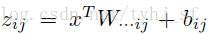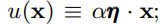一、引入激活函数的目的

图1:带一层隐藏层的神经网络
先看一个只含一层隐藏层的神经网络,如图1所示。输入为 n 条样本X,隐藏层H的权重和偏置分别为W_h,b_o,输出层O的权重和偏置分别为W_o,b_o。输出层的计算为:
H=XW_h+b_h (1)
O=HW_o+b_o (2)
将(1),(2)联合起来可得:
O=(XW_h+b_h)W_o+b_o=XW_hW_o+b_hW_o+b_o
从(3)可以看出,虽然加入了隐藏层,但是还是等效于单层的神经网络:权重为 W_hW_o ,偏置为 b_hW_o+b_o
上述的根本原因在于全连接只是对数据做仿射变换*,而多个仿射变换的叠加仍然是一个放射变换。因此有必要引入非线性变换,这个非线性变换就是今天要讲的激活函数。
*仿射变换,又称仿射映射,是指在几何中,一个向量空间进行一次线性变换并接上一个平移,变换为另一个向量空间。简单来说,“仿射变换”就是:“线性变换”+“平移”
二、激活函数之性质
-
**非线性:**即导数不是常数。保证多层网络不退化成单层线性网络。这也是激活函数的意义所在。
-
**可微性:**保证了在优化中梯度的可计算性。虽然 ReLU 存在有限个点处不可微,但处处 subgradient,可以替代梯度。
-
**计算简单:**激活函数复杂就会降低计算速度,因此 RELU 要比 Exp 等操作的激活函数更受欢迎。
-
非饱和性(saturation):饱和指的是在某些区间梯度接近于零(即梯度消失),使得参数无法继续更新的问题。最经典的例子是 Sigmoid,它的导数在 x 为比较大的正值和比较小的负值时都会接近于 0。RELU 对于 x<0,其梯度恒为 0,这时候它也会出现饱和的现象。Leaky ReLU 和 PReLU 的提出正是为了解决这一问题。
-
单调性(monotonic):即导数符号不变。当激活函数是单调的时候,单层网络能够保证是凸函数。但是激活函数如 mish 等并不满足单调的条件,因此单调性并不是硬性条件,因为神经网络本来就是非凸的。
-
参数少:大部分激活函数都是没有参数的。像 PReLU 带单个参数会略微增加网络的大小。还有一个例外是 Maxout,尽管本身没有参数,但在同样输出通道数下 k 路 Maxout 需要的输入通道数是其它函数的 k 倍,这意味着神经元数目也需要变为 k 倍。
三、sigmoid激活函数带来的梯度消失和爆炸问题
为了解决前面的问题,后来提出了sigmoid激活函数。sigmoid函数可以将元素的值变换到0和1之间,定义如下:

图2:sigmoid激活函数
def Sigmoid(x):return 1. / (1 + np.exp(-x))
#或
tf.nn.sigmoid(x,name=None)
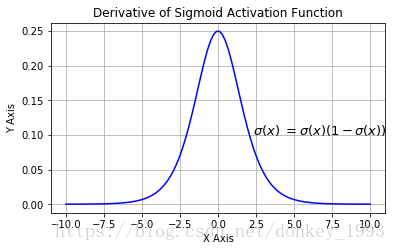
sigmoid激活函数的导数为:
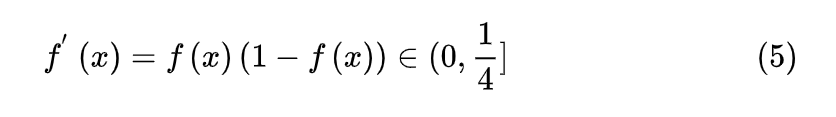
优点:
- 梯度平滑,求导容易
- Sigmoid函数的输出映射在(0,1)之间,单调连续,输出范围有限,优化稳定,可以用作输出层
缺点:
- 激活函数计算量大(在正向传播和反向传播中都包含幂运算和除法);
- 梯度消失:输入值较大或较小(图像两侧)时,sigmoid导数则接近于零,因此在反向传播时,这个局部梯度会与整个代价函数关于该单元输出的梯度相乘,结果也会接近为 0 ,无法实现更新参数的目的;
- Sigmoid 的输出不是 0 为中心(zero-centered)。因为如果输入都是正数的话


