《牛顿法》
牛顿法(Newton method)和拟牛顿法(quasi Newton method)是求解无约束最优化问题的常用方法,有收敛速度快的优点。牛顿法是迭代算法,每一步都需求解目标函数的海塞矩阵(Hessian Matrix),计算比较复杂。拟牛顿法通过正定矩阵近似海塞矩阵的逆矩阵或海塞矩阵,简化了这一计算过程。
Key Words:牛顿法、函数零点、最优化
Beijing, 2020
作者:RaySue
Code:
Agile Pioneer
简介
牛顿迭代法(Newton’s method)是牛顿在17世纪提出的一种在实数域和复数域上近似求解方程的方法。
连续可微的方程多数不存在求根公式,因此求精确根非常困难,甚至不可解,从而寻找方程的近似根就显得特别重要。牛顿法使用函数 f ( x ) f(x) f(x) 的泰勒级数的前面几项来迭代寻找方程 f ( x ) = 0 f(x) = 0 f(x)=0 的根。
f(x)在 x 0 x_0 x0处的泰勒展开式:
f ( x ) = f ( x 0 ) + f ′ ( x 0 ) ( x − x 0 ) + 1 2 f ′ ′ ( x 0 ) ( x − x 0 ) 2 + . . . + 1 n ! f ( n ) ( x 0 ) ( x − x 0 ) n + R n ( x ) f(x) = f(x_0) + f'(x_0)(x - x_0) + \frac{1}{2} f^{''}(x_0)(x - x_0)^2 + ... + \frac{1}{n!}f^{(n)}(x_0)(x - x_0)^n + R_n(x) f(x)=f(x0)+f′(x0)(x−x0)+21f′′(x0)(x−x0)2+...+n!1f(n)(x0)(x−x0)n+Rn(x)
牛顿迭代法是求方程根的重要方法之一,其最大优点是在方程 f ( x ) = 0 f(x) = 0 f(x)=0 的单根附近平方收敛,而且该法还可以用来求方程的重根、复根,此时线性收敛,也可通过一些方法变成超线性收敛,该方法广泛用于计算机编程中。
牛顿法的应用场景
求解函数零点问题(方程的根)
在原函数的某一点处用一个一次函数近似原函数,然后用这个一次函数的零点作为原函数的下一个迭代点。
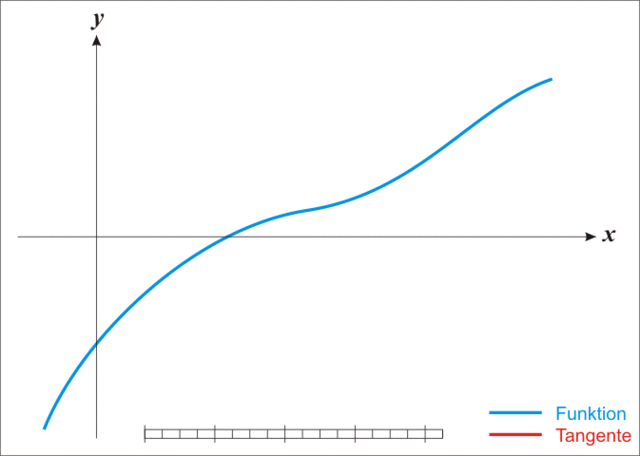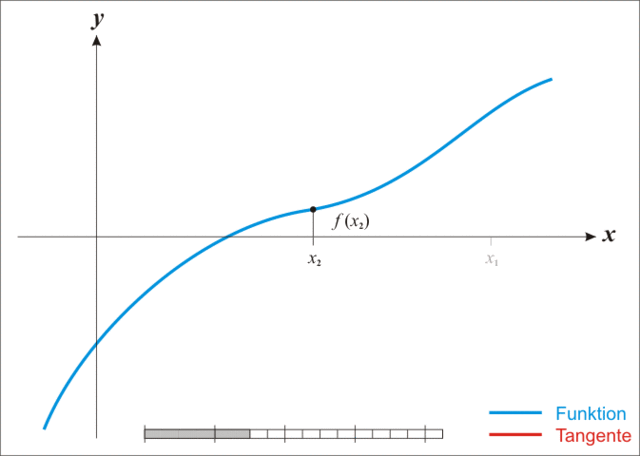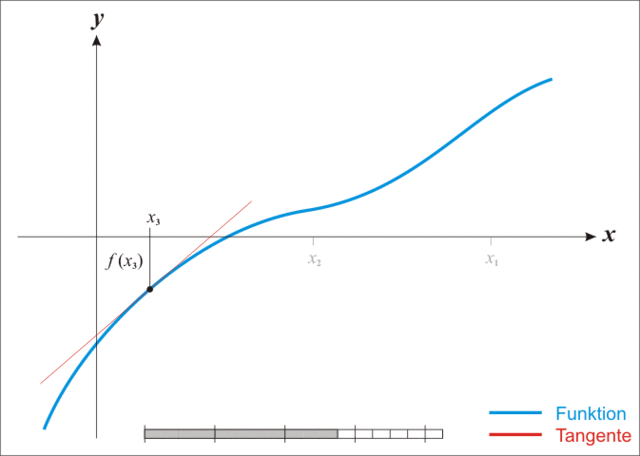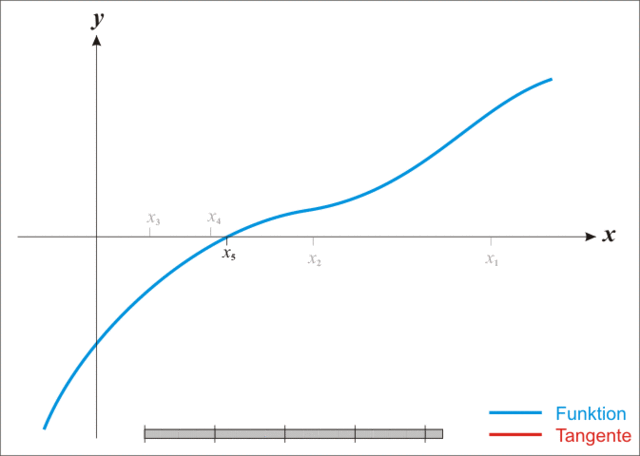
上面的动图生动的诠释了利用牛顿法进行方程根求解的过程,所以该方法也称为“切线法”
例如:利用牛顿法求解 f ( x ) = x 2 − C f(x) = x^2 - C f(x)=x2−C (x > 0) 的根
等同于求 x \sqrt{x} x ,步骤如下:
-
先对 f ( x ) f(x) f(x)在 x k x_k xk处进行一阶泰勒展开为 f ( x ) = f ( x k ) + f ′ ( x k ) ( x − x k ) f(x) = f(x_k) + f'(x_k)(x - x_k) f(x)=f(xk)+f′(xk)(x−xk)
-
