本文内容参考《Spark与Hadoop大数据分析》[美]文卡特·安卡姆 著;《大数据架构详解 从数据获取到深度学习》 朱洁 罗华霖 著。
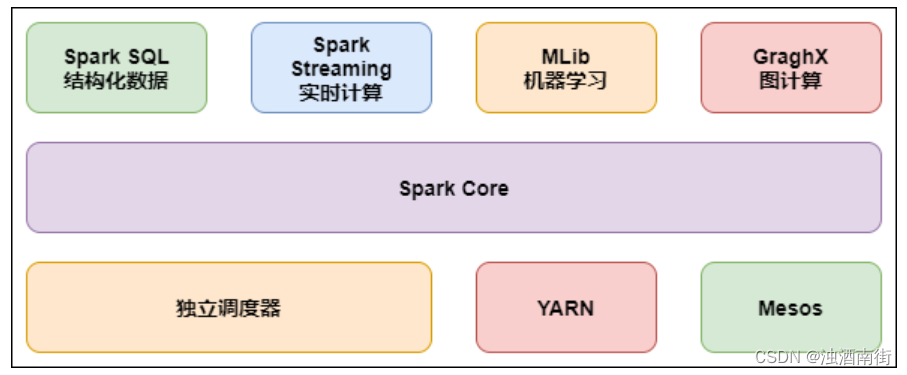
大数据生态的两个主要部分是Hadoop软件框架和Spark内存级计算引擎。Hadoop包含四个项目:Hadoop common,HDFS,YARN和MapReduce。
HDFS用于存储数据,HDFS文件被划分成区块分布在集群上;
YARN用于管理集群资源(CPU和内存)和支持Hadoop的公共实用程序;
MapReduce是利用磁盘的高I/O操作实现并行计算的框架,但它在迭代计算中性能不足。
Spark的作用相当于MapReduce,它是基于内存的计算引擎。Spark将迭代过程的中间数据缓存到内存中,根据需要多次重复使用。此外,Spark利用RDD结构提升了容错性能。
磁盘由于其物理特性现在,速度提升非常困难,远远跟不上CPU和内存的发展速度。近几十年来,内存的发展一直遵循摩尔定律,价格在下降,内存在增加。现在主流的服务器,几百GB或几TB的内存都很常见,内存的发展使得内存数据库得以实现,Spark正是利用这种计算资源设计的基于内存的分布式处理软件,其目标是取代MapReduce。
Spark可以直接对HDFS进行数据读写,支持YARN等部署模式。