sigmoid激活函数虽然增强了模型的非线性表达能力,但是却带来了梯度消失和爆炸的问题,下面具体分析下是如何导致的。
3.1sigmoid可能带来的梯度消失


从公式(10)可以看出,随着反向传播链式求导,层数越多最后的梯度越小,最终导致梯度消失。
3.2 sigmoid可能带来的梯度爆炸



图4显示了公式(13)中的 x 数值范围随 w 的变化,可以看到 x 的最大数值范围也仅仅为0.45,因此仅仅在很窄的范围内才可能出现梯度爆炸。
根据3.1和3.2节,可以得出以下结论:
- sigmoid激活函数在深层神经网络中极大概率会引起梯度消失
- sigmoid激活函数很小的概率会出现梯度爆炸
由于sigmoid的局限性,所以后来很多人又提出了一些改进的激活函数,比如:ReLU,Leaky-ReLU,PReLU,Dice,RReLU等。后面具体介绍下几个激活函数的区别。
四、常用激活函数对比
(一)饱和
4.1sigmoid激活函数
4.2Tanh激活函数

tf.nn.tanh(x,name=None)
优点:
比Sigmoid函数收敛速度更快
tanh(x) 的梯度消失问题比 sigmoid 要轻
相比Sigmoid函数,输出是以 0 为中心 zero-centered
缺点:
还是没有改变Sigmoid函数的最大问题——由于饱和性产生的梯度消失。
(二)饱和

def tanh(x):return np.sinh(x)/np.cosh(x)
优点:
- 比Sigmoid函数收敛速度更快
- tanh(x) 的梯度消失问题比 sigmoid 要轻
- 相比Sigmoid函数,输出是以 0 为中心zero-centered
缺点:
- 还是没有改变Sigmoid函数的最大问题——由于饱和性产生的梯度消失。
4.3 ReLU(整流线性单元)
ReLU是Krizhevsky、Hinton等人在2012年《ImageNet Classification with Deep Convolutional Neural Networks》论文中提出的一种激活函数,可以用来解决梯度消失的问题,其定义如下:

从公式(14)可以看出ReLU在正区间的导数为1,因此不会发生梯度消失。关于ReLU的缺点,可以参见下面的描述:
神经网络在训练的时候,一旦学习率没有设置好,第一次更新权重的时候,输入是负值,那么这个含有ReLU的神经节点就会死亡,再也不会被激活。因为:ReLU的导数在
x>0 的时候是1,在 x<= 0 的时候是0。如果 x<= 0
,那么ReLU的输出是0,那么反向传播中梯度也是0,权重就不会被更新,导致神经元不再学习。
在实际训练中,如果学习率设置的太高,可能会发现网络中40%的神经元都会死掉,且在整个训练集中这些神经元都不会被激活。所以,设置一个合适的较小的学习率,会降低这种情况的发生。为了解决神经元节点死亡的情况,有人提出了Leaky-ReLU,PReLu,RReLU,ELU等激活函数。
总结一下ReLU的优缺点。
优点:
- ReLU解决了梯度消失的问题,因为导数为 1,不会像 sigmoid 那样由于导数较小,而导致连乘得到的梯度逐渐消失。更加有效率的梯度下降以及反向传播
- 由于ReLU线性特点,神经网络的计算和训练比sigmoid快很多,计算与收敛速度非常快:不涉及指数等运算
- 会使一部分神经元输出为0,造成网络的稀疏性,减少参数间的依存关系,缓解过拟合
缺点:
- ReLU可能会导致神经元死亡,权重无法更新。【某些神经元可能永远不会被激活,导致相应的参数永远不能被更新。有两个主要原因可能导致这种情况产生: (1) 非常不幸的参数初始化,这种情况比较少见 (2) learning rate太高导致在训练过程中参数更新太大,不幸使网络进入这种状态。解决方法是可以采用Xavier初始化方法,以及避免将learning rate设置太大或使用adagrad等自动调节learning rate的算法。】
- 当输入是负数的时候,ReLU 是完全不被激活的,这就表明一旦输入到了负数,ReLU 就会死掉。这样在前向传播过程中,还不算什么问题,有的区域是敏感的,有的是不敏感的。但是到了反向传播过程中,输入负数,梯度就会完全到0,这个和 sigmod 函数、tanh 函数有一样的问题。
- 我们发现 ReLU 函数的输出要么是0,要么是正数,这也就是说,ReLU 函数也不是以0为中心的函数。
尽管存在这两个问题,ReLU目前仍是最常用的activation function,在搭建人工神经网络的时候推荐优先尝试!
def ReLU(x):return x * (x > 0)
tf.nn.relu(features, name=None)
ARGS:
features:A
Tensor。必须是下列类型之一:float32,float64,int32,uint8,int16,int8,int64,bfloat16,uint16,half,uint32,uint64,qint8。
name:操作的名称(可选)。 Returns:一个Tensor,与features具有相同的类型。
4.4指数线性单元(ELU)

