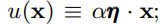文章目录
- 引言
- 什么是激活函数?
- 为什么我们要在神经网络中使用激活函数?
- 线性激活函数
- 非线性激活函数
- 1. Sigmoid(逻辑激活函数)
- 2. Tanh(双曲正切激活函数)
- 3. ReLU(线性整流单元)激活函数
- 4. Leaky ReLU
- 为什么使用导数/微分
- 参考
引言
本文是对《Activation Functions in Neural Networks》(神经网络中的激活函数)一文的翻译。
什么是激活函数?
它只是一个用来获取节点输出的函数,也常被称为传递函数。
为什么我们要在神经网络中使用激活函数?
激活函数被用来确定神经网络的输出,如 YES 或 NO 。它将结果值映射到 0 到 1 或 -1 到 1 等之间(视函数而定)。
激活函数基本上可以分为两种类型:
- 线性激活函数(Linear Activation Function)
- 非线性激活函数(Non-linear Activation Function)
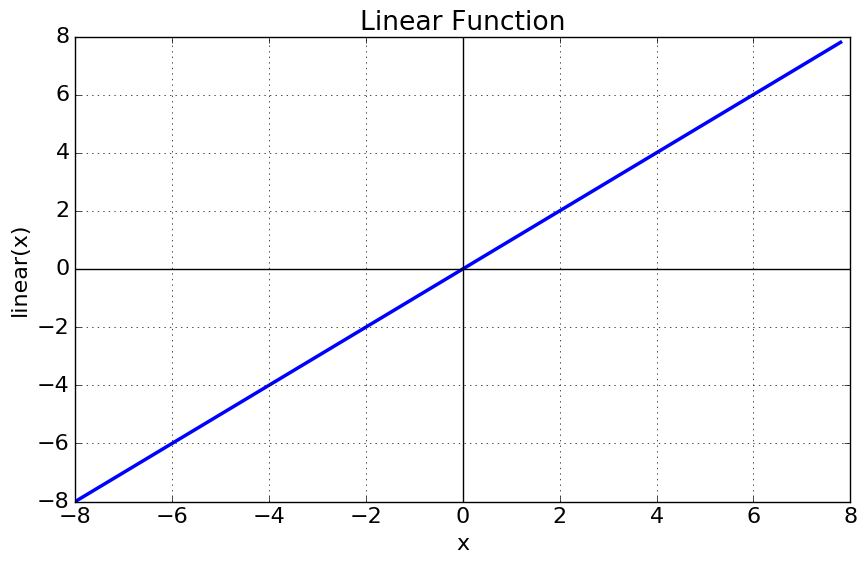
线性激活函数
如下图,函数是直线或线性的。因此,函数的输出不会被限制在任何范围内。
-
方程: f ( x ) = x f(x)=x f(x)=x
-
范围: ( − ∞ , + ∞ ) (-\infty, +\infty) (−∞,+∞)
它对输入神经网络的数据的复杂性或各种参数没有帮助。
非线性激活函数
非线性激活函数是使用最多的激活函数。非线性有助于使图看起来像下面这样:

它使得模型可以很容易地泛化或适应各种数据,并区分输出。
导数或微分:y轴相对于x轴的变化,它也被称为斜率。
单调函数:一种函数,它要么是完全不增的,要么是完全不减的。
非线性激活函数主要根据其范围或曲线进行划分:
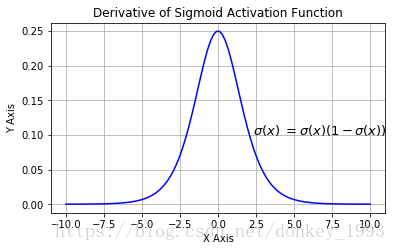
1. Sigmoid(逻辑激活函数)
Sigmoid 激活函数曲线看起来像一个 S 形。我们使用 Sigmoid 函数的主要原因是它存在于 (0, 1) 之间。因此,它特别适用于我们必须将概率作为输出进行预测的模型。因为任何事物的概率都只存在于 0 和 1 之间,所以 Sigmoid 是正确的选择。

-
这个函数是可微的,也就是说,我们可以求出 S 型曲线上任意两点的斜率。
-
函数是单调的,但函数的导数不是单调的。
-
逻辑 Sigmoid 函数会导致神经网络在训练时陷入停滞。
-
Softmax 函数是一种用于多分类的更广义的逻辑激活函数。
2. Tanh(双曲正切激活函数)
Tanh 和逻辑 Sigmoid 类似,但更好。Tanh 函数的范围是从(-1, 1)。Tanh 也是 S 形的。

-
优点是负输入将被映射为强负值,而零输入将被映射到在 Tanh 图中接近 0 的位置。
-
这个函数是可微的。
-
函数是单调的,但函数的导数不是单调的。
-
Tanh 函数主要用于二分类问题。
Tanh 和逻辑 Sigmoid 激活函数都用于前馈网络。
3. ReLU(线性整流单元)激活函数
ReLU 是目前世界上使用最多的激活函数,几乎所有的卷积神经网络或深度学习都使用它。正如你所看到的,ReLU 被修正了一半(从底部开始)。 当 z 小于零时,f(z) 为零,当 z 大于或等于零时 f(z) 等于 z。

-
范围: ( 0 , + ∞ ) (0, +\infty) (0,+∞)
-
函数及其导数都是单调的。
但问题是,所有的负值都立即变为零,这降低了模型正确拟合或训练数据的能力。这意味着给 ReLU 激活函数的任何负输入都将立即将值转换为零,这反过来通过不适当地映射负值来影响产生的图。
4. Leaky ReLU
这是解决濒临死亡的ReLU问题的一次尝试。

相比于ReLU,你能看到 leak 吗?
-
Leak 有助于增加 ReLU 函数的范围。通常,a 的值是 0.01 左右。
-
当 a 不是 0.01 时,则称其为随机 ReLU。
-
因此,Leaky ReLU 的范围是 ( − ∞ , + ∞ ) (-\infty, +\infty) (−∞,+∞)。
-
Leaky ReLU 函数和随机 ReLU 函数都是单调的,并且它们的导数本质上也是单调的。
为什么使用导数/微分
当更新曲线时,根据斜率才能知道向哪个方向改变以及改变或更新曲线的程度。这就是为什么我们在机器学习和深度学习的几乎每一个部分都使用微分的原因。


参考
https://en.wikipedia.org/wiki/Activation_function