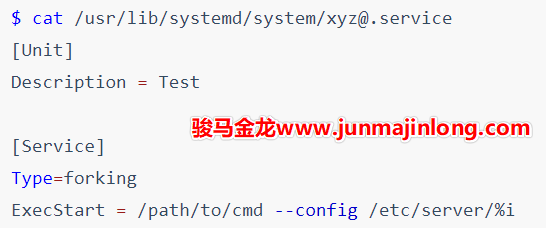
1 systemd基本概念

systemd:a system daemon,相当于以前的init进程,pid=1,systemd是1号进程!!!
sbin/init --> /lib/systemd/systemd
unit:
一个进程,例如lightdm.service
job:
一个动作,启动是个job,关闭是个job。开机启动时,systemd会默认加载default.target(graphical.target)
配置单元unit详细介绍:
socket:
此类配置单元封装系统和互联网中的一个套接字 。每一个套接字配置单元都有一个相应的服务配置单元 。相应的服务在第一个"连接"进入套接字时就会启动(例如:nscd.socket 在有新连接后便启动 nscd.service)。
device:
此类配置单元封装一个存在于Linux设备树中的设备。每一个使用udev规则标记的设备都将会在systemd中作为一个设备配置单元出现。
mount:
此类配置单元封装文件系统结构层次中的一个挂载点。Systemd将对这个挂载点进行监控和管理。比如可以在启动时自动将其挂载;可以在某些条件下自动卸载。Systemd 会将/etc/fstab 中的条目都转换为挂载点,并在开机时处理。
swap:
和挂载配置单元类似,交换配置单元用来管理交换分区。用户可以用交换配置单元来定义系统中的交换分区,可以让这些交换分区在启动时被激活。
target:
此类配置单元为其他配置单元进行逻辑分组。它们本身实际上并不做什么,只是引用其他配置单元而已。这样便可以对配置单元做一个统一的控制。这样就可以实现大家都已经非常熟悉的运行级别概念。(例如:multi-user.target 相当于在传统使用 SysV 的系统中运行级别 5)
timer:
定时器配置单元用来定时触发用户定义的操作
snapshot:
与 target 配置单元相似,快照是一组配置单元。它保存了系统当前的运行状态。
2 systemd特性
(1)服务并行启动
1 解决socket依赖
systemd可在Service还没启动好的时候建议一个socket,用来接收所有Client的请求和数据,并缓存.一旦Service启动完成,再替换缓存和socket.
2 解决D-Bus依赖
如果服务A需要使用服务B的D-Bus服务,而服务B并没有启动.D-Bus可以在服务A请求服务B的D-Bus服务时自动启动服务B,然后服务A再启动.
3 解决文件系统依赖
systemd集成了autofs的实现,对于系统中的挂载点如/home,当系统启动时,systemd创建临时的自动挂载点.
(2)采用Cgroup跟踪
跟踪和管理进程的生命周期和资源控制
(3)按需启动
(4)服务依赖管理
(5)支持状态快照
(6)日志
systemd journal
3 systemd指令
(1)服务Service相关

(2)运行等级Runlevel相关

(3)其他
关机:systemctl halt、systemctl poweroff
重启:systemctl reboot
挂起:systemctl suspend
休眠:systemctl hibernate