x<0时,f(x)=a(exp(x)-1)
优点:
- 能避免死亡 ReLU 问题:x 小于 0 时函数值不再是 0,因此可以避免 dying relu 问题;
- 能得到负值输出,这能帮助网络向正确的方向推动权重和偏置变化。
缺点:
- 计算耗时:包含指数运算;
- α 值是超参数,需要人工设定
4.4 Leaky-ReLU
Leaky-ReLU是Andrew L. Maas等人在2013年《Rectifier Nonlinearities Improve Neural Network Acoustic Models(Leaky ReLU)》论文中提出的一种激活函数。**由于ReLU将所有负数部分的值设为0,从而造成神经元的死亡。而Leaky-ReLU是对负值给与一个非零的斜率,从而避免神经元死亡的情况。**Leaky-ReLU定义如下:

Leaky-ReLU很好的解决了ReLU中神经元死亡的问题。因为Leaky-ReLU保留了 x<0 时的梯度,在 x<0 时,不会出现神经元死亡的问题。总结一下Leaky-ReLU的优缺点。
优点:
- Leaky-ReLU解决了ReLU中神经元死亡的问题
- 由于Leaky-ReLU线性特点,神经网络的计算和训练比sigmoid快很多
缺点:
- Leaky-ReLU中的超参 alpha 需要人工调整
tf.nn.maximum(x,leaky*x,name=None)#leaky为超参
4.5 PReLU(Parametric Rectified Linear Unit),顾名思义:带参数的ReLU
PReLU是Kaiming He等人在2015年《Delving Deep into Rectifiers: Surpassing Human-Level Performance on ImageNet Classification》论文中提出的激活函数。和Leaky-ReLU相比,将 α 变成可训练的参数,不再依赖于人工调整。PReLU的定义如下:

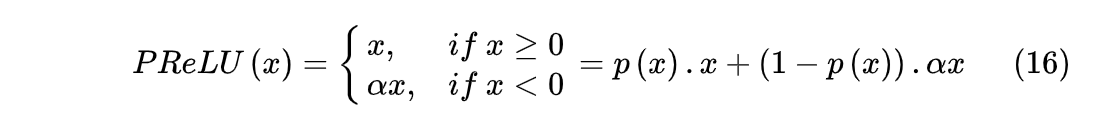
其中 alpha 是可训练的参数。
PReLU的几点说明
(1) PReLU只增加了极少量的参数,也就意味着网络的计算量以及过拟合的危险性都只增加了一点点。特别的,当不同channels使用相同的ai时,参数就更少了。
(2) BP更新ai时,采用的是带动量的更新方式,如下图:
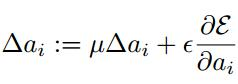
上式的两个系数分别是动量和学习率。
**需要特别注意的是:**更新ai时不施加权重衰减(L2正则化),因为这会把ai很大程度上push到0。事实上,即使不加正则化,试验中ai也很少有超过1的。
(3) 整个论文,ai被初始化为0.25。
TensorFlow学习笔记之 PReLU激活函数原理和代码中的代码与上文论文中的公式不同,仅用于他的模型是可以的,不会过拟合
但出现OOM报错,空间复杂度还是太高了,因此要慎用
优点:
- 与 ReLU 相同。
缺点:
- 在不同问题中,表现不一。
4.6 Dice
Dice是Guorui Zhou等人在2018年《Deep Interest Network for Click-Through Rate Prediction》论文中提出的激活函数。根据 Parametric ReLU 改造而来,ReLU类函数的阶跃变化点再x=0处,意味着面对不同的输入这个变化点是不变的,DIN中改进了这个控制函数,让它根据数据的分布来调整,选择了统计神经元输出的均值和方差(实际上就是Batch_Normalization,CTR中BN操作可是很耗时的,可以推测Dice复杂的计算快不起来不会大规模引用)来描述数据的分布。Dice是对PRelu做了平滑,使得拐点不再是固定的0,而是依赖于数据的分布,定义如下:

深度学习中Batch Normalization和Dice激活函数中提到DICE是BN的一种变换(有具体公式),是解决internal coviriate shift问题的一种方法 ,并提到实际解决问题时要注意BN在训练时和测试时都要启动

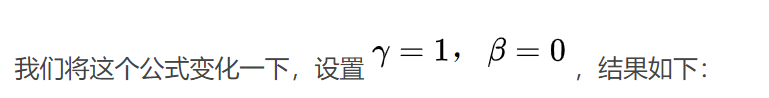

优点:
- 根据数据分布灵活调整阶跃变化点,具有BN的优点(解决Internal Covariate
Shift),原论文称效果好于Parametric ReLU。
缺点:
- 具有BN的缺点,大大加大了计算复杂度。
4.7 RReLU
RReLU(Randomized Leaky ReLU)的首次提出是在Kaggle比赛NDSB中,也是Leaky-ReLU的一个变体。RReLU在训练的过程中,α是从均匀分布 U( u,l ) 中随机选取的,RReLU在训练过程中的定义如下:


4.8Swish

在使用了BN算法情况下,β需要被调节,变为可调节参数,而非固定值
Swish 在深层模型上的效果优于 ReLU。例如,仅仅使用 Swish 单元替换 ReLU 就能把 Mobile NASNetA 在 ImageNet 上的 top-1 分类准确率提高 0.9%,Inception-ResNet-v 的分类准确率提高 0.6%。
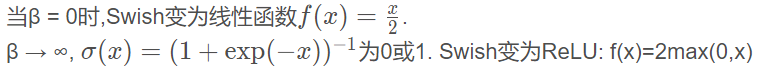
所以Swish函数可以看做是介于线性函数与ReLU函数之间的平滑函数.
def Swish(x,beta=1):return x*tf.nn.sigmoid(beta*x)
4.9SELU


优点:
- SELU 激活能够对神经网络进行自归一化(self-normalizing);
- 不可能出现梯度消失或爆炸问题,论文附录的定理 2 和 3 提供了证明。
缺点:
- 应用较少,需要更多验证;
- lecun_normal 和 Alpha Dropout:需要 lecun_normal 进行权重初始化;如果 dropout,则必须用
Alpha Dropout 的特殊版本。
(三)softmax和maxout
4.10 softmax 多分类
Sigmoid函数只能处理两个类别,这不适用于多分类的问题,所以Softmax可以有效解决这个问题。Softmax函数很多情况都运用在神经网路中的最后一层网络中,使得每一个类别的概率值在(0, 1)之间。
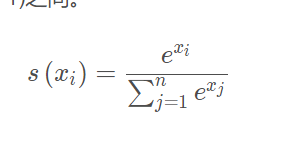
def softmax(x):
return np.exp(x) / sum(np.exp(x))
4.11 maxout(不能算作传统意义的激活函数,是一种网络选择器)
可以理解为单个神经元的扩展,主要是扩展单个神经元里面的激活函数, 将激活函数变成一个网络选择器,原理就是将多个神经元并列地放在一起,从他们的输出结果中找到最大的那个,代表对特征响应最敏感,然后取这个神经元的结果参与后面的运算

优点:
- Maxout 神经元拥有 ReLU 单元的所有优点(线性和不饱和),而没有它的缺点(死亡的 ReLU 单元)
缺点:
- 和 ReLU 对比,它每个神经元的参数数量增加了一倍,这就导致整体参数的数量激增。
五、总结
从最初的sigmoid到后面的Leaky ReLU、PReLU,再到近期的SELUs、GELUs,激活函数的改进从来没有中断过。激活函数不仅解决了深层神经网络的梯度消失和爆炸问题,同时对于模型的拟合能力和收敛速度起着至关重要的重用。因此了解激活函数的相关原理还是非常有必要的。
参考:
深度学习中激活函数总结
深度学习——PReLU激活
整理Sigmoid~Dice常见激活函数,从原理到实现