Spark适合用于多次操作特定数据量大的数据集的场合;数据量小且计算密集度大的场合,其性能提升相对较小。
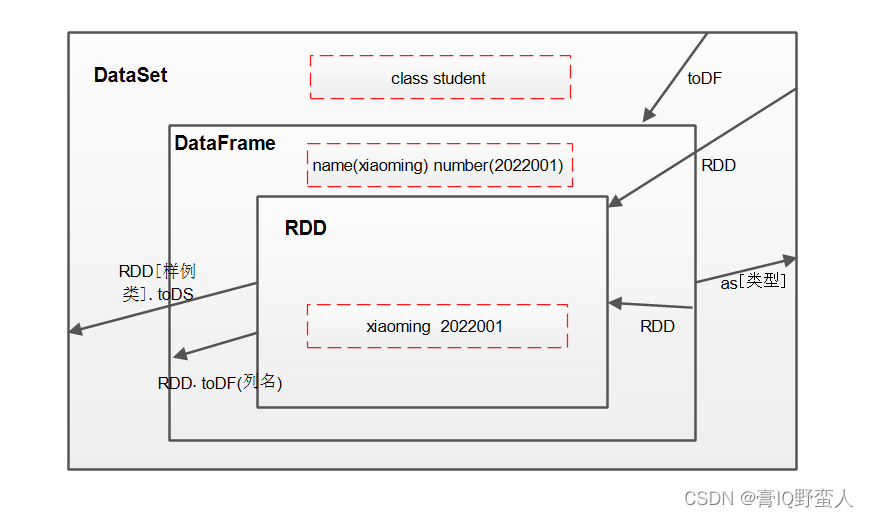
RDD
在Spark里,所有的处理和计算任务都会被组织成一系列Resilient Distributed Dataset(弹性分布式数据集,简称RDD)上的transformations(转换) 和 actions(动作)。
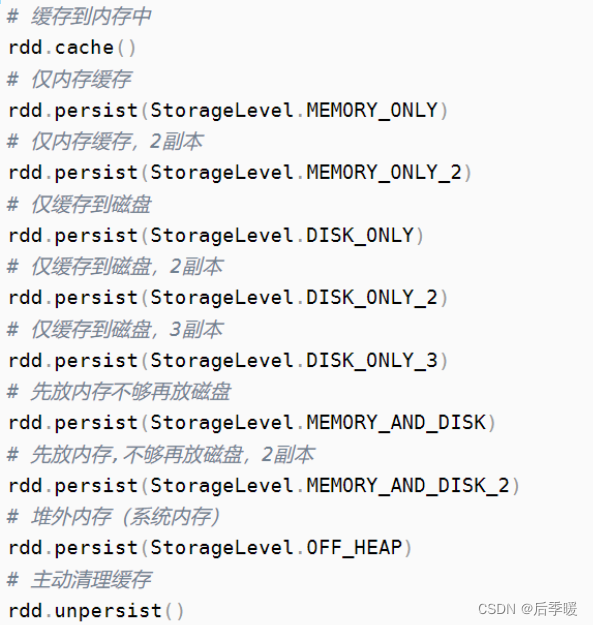
RDD是一个包含诸多元素、被划分到不同节点上进行并行处理的数据集合,可以将RDD持久化到内存中,这样就可以有效地在并行操作中复用(在机器学习这种需要反复迭代的任务中非常有效)。
在节点发生错误时RDD也可以根据其Lineage自动计算恢复。
RDD是Spark的最基本抽象,是对分布式内存的抽象使用,以操作本地集合的方式来操作分布式数据集的抽象实现。
RDD是Spark最核心的内容,它表示已被分区、不可变的、能够被并行操作的数据集,不同的数据集格式对应不同的RDD实现。
RDD必须是可序列化的。
RDD只能从持久存储或通过Transformation操作产生。(创建方式)
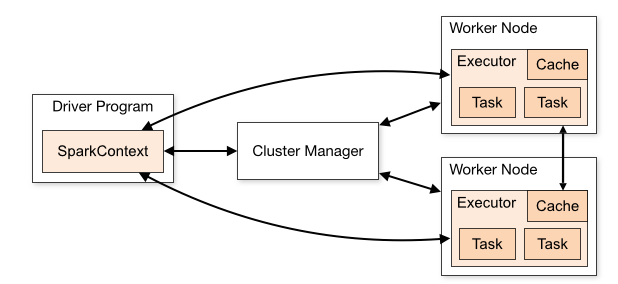
