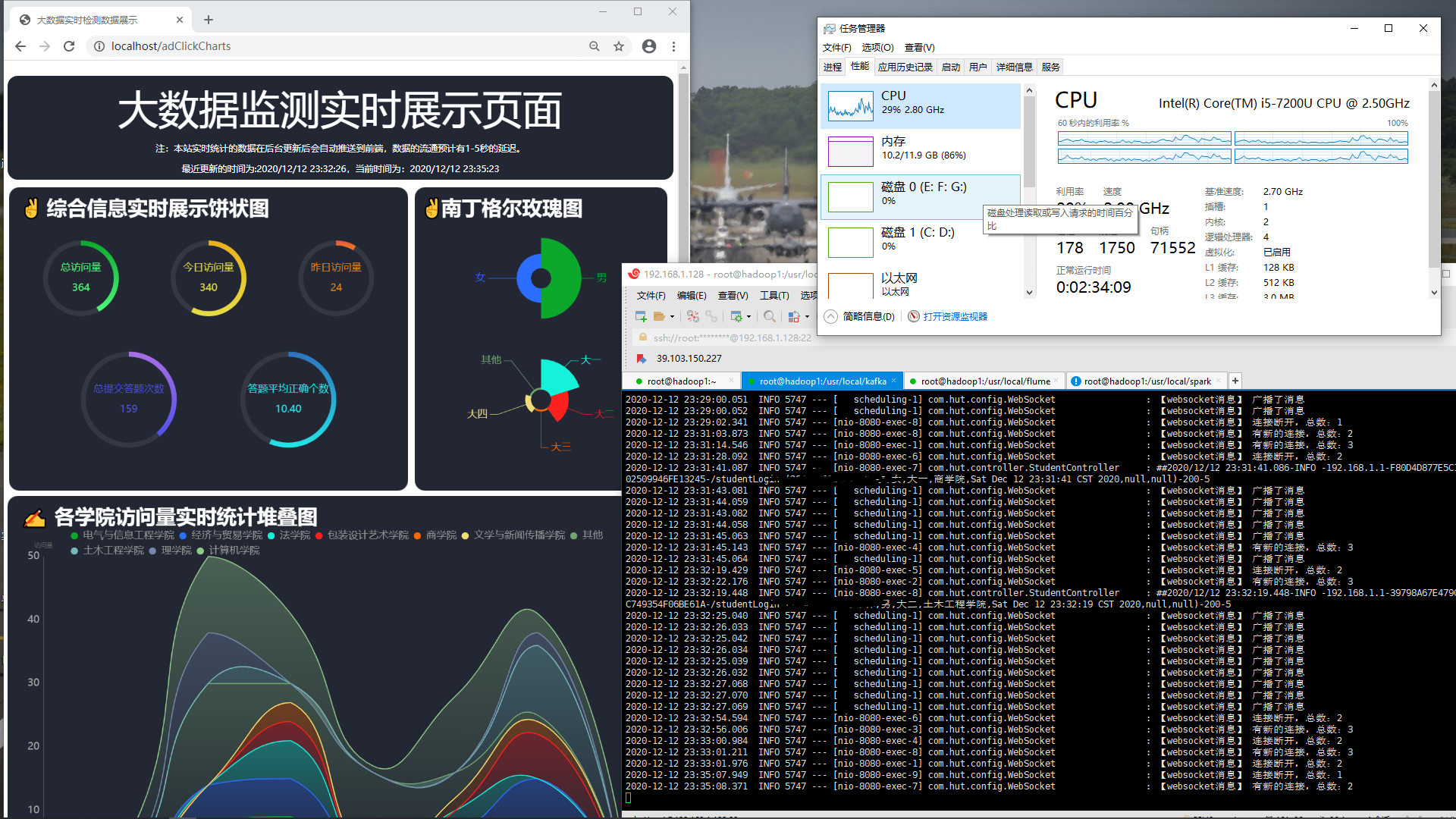
开源项目_springboot的答题系统+spark大数据实时分析
一、项目展示 在这里,主要展示大数据图表分析的几个页面。更多精彩由您自己发掘! 图1 饼状图 图2 堆叠图 图3 柱状图 二、项目介绍
本项目分为两个模块,第一个为java语言基于springboot实现的答题模块,另一个为scala语言基于spar…

Spark大数据开发技术简介
Spark大数据开发技术简介 轻量级的内存集群计算平台 文章目录 Spark大数据开发技术简介历史沿革Spark的优点对比Apache Spark堆栈中的不同组件基本原理架构组成部署和体系结构Spark运行模式 页面 历史沿革
Apache Spark是一个围绕速度、易用性和复杂分析构建的大数据处理框架最…

【大数据】【Spark】Spark概述
由于Spark程序的编写最好使用Scala语言,可参照博主以下Scala入门文章 链接:https://blog.csdn.net/treesorshining/article/details/124697102 文章目录 1.Spark概念2.Spark与Hadoop的关系1.从时间节点上来看2.从功能上来看 3.Spark与Hadoop的比较4.Spar…

Spark大数据系列教程持续更新
Spark大数据系列教程
想学习大数据的福利来了,由于近期工作繁忙,本人已将自己学习大数据的过程陆续开始更新:
Spark大数据系列:一、RDD详解Spark大数据系列 二、Spark入门程序WordCount详解(Scala版本)Spark大数据系列ÿ…
大数据面试题——spark
文章目录 讲一下spark 的运行架构一个spark程序的执行流程讲一下宽依赖和窄依赖spark的stage是如何划分的Spark的 RDD容错机制。checkpoint 检查点机制?RDD、DAG、 Stage、 Task 、 Job Spark的shuffle介绍Spark为什么快,Spark SQL 一定比 Hive 快吗Spar…

引爆Spark大数据引擎的七大工具
原文名称:7 tools to fire up Sparks big data engine Spark正在数据处理领域卷起一场风暴。让我们通过本篇文章,看看为Spark的大数据平台起到推波助澜的几个重要工具。 Spark生态系统众生相 Apache Spark不仅仅让大数据处理起来更快,还让大…
大数据面试题Spark篇(1)
目录
1.spark数据倾斜
2.Spark为什么比mapreduce快?
3.hadoop和spark使用场景?
4.spark宕机怎么迅速恢复?
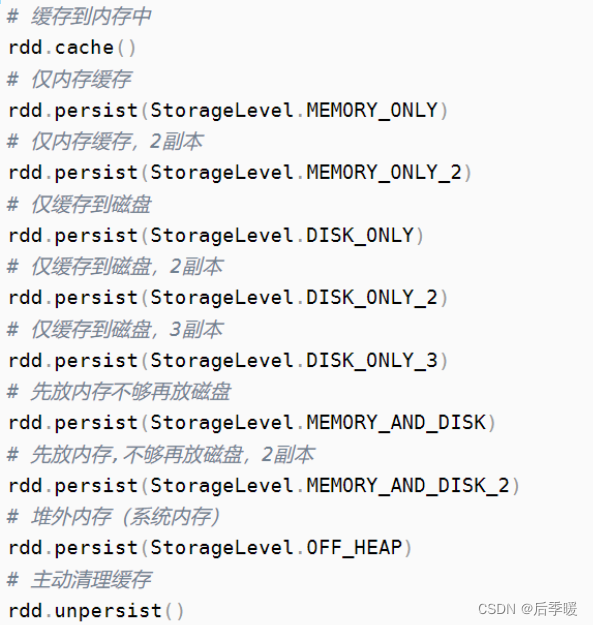
5. RDD持久化原理?
6.checkpoint检查点机制
7.checkpoint和持久化的区别
8.说一下RDD的血缘