求根问题就变为了 f ( x k ) + f ′ ( x k ) ( x − x k ) = 0 f(x_k) + f'(x_k)(x - x_k) = 0 f(xk)+f′(xk)(x−xk)=0 即 x = x k − f ( x k ) f ′ ( x k ) x = x_k -\frac{f(x_k)}{f'(x_k)} x=xk−f′(xk)f(xk)
-
迭代式为 x k + 1 = x k − f ( x k ) f ′ ( x k ) x_{k + 1} = x_k -\frac{f(x_k)}{f'(x_k)} xk+1=xk−f′(xk)f(xk)
-
当 x k x_k xk 与 x k + 1 x_{k+1} xk+1的距离足够近的时候( fabs( x k x_k xk - x k + 1 x_{k+1} xk+1) < 1e-7 ),我们可以认为迭代完成
double E = 1E-7;
double C = x;
double x0 = x;
while(true)
{double x1 = 0.5 * (x0 + C / x0)if (fabs(x1 - x0) < E)break;x0 = x1;
}
return x1;

所以诸如此类求零点问题都可以使用牛顿法来解决,而且牛顿法是二阶收敛的,速度比二分法要快很多。
求解最优化问题
对于无约束的最优化问题 m i n f ( x ) min \space f(x) min f(x), 可根据极小点的必要条件 ∇ f ( x ) = 0 \nabla f(x) = 0 ∇f(x)=0采用牛顿法求解,以一元函数为例:
-
先对函数进行二阶泰勒展开 f ( x k + 1 ) = f ( x k ) + f ′ ( x k ) ( x k + 1 − x k ) + f ′ ′ ( x k ) ( x k + 1 − x k ) 2 + . . . + R n ( x k ) f(x_{k + 1}) = f(x_k) + f'(x_k)(x_{k + 1} - x_k) + f^{''}(x_k)(x_{k + 1} - x_k)^2 + ... + R_n(x_k) f(xk+1)=f(xk)+f′(xk)(xk+1−xk)+f′′(xk)(xk+1−xk)2+...+Rn(xk)
-
f ′ ( x k + 1 ) = f ′ ( x k ) + f ′ ′ ( x k ) ( x k + 1 − x k ) = 0 f'(x_{k+1}) = f'(x_k) + f^{''}(x_k)(x_{k+1} - x_k) = 0 f′(xk+1)=f′(xk)+f′′(xk)(xk+1−xk)=0
-
x k + 1 = x k − f ′ ( x k ) f ′ ′ ( x k ) x_{k+1} = x_k - \frac{f'(x_k)}{f^{''}(x_k)} xk+1=xk−f′′(xk)f′(xk)
-
开始迭代
在原函数的某一点处用一个二次函数近似原函数,然后用这个二次函数的极小值点作为原函数的下一个迭代点。
当目标函数是二次函数时,海塞矩阵退化成一个常数矩阵,从任一初始点出发,牛顿法可一步到达,因此它是一种具有二次收敛性的算法。
若原函数本身就是一个二次正定函数,则牛顿法一步到达最小值点。