Spark工作架构
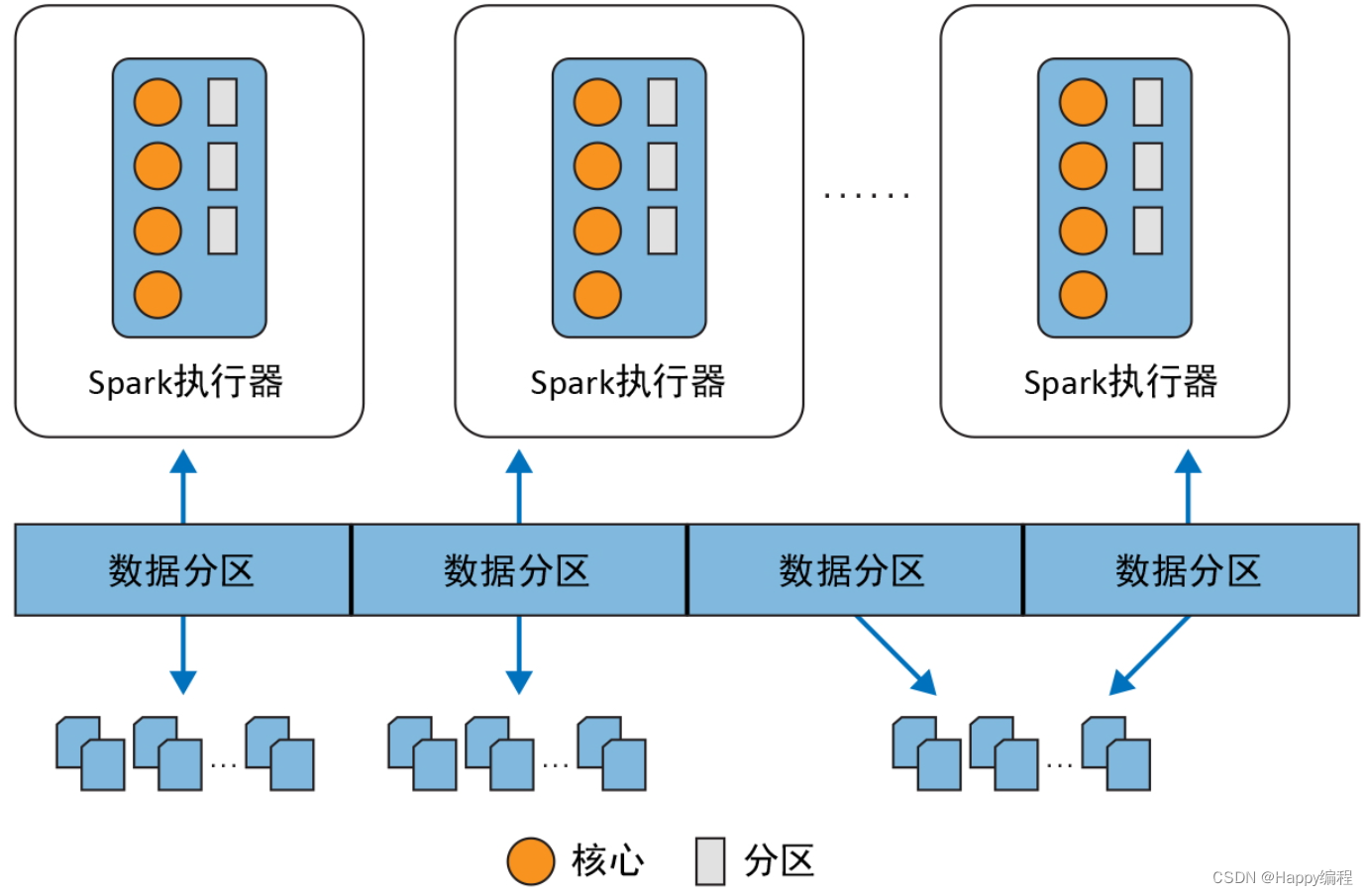
Spark可以分为1个driver(笔记本电脑或者集群网关机器上,用户编写的Spark程序)和若干个executor(在RDD分布的各个节点上)。
通过SparkContext(简称sc)连接Spark集群、创建RDD、累加器(accumlator)、广播变量(broadcast variables),简单可以认为SparkContext是Spark程序的根本。
Driver会把计算任务分成一系列小的task,然后送到executor执行。executor之间可以通信,在每个executor完成自己的task以后,所有的信息会被传回。
Spark框架是使用Scala函数式编程语言开发的,支持Java编程,Java与Scala可以互操作。此外,Spark提供了Python编程接口,Spark使用Py4J实现Python与Java的互操作,从而可以使用Python编写Spark程序。Spark还提供了一个Python_Shell,即pyspark,从而可以以交互的方式使用Python编写Spark程序。
最后,有关Pyspark的环境配置参考http://blog.csdn.net/cymy001/article/details/78430892