原创声明:本文为 SIGAI 原创文章,仅供个人学习使用,未经允许,不能用于商业目的。
其它机器学习、深度学习算法的全面系统讲解可以阅读《机器学习-原理、算法与应用》,清华大学出版社,雷明著,由SIGAI公众号作者倾力打造。
- 书的购买链接
- 书的勘误,优化,源代码资源
导言
牛顿法是数值优化算法中的大家族,她和她的改进型在很多实际问题中得到了应用。在机器学习中,牛顿法是和梯度下降法地位相当的的主要优化算法。在本文中,SIGAI将为大家深入浅出的系统讲述牛顿法的原理与应用。
牛顿法的起源
牛顿法以伟大的英国科学家牛顿命名,牛顿不仅是伟大的物理学家,是近代物理的奠基人,还是伟大的数学家,他和德国数学家莱布尼兹并列发明了微积分,这是数学历史上最有划时代意义的成果之一,奠定了近代和现代数学的基石。在数学中,也有很多以牛顿命名的公式和定理,牛顿法就是其中之一。
牛顿法不仅可以用来求解函数的极值问题,还可以用来求解方程的根,二者在本质上是一个问题,因为求解函数极值的思路是寻找导数为0的点,这就是求解方程。在本文中,我们介绍的是求解函数极值的牛顿法。
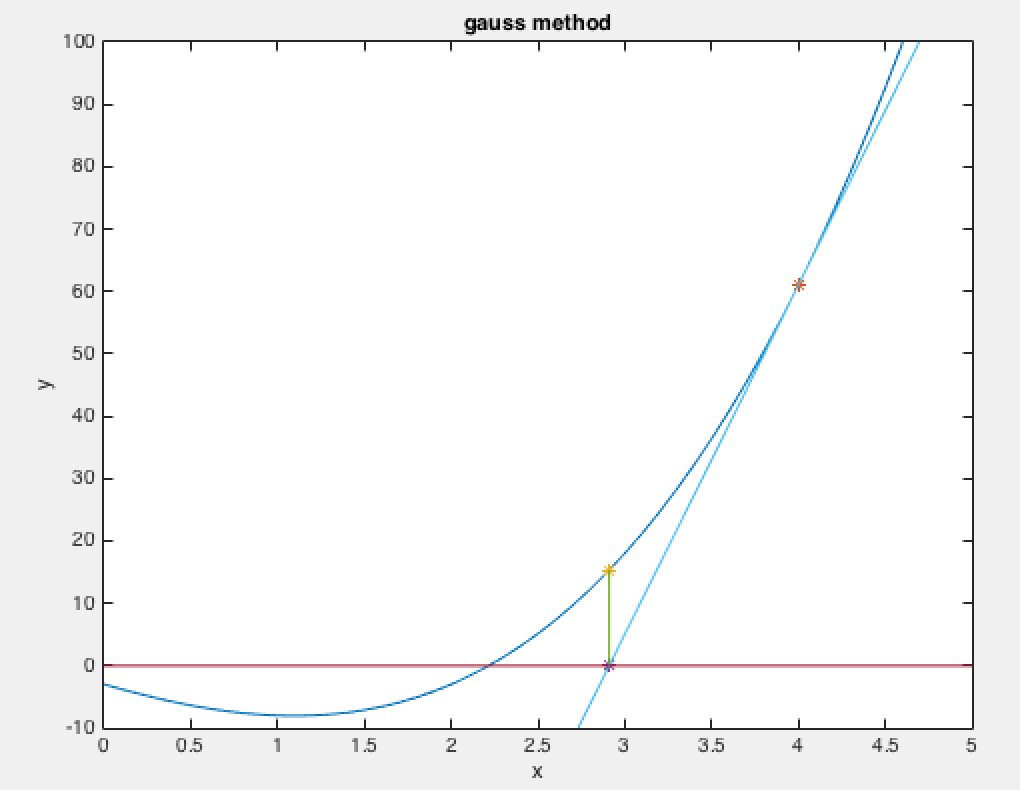
在SIGAI之前关于最优方法的系列文章“理解梯度下降法”,“理解凸优化”中,我们介绍了最优化的基本概念和原理,以及迭代法的思想,如果对这些概念还不清楚,请先阅读这两篇文章。和梯度下降法一样,牛顿法也是寻找导数为0的点,同样是一种迭代法。核心思想是在某点处用二次函数来近似目标函数,得到导数为0的方程,求解该方程,得到下一个迭代点。因为是用二次函数近似,因此可能会有误差,需要反复这样迭代,直到到达导数为0的点处。下面我们开始具体的推导,先考虑一元函数的情况,然后推广到多元函数。
一元函数的情况
为了能让大家更好的理解推导过程的原理,首先考虑一元函数的情况。根据一元函数的泰勒展开公式,我们对目标函数在x0点处做泰勒展开,有:
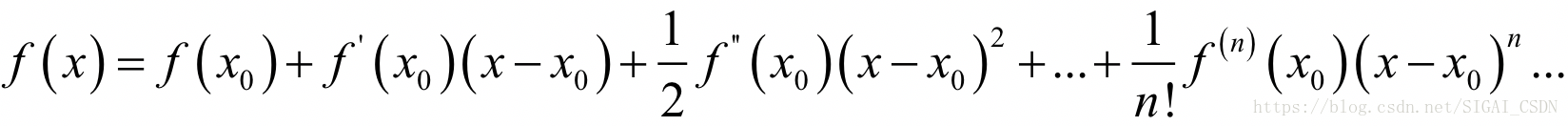
如果忽略2次以上的项,则有:
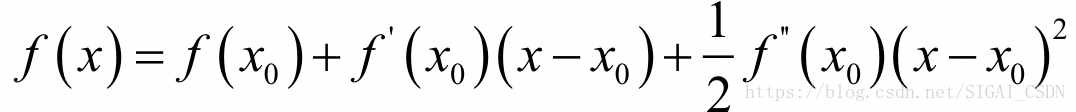
现在我们在x0点处,要以它为基础,找到导数为0的点,即导数为0。对上面等式两边同时求导,并令导数为0,可以得到下面的方程:
可以解得:
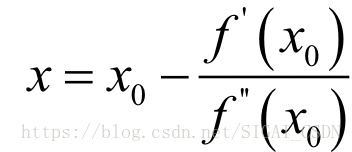
这样我们就得到了下一点的位置,从而走到x1。接下来重复这个过程,直到到达导数为0的点,由此得到牛顿法的迭代公式:
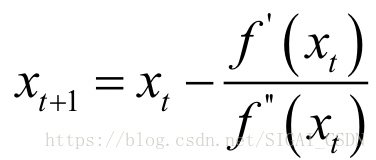
给定初始迭代点x0,反复用上面的公式进行迭代,直到达到导数为0的点或者达到最大迭代次数。
多元函数的情况
下面推广到多元函数的情况,如果读者对梯度,Hessian的概念还不清楚,请先去看微积分教材,或者阅读SIGAI之前关于最优化的公众号文章。根据多元函数的泰勒展开公式,我们对目标函数在x0点处做泰勒展开,有:
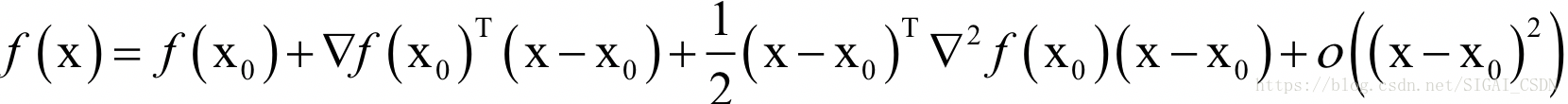
忽略二次及以上的项,并对上式两边同时求梯度,得到函数的导数(梯度向量)为:
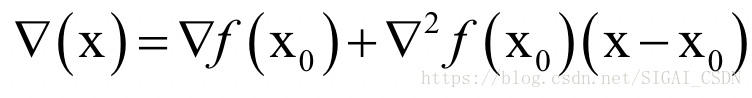
其中即为Hessian矩阵,在后面我们写成H。令函数的梯度为0,则有:
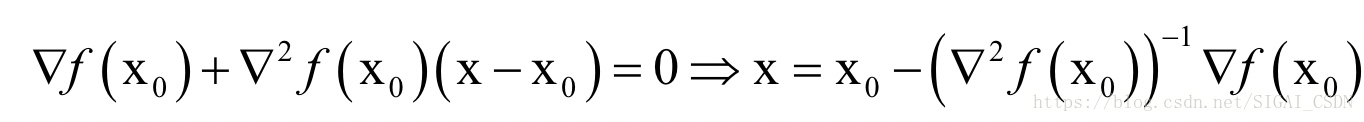
这是一个线性方程组的解。如果将梯度向量简写为g,上面的公式可以简写为:
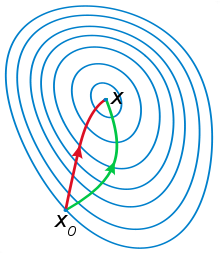
从初始点x0处开始,反复计算函数在处的Hessian矩阵和梯度向量,然后用下述公式进行迭代:
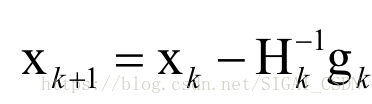
最终会到达函数的驻点处。其中