对于非二次函数,若函数的二次形态较强,或迭代点已进入极小点的邻域,则其收敛速度也是很快的,这是牛顿法的主要优点。
例如:利用牛顿法求解 f ( x ) = x 2 + 2 x f(x) = x^2 + 2x f(x)=x2+2x 的最小值
对于二次函数而言,极值也是最值,极值点的x值也是我们上学时候必须记住的 x = − b 2 a x = -\frac{b}{2a} x=−2ab,此题而言 x = − 1 x = -1 x=−1 取得最优解,下式是牛顿法的迭代公式,你可以代入任何的 x k x_k xk值进去,你会发现得到的结果都是 -1,即二次函数,一次迭代即达到最小值点。
x k + 1 = x k − f ′ ( x k ) f ′ ′ ( x k ) x_{k+1} = x_k - \frac{f'(x_k)}{f^{''}(x_k)} xk+1=xk−f′′(xk)f′(xk)
多元函数使用牛顿法
相比于一元函数来说,多元函数的泰勒展开式相对更加复杂,而且二阶导数组成了Hessian矩阵。
Hessian 矩阵
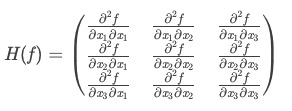
f ( x , y , z ) = 2 x 2 − x y + y 2 − 3 z 2 f(x,y,z) = 2x^2 - xy + y^2 - 3z^2 f(x,y,z)=2x2−xy+y2−3z2 的Hessian矩阵如下:
( 4 − 1 0 − 1 2 0 0 0 − 6 ) \left( \begin{matrix} 4 & -1 & 0 \\ -1 & 2 & 0 \\ 0 & 0 & -6 \end{matrix} \right) ⎝⎛4−10−12000−6⎠⎞
Hessian矩阵的作用:
与多元函数的凹凸性由密切的关系。
如果Hessian矩阵正定,则f(x,y,z)是凸函数
如果Hessian矩阵负定,则f(x,y,z)是凹函数
一元函数的极值判别法:
- f ’ ( x ) = 0 f ’ ’ ( x ) > 0 f’(x)=0 \space\space\space\space f’’(x)>0 f’(x)=0 f’’(x)>0 极小值
- f ’ ( x ) = 0 f ’ ’ ( x ) < 0 f’(x)=0 \space\space\space\space f’’(x)<0 f’(x)=0 f’’(x)<0 极大值
- f ’ ( x ) = 0 f ’ ’ ( x ) = 0 f’(x)=0 \space\space\space\space f’’(x)=0 f’(x)=0 f’’(x)=0 无法判断
多元函数的极值判别法:
- ∇ f = 0 \nabla f = 0 ∇f=0,Hessian矩阵正定,极小值点
- ∇ f = 0 \nabla f=0 ∇f=0 ,Hessian矩阵负定,极大值点
- ∇ f = 0 \nabla f=0 ∇f=0 ,Hessian矩阵不定,还需要看更高阶的导数
求解步骤
由一维的牛顿公式推广到多维的公式如下:
x k + 1 = x k − H k − 1 ∇ f ( x k ) x_{k+1} = x_k - H^{-1}_k \nabla f(x_k) xk+1=xk−Hk−1∇f(xk)
其中 H ( x ) H(x) H(x)是 f ( x ) f(x) f(x)的Hessian矩阵。
- 取初始点 x 0 x_0 x0
- 计算 ∇ f ( x k ) \nabla f(x_k) ∇f(xk) 如果此时梯度为0则停止计算
- 计算 H k H_k Hk 令 x k + 1 = x k − H k − 1 ∇ f ( x k ) x_{k+1} = x_k - H^{-1}_k \nabla f(x_k) xk+1=xk−Hk−1∇f(xk)
- k = k + 1 执行 2 步
牛顿法&梯度下降法
红色线代表牛顿法,绿色线代表梯度下降法,一般认为牛顿法可以利用到曲线本身的信息,比梯度下降法更容易收敛(迭代更少次数)。
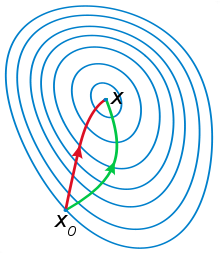
根据wiki上的解释,从几何上说,牛顿法就是用一个二次曲面去拟合你当前所处位置的局部曲面,而梯度下降法是用一个平面去拟合当前的局部曲面,通常情况下,二次曲面的拟合会比平面更好,所以牛顿法选择的下降路径会更符合真实的最优下降路径。
对一个n阶可导的函数而言,在某点处进行泰勒展开,展开式保留的次数越多,在以改点为区间内与曲线贴合程度就越好,相应的也就计算量更多,但是对更远位置的把控就更准确。
思考
Q1: 为什么深度学习不采用牛顿法或拟牛顿法作为优化算法?
A1:
-
原因一:牛顿法需要用到梯度和Hessian矩阵,这两个都难以求解。因为很难写出深度神经网络拟合函数的表达式,遑论直接得到其梯度表达式,更不要说得到基于梯度的Hessian矩阵了。
-
原因二:即使可以得到梯度和Hessian矩阵,当输入向量的维度N较大时,Hessian矩阵的大小是N×N,所需要的内存非常大。
-
原因三:在高维非凸优化问题中,鞍点相对于局部最小值的数量非常多,而且鞍点处的损失值相对于局部最小值处也比较大。而二阶优化算法是寻找梯度为0的点,所以很容易陷入鞍点。
Q2: 牛顿法优缺点:
A2:
-
优点:
- 收敛速度快,牛顿法收敛速度为二阶,对于正定二次函数一步迭代即达最优解。
-
缺点:
-
牛顿法是一种迭代算法,每一步都需要求解目标函数的Hessian矩阵的逆矩阵,计算比较复杂。
-
牛顿法是局部收敛的,当初始点选择不当时,往往导致不收敛,感兴趣的可以了解一下阻尼牛顿法。
-
Hessian矩阵不一定可逆
-
Q3: 梯度下降法优缺点:
A3:
-
优点:
- 当目标函数是凸函数时,梯度下降法的解是全局解
-
缺点:
-
靠近极小值时收敛速度减慢,求解需要很多次的迭代;
-
直线搜索时可能会产生一些问题;
-
可能会“之字形”地下降。
-
鞍点
-
参考
https://zhuanlan.zhihu.com/p/46536960
https://blog.csdn.net/michaelhan3/article/details/82350047
https://blog.csdn.net/robert_chen1988/article/details/53137997
https://www.cnblogs.com/eilearn/p/9036776.html
https://blog.csdn.net/weixin_44264662/article/details/99866159