9.宽依赖函数&#…
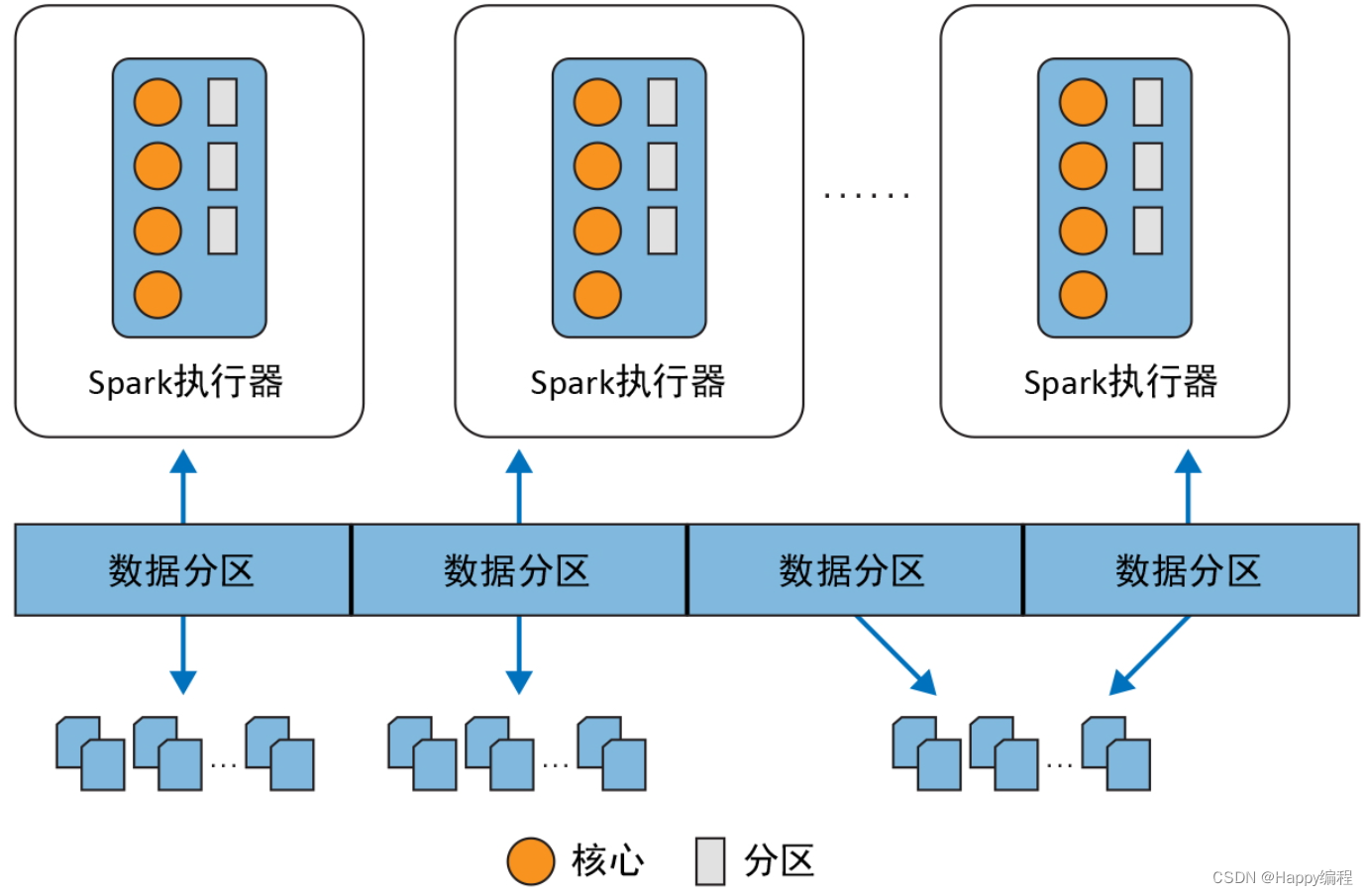
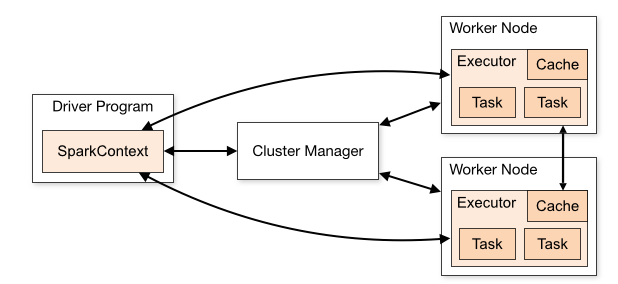
大数据_Spark常见组件
Spark 是一个分布式数据处理引擎,其各种组件在一个集群上协同工作,下面是各个组件之间的关系图。 Spark驱动器
作为 Spark 应用中负责初始化 SparkSession 的部分,Spark 驱动器扮演着多个角色:它与集群管理器打交道;它…
大数据Spark框架
Spark 是一种基于内存快速、通用、可扩展的大数据分析计算引擎。
Spark 优势:
Spark核心单元RDD适合并行计算和重复使用;RDD模型丰富,使用灵活;多个任务之间基于内存相互通信(除了shuffle会把数据写入磁盘࿰…
Windows下的Spark环境配置(含IDEA创建工程--《Spark大数据技术与应用》第九章-菜品推荐项目)
文章目录 前言一、下载资源二、本地配置步骤1.解压2.引入本地环境3.启动HADOOP文件4.进行Spark测试 三、IDEA引入Spark项目1.idea按照scala插件2.新建scala项目3.配置项目4.新建scala类 前言
本文适用于《Spark大数据技术与应用》第九章-菜品推荐项目环境配置:
跟…

Spark开发:Spark大数据开发编程示例
大数据开发人员,根据企业大数据处理的需求,进行大数据平台系统的搭建,比如说Hadoop,比如说Spark,而不同的大数据处理框架,采取不同的编程语言和编程模型,这就需要技术开发人员要掌握相关的技术。…

《Spark大数据技术与应用》肖芳 张良均著——课后习题
目录 教材知识汇总课后习题第一章 Spark概述Spark的特点Spark生态圈Spark应用场景 第二章 Scala基础匿名函数SetMapmapflatMapgroupBy课后习题 第三章 Spark编程教材52页任务3.2及之后的任务 重点复习sortBy排序collect查询distinct去重zip实训题实训1实训2选择题编程题 第四章…