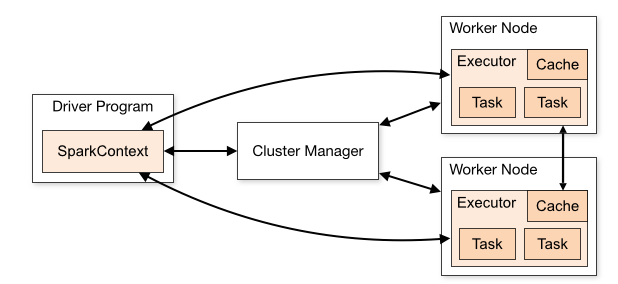
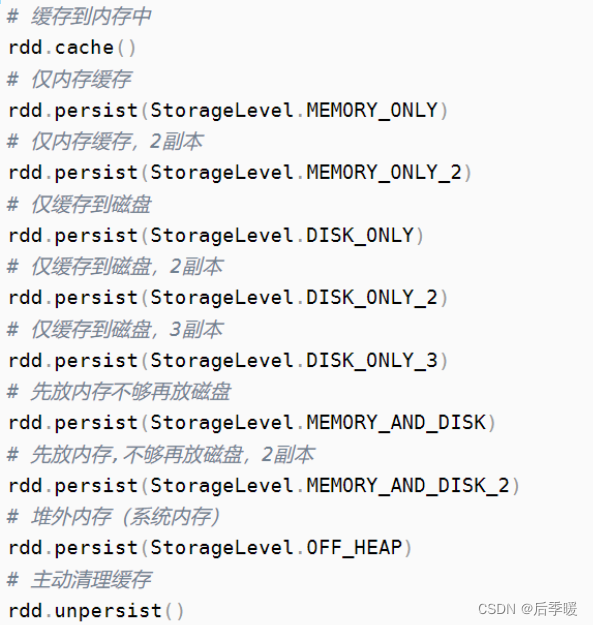
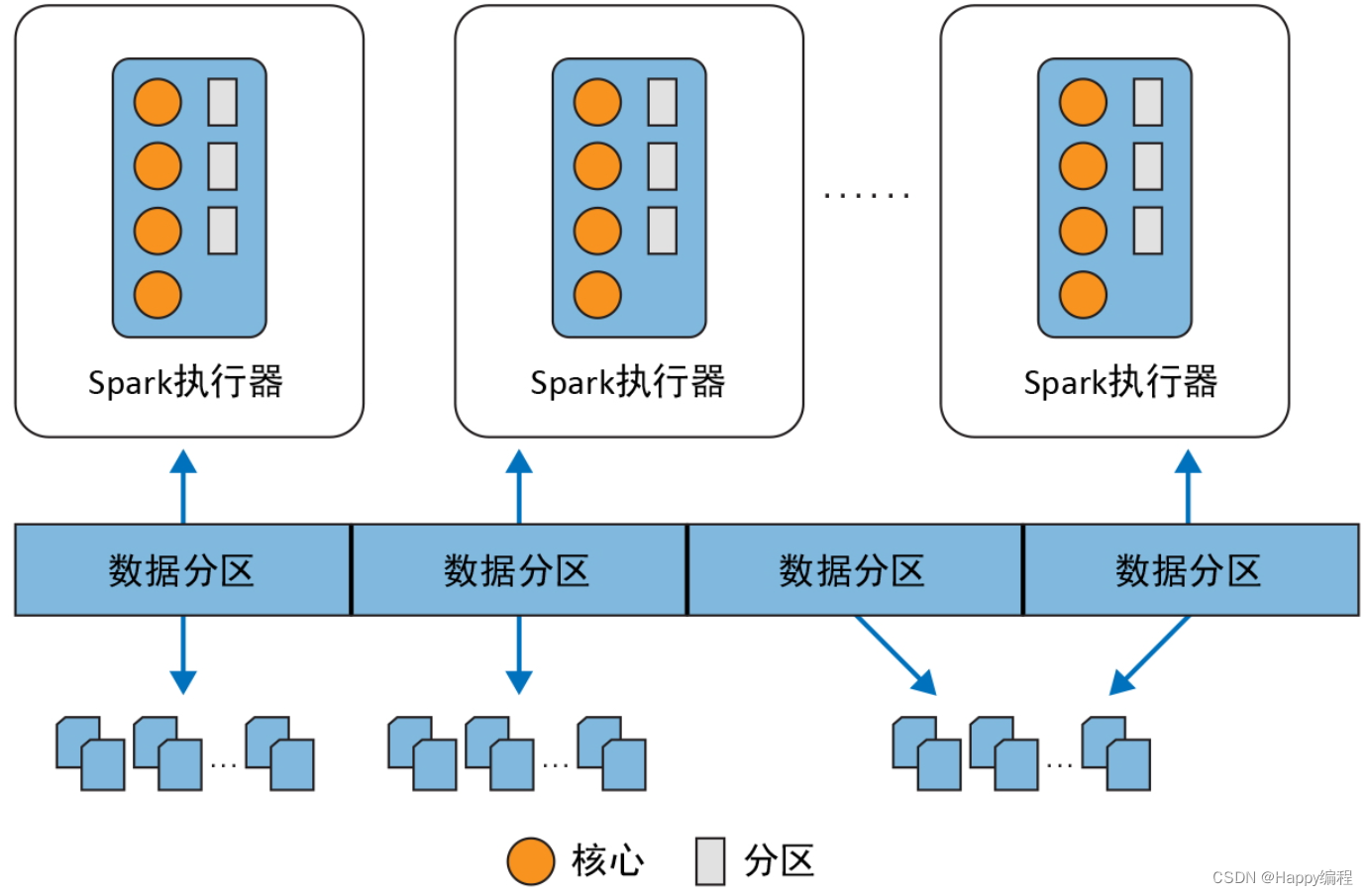
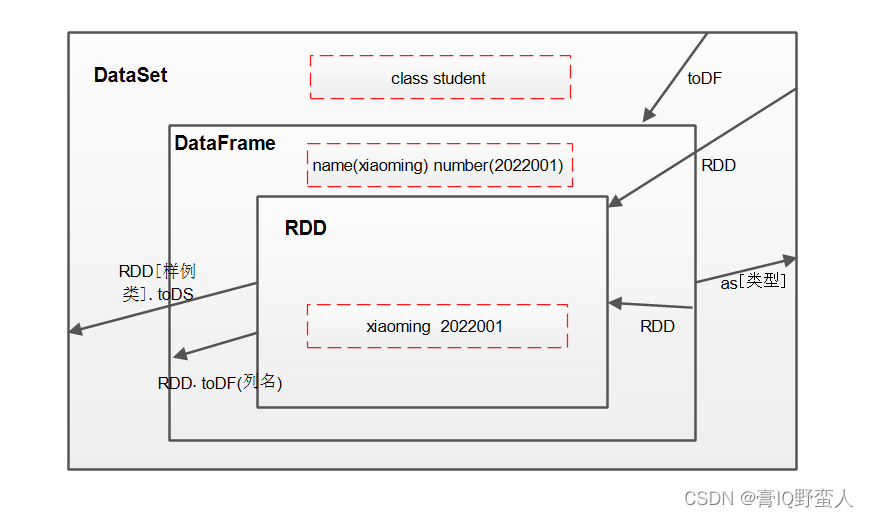
Spark大数据系列教程
想学习大数据的福利来了,由于近期工作繁忙,本人已将自己学习大数据的过程陆续开始更新:
- Spark大数据系列:一、RDD详解
- Spark大数据系列 二、Spark入门程序WordCount详解(Scala版本)
- Spark大数据系列:三、Java版本WordCount详解(Java版本)
- Spark大数据系列 四、Java Lambda表达式实现WordCount详解
- Spark大数据系列:五、安装配置JDK1.8
- Spark大数据系列:六、安装配置Zookeeper集群
- Spark大数据系列:七、Spark基于standalone集群搭建
- Spark大数据系列:八、Tranformation算子详解<一>
- Spark大数据系列:九、图解算子aggregateByKey
- Spark大数据系列:十、常用Action类算子详解
- Spark大数据系列:十一、RDD的缓存机制详解
- Spark大数据系列:十二、Spark基于Standalone提交任务的两种方式
- Spark大数据系列:十三、Hadoop全分布式HA集群的搭建
- Spark大数据系列:十四、HDFS常见操作命令
- Spark大数据系列:十五、Spark基于yarn提交任务的两种方式
- Spark大数据系列:十六、Spark中的专业术语
- Spark大数据系列:十七、Spark管道pipeline计算模式
持续更新中 …
该系列文章更新在头条的公众号中, 大家可搜索“数据致美”用户,或者扫描下面二维码,欢迎大家过来指点: